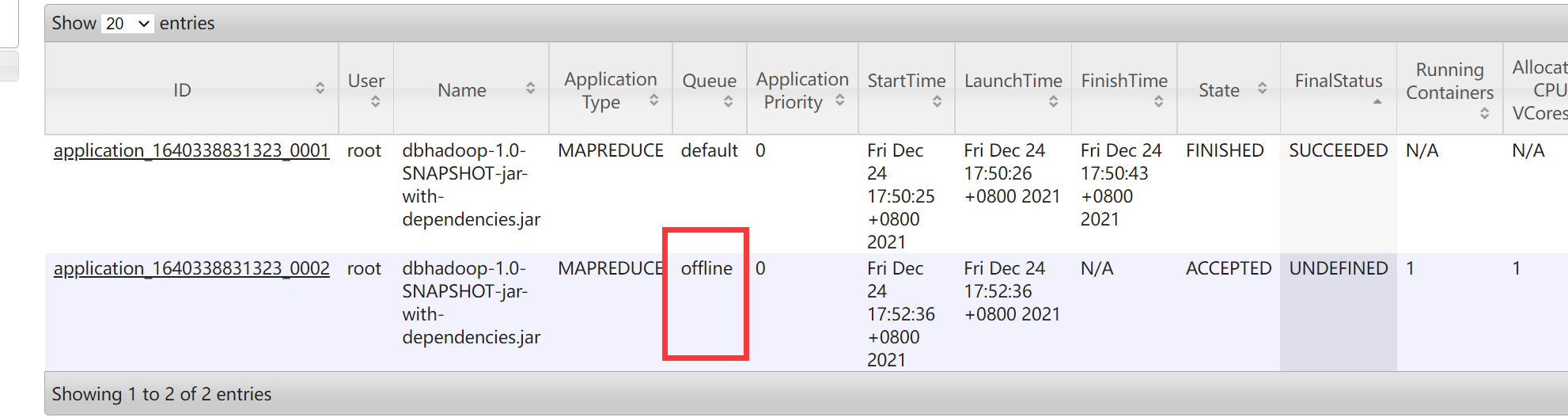
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
| package tipdm.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
public class WordCountJobQueue {
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
Logger logger = LoggerFactory.getLogger(MyMapper.class);
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
logger.info("<k1, v1> = <" + k1.get() + "," + v1.toString() + ">");
String[] words = v1.toString().split(" ");
for (String word : words){
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
context.write(k2, v2);
}
}
}
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
Logger logger = LoggerFactory.getLogger(MyMapper.class);
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context)
throws IOException, InterruptedException {
long sum = 0L;
for (LongWritable v2: v2s){
logger.info("<k2, v2> = <" + k2.toString() + "," + v2.get() + ">");
sum += v2.get();
}
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
logger.info("<k3, v3> = <" + k3.toString() + "," + v3.get() + ">");
context.write(k3, v3);
}
}
public static void main(String[] args) {
try{
Configuration conf = new Configuration();
String[] remainingArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountJobQueue.class);
FileInputFormat.setInputPaths(job, new Path(remainingArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(remainingArgs[1]));
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.waitForCompletion(true);
} catch (Exception e){
e.printStackTrace();
}
}
}
|