上⼀章我们介绍了卷积神经⽹络的基本原理,本章我们将带你了解现代的卷积神经⽹络架构,许多现代卷积神经⽹络的研究都是建⽴在这⼀章的基础上的。在本章中的每⼀个模型都曾⼀度占据主导地位,其中许多模型都是ImageNet竞赛的优胜者。ImageNet竞赛⾃2010年以来,⼀直是计算机视觉中监督学习进展的指向标。
AlexNet。它是第⼀个在⼤规模视觉竞赛中击败传统计算机视觉模型的⼤型神经⽹络;
使用重复块的⽹络(VGG)。它利⽤许多重复的神经⽹络块;
⽹络中的⽹络(NiN)。它重复使⽤由卷积层和1 × 1卷积层(⽤来代替全连接层)来构建深层⽹络;
含并⾏连结的⽹络(GoogLeNet)。它使⽤并⾏连结的⽹络,通过不同窗⼝⼤⼩的卷积层和最⼤汇聚层来并⾏抽取信息;
残差⽹络(ResNet)。它通过残差块构建跨层的数据通道,是计算机视觉中最流⾏的体系架构;
稠密连接⽹络(DenseNet)。它的计算成本很⾼,但给我们带来了更好的效果。
虽然深度神经⽹络的概念⾮常简单——将神经⽹络堆叠在⼀起。但由于不同的⽹络架构和超参数选择,这些神经⽹络的性能会发⽣很⼤变化。本章介绍的神经⽹络是将⼈类直觉和相关数学⻅解结合后,经过⼤量研究试错后的结晶。我们会按时间顺序介绍这些模型,在追寻历史的脉络的同时,帮助你培养对该领域发展的直觉。这将有助于你研究开发⾃⼰的架构。
例如,本章介绍的批量规范化(batch normalization)和残差⽹络(ResNet)为设计和训练深度神经⽹络提供了重要思想指导。
深度卷积神经网络(AlexNet)
在LeNet提出后,卷积神经⽹络在计算机视觉和机器学习领域中很有名⽓。但卷积神经⽹络并没有主导这些领域。这是因为虽然LeNet在⼩数据集上取得了很好的效果,但是在更⼤、更真实的数据集上训练卷积神经⽹络的性能和可⾏性还有待研究。事实上,在上世纪90年代初到2012年之间的⼤部分时间⾥,神经⽹络往往被其他机器学习⽅法超越,如⽀持向量机(support vector machines)。
在计算机视觉中,直接将神经⽹络与其他机器学习⽅法进⾏⽐较也许不公平。这是因为,卷积神经⽹络的输⼊是由原始像素值或是经过简单预处理(例如居中、缩放)的像素值组成的。但在使⽤传统机器学习⽅法时,从业者永远不会将原始像素作为输⼊。在传统机器学习⽅法中,计算机视觉流⽔线是由经过⼈的手工精心设计的特征流⽔线组成的。对于这些传统⽅法,⼤部分的进展都来⾃于对特征有了更聪明的想法,并且学习到的算法往往归于事后的解释。
虽然上世纪90年代就有了⼀些神经⽹络加速卡,但仅靠它们还不⾜以开发出有⼤量参数的深层多通道多层卷积神经⽹络。此外,当时的数据集仍然相对较⼩。除了这些障碍,训练神经⽹络的⼀些关键技巧仍然缺失,包括启发式参数初始化、随机梯度下降的变体、⾮挤压激活函数和有效的正则化技术。
因此,与训练端到端(从像素到分类结果)系统不同,经典机器学习的流⽔线看起来更像下⾯这样:
- 获取⼀个有趣的数据集。在早期,收集这些数据集需要昂贵的传感器(在当时最先进的图像也就100万像素)。
- 根据光学、⼏何学、其他知识以及偶然的发现,⼿⼯对特征数据集进⾏预处理。
- 通过标准的特征提取算法,如SIFT(尺度不变特征变换)[Lowe, 2004]和SURF(加速鲁棒特征)[Bay et al., 2006]或其他⼿动调整的流⽔线来输⼊数据。
- 将提取的特征送⼊最喜欢的分类器中(例如线性模型或其它核⽅法),以训练分类器。
学习表征
另⼀种预测这个领域发展的⽅法————观察图像特征的提取⽅法。在2012年前,图像特征都是机械地计算出来的。事实上,设计⼀套新的特征函数、改进结果,并撰写论⽂是盛极⼀时的潮流。SIFT [Lowe, 2004]、SURF[Bay et al., 2006]、HOG(定向梯度直⽅图)[Dalal & Triggs, 2005]、bags of visual words 89 和类似的特征提取⽅法占据了主导地位。
另⼀组研究⼈员,包括Yann LeCun、Geoff Hinton、Yoshua Bengio、Andrew Ng、Shun ichi Amari和Juergen Schmidhuber,想法则与众不同:他们认为特征本⾝应该被学习。此外,他们还认为,在合理地复杂性前提下,特征应该由多个共同学习的神经⽹络层组成,每个层都有可学习的参数。在机器视觉中,最底层可能检测边缘、颜⾊和纹理。事实上,Alex Krizhevsky、Ilya Sutskever和Geoff Hinton提出了⼀种新的卷积神经⽹络变体AlexNet。在2012年ImageNet挑战赛中取得了轰动⼀时的成绩。AlexNet以Alex Krizhevsky的名字命名,他是论⽂ [Krizhevsky et al., 2012]的第⼀作者。
有趣的是,在⽹络的最底层,模型学习到了⼀些类似于传统滤波器的特征抽取器。下图是从AlexNet论⽂[Krizhevsky et al., 2012]复制的,描述了底层图像特征。

AlexNet的更⾼层建⽴在这些底层表⽰的基础上,以表⽰更⼤的特征,如眼睛、⿐⼦、草叶等等。⽽更⾼的层可以检测整个物体,如⼈、⻜机、狗或⻜盘。最终的隐藏神经元可以学习图像的综合表⽰,从⽽使属于不同类别的数据易于区分。尽管⼀直有⼀群执着的研究者不断钻研,试图学习视觉数据的逐级表征,然⽽很⻓⼀段时间⾥这些尝试都未有突破。深度卷积神经⽹络的突破出现在2012年。突破可归因于两个关键因素。
- 缺少的成分:数据
- 缺少的成分:硬件
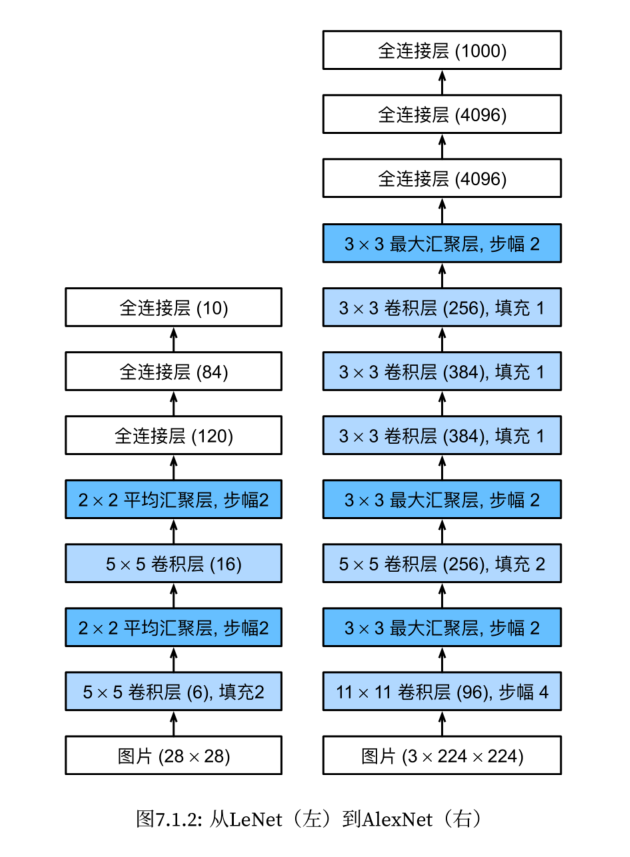
AlexNet
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。
- AlexNet网络更为复杂,由8层组成:5个卷积层、两个全连接隐藏层和一个全连接输出层。
- AlexNet使用的激活函数为ReLU。⼀⽅⾯,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。另⼀⽅⾯,当使⽤不同的参数初始化⽅法时,ReLU激活函数使训练模型更加容易。
- AlexNet通过暂退法控制全连接层模型复杂度。
- 做了图像增强操作,使得模型更健壮,更大的样本量也有效的减少了过拟合。
1 | import torch |
1 | net = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), |
1 | # 查看每层的尺寸 |
Conv2d output shape: torch.Size([1, 96, 54, 54])
ReLU output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Conv2d output shape: torch.Size([1, 256, 26, 26])
ReLU output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 256, 12, 12])
ReLU output shape: torch.Size([1, 256, 12, 12])
MaxPool2d output shape: torch.Size([1, 256, 5, 5])
Flatten output shape: torch.Size([1, 6400])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
读取数据集
1 | batch_size = 128 |
训练AlexNet
1 | lr, num_epochs = 0.01, 10 |
loss 0.327, train acc 0.880, test acc 0.882
1964.0 examples/sec on cuda

使用块的网络(VGG)
虽然AlexNet证明深层神经⽹络卓有成效,但它没有提供⼀个通⽤的模板来指导后续的研究⼈员设计新的⽹络。
使⽤块的想法⾸先出现在⽜津⼤学的视觉⼏何组(visual geometry group)的VGG⽹络中。通过使⽤循环和⼦程序,可以很容易地在任何现代深度学习框架的代码中实现这些重复的架构。
VGG块
经典卷积神经⽹络的基本组成部分是下⾯的这个序列:
- 带填充以保持分辨率的卷积层
- 非线性激活函数,如:relu
- 汇聚层,如最大汇聚层
⽽⼀个VGG块与之类似,由⼀系列卷积层组成,后⾯再加上⽤于空间下采样的最⼤汇聚层。在最初的VGG论⽂中[Simonyan & Zisserman, 2014],作者使⽤了带有3 × 3卷积核、填充为1(保持⾼度和宽度)的卷积层,和带有2 × 2汇聚窗⼝、步幅为2(每个块后的分辨率减半)的最⼤汇聚层。在下⾯的代码中,我们定义了⼀个名为vgg_block的函数来实现⼀个VGG块。
该函数有三个参数,分别对应于卷积层的数量num_convs、输⼊通道的数量in_channels 和输出通道的数量out_channels.
1 | import torch |
1 | def vgg_block(num_convs, in_channels, out_channels): |
VGG网络
与AlexNet、LeNet⼀样,VGG⽹络可以分为两部分:第⼀部分主要由卷积层和汇聚层组成,第⼆部分由全连接层组成。
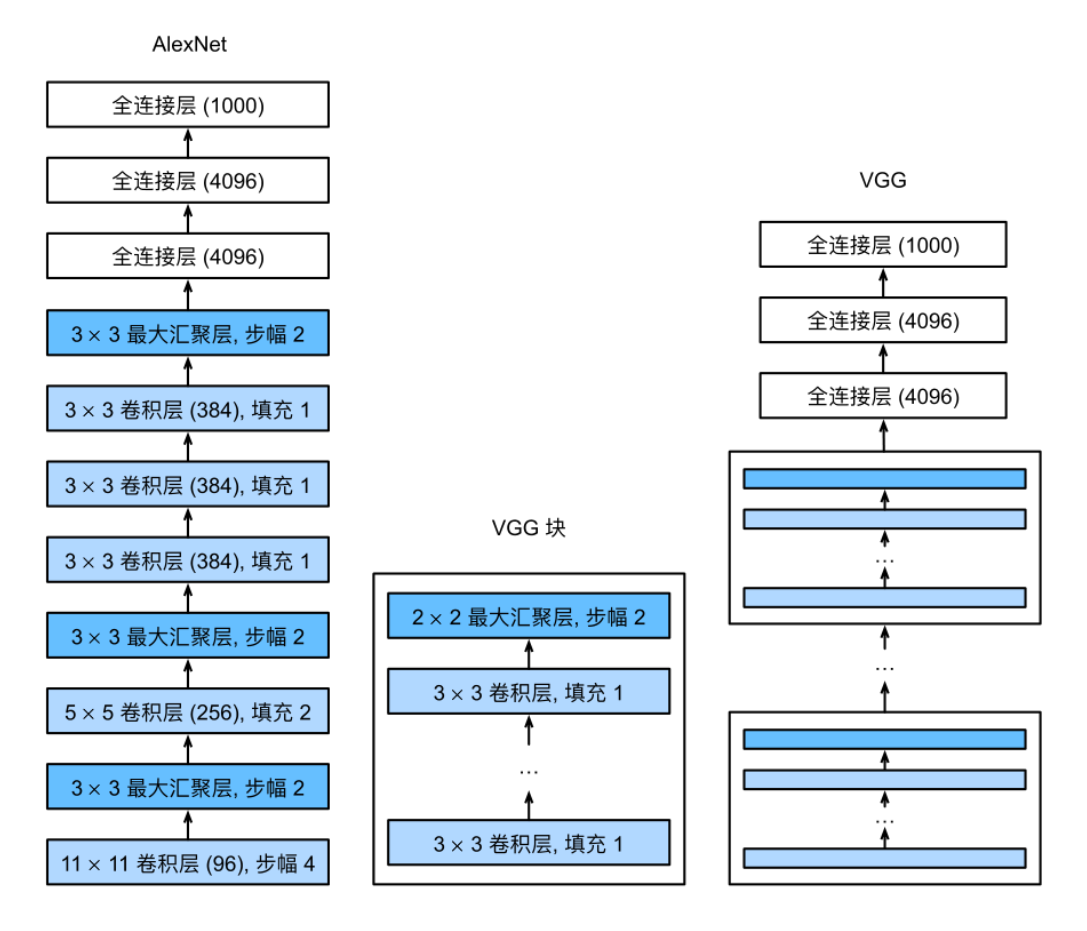
VGG神经⽹络连接 图7.2.1的⼏个VGG块(在vgg_block函数中定义)。其中有超参数变量conv_arch。该变量指定了每个VGG块⾥卷积层个数和输出通道数。全连接模块则与AlexNet中的相同。
原始VGG⽹络有5个卷积块,其中前两个块各有⼀个卷积层,后三个块各包含两个卷积层。第⼀个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该⽹络使⽤8个卷积层和3个全连接层,因此它通常被称为VGG-11。
1 | # 定义VGG神经网络超参数 |
1 | def vgg(conv_arch): |
接下来,我们将构建⼀个⾼度和宽度为224的单通道数据样本,以观察每个层输出的形状。
1 | net = vgg(conv_arch) |
1 | X = torch.randn(size=(1, 1, 224, 224)) |
Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
我们在每个块的⾼度和宽度减半,最终⾼度和宽度都为7。最后再展平表⽰,送⼊全连接层处理。
训练模型
由于VGG-11⽐AlexNet计算量更⼤,因此我们构建了⼀个通道数较少的⽹络,⾜够⽤于训练Fashion-MNIST数据集。
1 | ratio = 4 # 缩放4倍 |
除了使⽤略⾼的学习率外,模型训练过程与AlexNet类似
1 | lr, num_epochs, batch_size = 0.05, 10, 128 |
loss 0.177, train acc 0.935, test acc 0.901
1104.1 examples/sec on cuda:0

- VGG-11使⽤可复⽤的卷积块构造⽹络。不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
- 块的使⽤导致⽹络定义的⾮常简洁。使⽤块可以有效地设计复杂的⽹络。
- 在VGG论⽂中,Simonyan和Ziserman尝试了各种架构。特别是他们发现深层且窄的卷积(即3×3)⽐较浅层且宽的卷积更有效。
网络中的网络(NiN)
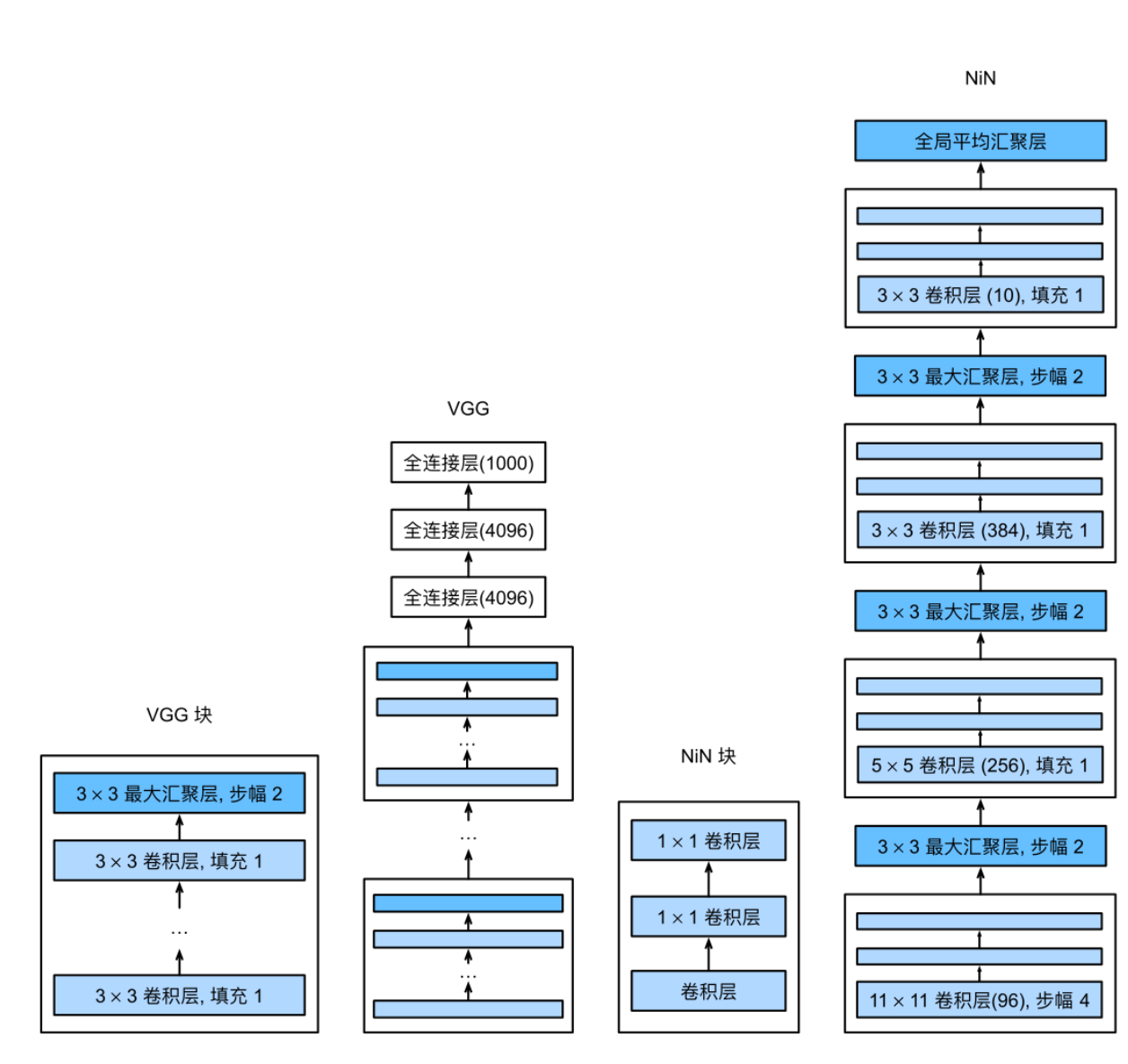
LeNet、AlexNet和VGG都有⼀个共同的设计模式:通过⼀系列的卷积层与汇聚层来提取空间结构特征;然后通过全连接层对特征的表征进⾏处理。AlexNet和VGG对LeNet的改进主要在于如何扩⼤和加深这两个模块。或者,可以想象在这个过程的早期使⽤全连接层。然⽽,如果使⽤了全连接层,可能会完全放弃表征的空间结构。
⽹络中的⽹络(NiN)提供了⼀个⾮常简单的解决⽅案:在每个像素的通道上分别使⽤多层感知机[Lin et al., 2013]
NiN块
卷积层的输⼊和输出由四维张量组成,张量的每个轴分别对应样本、通道、⾼度和宽度。另外,全连接层的输⼊和输出通常是分别对应于样本和特征的⼆维张量。NiN的想法是在每个像素位置(针对每个⾼度和宽度)应⽤⼀个全连接层。如果我们将权重连接到每个空间位置,我们可以将其视为1 × 1卷积层,或作为在每个像素位置上独⽴作⽤的全连接层。从另⼀个⻆度看,即将空间维度中的每个像素视为单个样本,将通道维度视为不同特征(feature)。
1 | import torch |
1 | def nin_block(in_channels, out_channels, kernel_size, strides, padding): |
NiN模型
最初的NiN⽹络是在AlexNet后不久提出的,显然从中得到了⼀些启⽰。NiN使⽤窗⼝形状为11×11、5×5和3×3的卷积层,输出通道数量与AlexNet中的相同。每个NiN块后有⼀个最⼤汇聚层,汇聚窗⼝形状为3 × 3,步幅为2。
NiN和AlexNet之间的⼀个显著区别是NiN完全取消了全连接层。相反,NiN使⽤⼀个NiN块,其输出通道数等于标签类别的数量。最后放⼀个全局平均汇聚层(global average pooling layer),⽣成⼀个对数⼏率(logits)。NiN设计的⼀个优点是,它显著减少了模型所需参数的数量。然⽽,在实践中,这种设计有时会增加训练模型的时间。
1 | net = nn.Sequential( |
我们创建⼀个数据样本来查看每个块的输出形状。
1 | X = torch.rand(size=(1, 1, 224, 224)) |
Sequential output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Sequential output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Sequential output shape: torch.Size([1, 384, 12, 12])
MaxPool2d output shape: torch.Size([1, 384, 5, 5])
Dropout output shape: torch.Size([1, 384, 5, 5])
Sequential output shape: torch.Size([1, 10, 5, 5])
AdaptiveAvgPool2d output shape: torch.Size([1, 10, 1, 1])
Flatten output shape: torch.Size([1, 10])
训练模型
1 | lr, num_epochs, batch_size = 0.1, 10, 128 |
loss 0.354, train acc 0.869, test acc 0.873
1617.0 examples/sec on cuda:0

- NiN使⽤由⼀个卷积层和多个1×1卷积层组成的块。该块可以在卷积神经⽹络中使⽤,以允许更多的每像素⾮线性。
- NiN去除了容易造成过拟合的全连接层,将它们替换为全局平均汇聚层(即在所有位置上进⾏求和)。该汇聚层通道数量为所需的输出数量(例如,Fashion-MNIST的输出为10)。
- 移除全连接层可减少过拟合,同时显著减少NiN的参数。
- NiN的设计影响了许多后续卷积神经⽹络的设计。
含并行连结的网络(GoogLeNet)
在2014年的ImageNet图像识别挑战赛中,⼀个名叫GoogLeNet [Szegedy et al., 2015]的⽹络架构⼤放异彩。GoogLeNet吸收了NiN中串联⽹络的思想,并在此基础上做了改进。这篇论⽂的⼀个重点是解决了什么样⼤⼩的卷积核最合适的问题。毕竟,以前流⾏的⽹络使⽤⼩到1×1,⼤到11×11的卷积核。本⽂的⼀个观点是,有时使⽤不同⼤⼩的卷积核组合是有利的。在本节中,我们将介绍⼀个稍微简化的GoogLeNet版本:我们省略了⼀些为稳定训练⽽添加的特殊特性,现在有了更好的训练⽅法,这些特性不是必要的。
Inception块
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)。这很可能得名于电影《盗梦空间》(In-ception),因为电影中的⼀句话“我们需要⾛得更深”(“We need to go deeper”)。
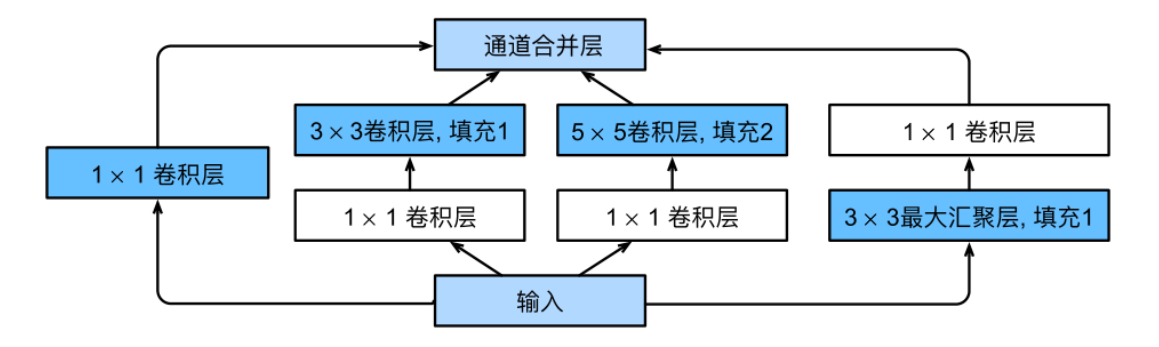
Inception块由四条并⾏路径组成。前三条路径使⽤窗⼝⼤⼩为1×1、3×3和5×5的卷积层,从不同空间⼤⼩中提取信息。中间的两条路径在输⼊上执⾏1 × 1卷积,以减少通道数,从⽽降低模型的复杂性。第四条路径使⽤3 × 3最⼤汇聚层,然后使⽤1 × 1卷积层来改变通道数。这四条路径都使⽤合适的填充来使输⼊与输出的⾼和宽⼀致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。
1 | import torch |
1 | class Inception(nn.Module): |
先我们考虑⼀下滤波器(filter)的组合,它们可以⽤各种滤波器尺⼨探索图像,这意味着不同⼤⼩的滤波器可以有效地识别不同范围的图像细节。同时,我们可以为不同的滤波器分配不同数量的参数。
GoogLeNet
GoogLeNet⼀共使⽤9个Inception块和全局平均汇聚层的堆叠来⽣成其估计值。Inception块之间的最⼤汇聚层可降低维度。第⼀个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使⽤全连接层。
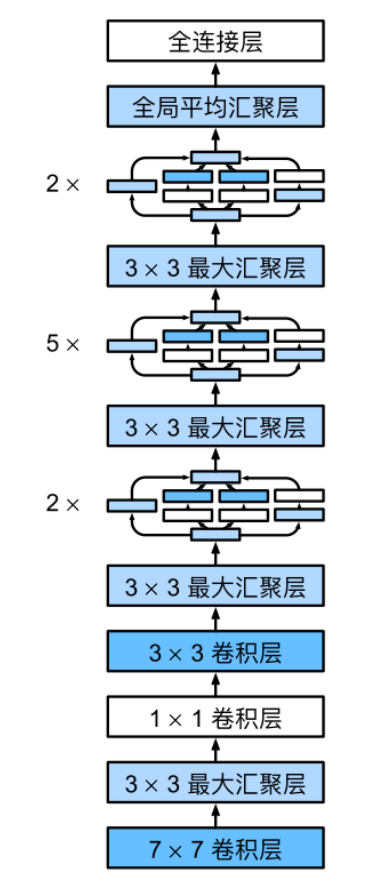
现在,我们逐⼀实现GoogLeNet的每个模块。第⼀个模块使⽤64个通道、7 × 7卷积层。
1 | b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), |
第⼆个模块使⽤两个卷积层:第⼀个卷积层是64个通道、1×1卷积层;第⼆个卷积层使⽤将通道数量增加三倍的3 × 3卷积层。这对应于Inception块中的第⼆条路径。
1 | b2 = nn.Sequential( nn.Conv2d(64, 64, kernel_size=1), |
第三个模块串联两个完整的Inception块。第⼀个Inception块的输出通道数为64 + 128 + 32 + 32 = 256,四个路径之间的输出通道数量⽐为64 : 128 : 32 : 32 = 2 : 4 : 1 : 1。第⼆个和第三个路径⾸先将输⼊通道的数量分别减少到96/192 = 1/2和16/192 = 1/12,然后连接第⼆个卷积层。第⼆个Inception块的输出通道数增加到128 + 192 + 96 + 64 = 480,四个路径之间的输出通道数量⽐为128 : 192 : 96 : 64 = 4 : 6 : 3 : 2。第⼆条和第三条路径⾸先将输⼊通道的数量分别减少到128/256 = 1/2和32/256 = 1/8。
1 | b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32), |
第四模块更加复杂,它串联了5个Inception块,其输出通道数分别是192+208+48+64 = 512、160+224+64 + 64 = 512、128 + 256 + 64 + 64 = 512、112 + 288 + 64 + 64 = 528和256 + 320 + 128 + 128 = 832。这些路径的通道数分配和第三模块中的类似,⾸先是含3×3卷积层的第⼆条路径输出最多通道,其次是仅含1×1卷积层的第⼀条路径,之后是含5×5卷积层的第三条路径和含3×3最⼤汇聚层的第四条路径。其中第⼆、第三条路径都会先按⽐例减⼩通道数。这些⽐例在各个Inception块中都略有不同。
1 | b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64), |
第五模块包含输出通道数为256 + 320 + 128 + 128 = 832和384 + 384 + 128 + 128 = 1024的两个Inception块。其中每条路径通道数的分配思路和第三、第四模块中的⼀致,只是在具体数值上有所不同。需要注意的是,第五模块的后⾯紧跟输出层,该模块同NiN⼀样使⽤全局平均汇聚层,将每个通道的⾼和宽变成1。最后我们将输出变成⼆维数组,再接上⼀个输出个数为标签类别数的全连接层。
1 | b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128), |
GoogLeNet模型的计算复杂,⽽且不如VGG那样便于修改通道数。为了使Fashion-MNIST上的训练短⼩精悍,我们将输⼊的⾼和宽从224降到96,这简化了计算。下⾯演⽰各个模块输出的形状变化。
1 | X = torch.rand(size=(1, 1, 96, 96)) |
Sequential output shape: torch.Size([1, 64, 24, 24])
Sequential output shape: torch.Size([1, 192, 12, 12])
Sequential output shape: torch.Size([1, 480, 6, 6])
Sequential output shape: torch.Size([1, 832, 3, 3])
Sequential output shape: torch.Size([1, 1024])
Linear output shape: torch.Size([1, 10])
训练模型
1 | lr, num_epochs, batch_size = 0.1, 10, 128 |
loss 0.248, train acc 0.905, test acc 0.895
1875.4 examples/sec on cuda:0
