任务1
求出利用最小二乘法通过(1,1) (2,3) (3,3)三点拟合出的直线 # b = 0.1 a = 1.1
$y=wx + b$
创建数据
1
2
3
|
x = np.array([[1], [2], [3]])
y = np.array([1, 3, 3])
|
模型的建立和训练
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
from sklearn.linear_model import LinearRegression, LogisticRegression, LogisticRegressionCV
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from sklearn.svm import SVC, SVR
from sklearn.neural_network import MLPClassifier, MLPRegressor
from sklearn.cluster import KMeans, DBSCAN
from sklearn.naive_bayes import BaseEstimator
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
|
1
2
3
4
5
|
linear_model = LinearRegression()
linear_model.fit(x, y)
|
LinearRegression()
查看模型参数
array([1.])
1
2
|
linear_model.intercept_
|
0.33333333333333437
1
2
|
linear_model.get_params()
|
{'copy_X': True,
'fit_intercept': True,
'n_jobs': None,
'normalize': 'deprecated',
'positive': False}
模型预测
1
2
3
|
y_pre = linear_model.predict(x)
y_pre
|
array([1.33333333, 2.33333333, 3.33333333])
可视化
1
2
3
4
5
6
| import matplotlib.pyplot as plt
plt.scatter(x, y)
plt.plot(x, y_pre, c='r')
plt.show()
|
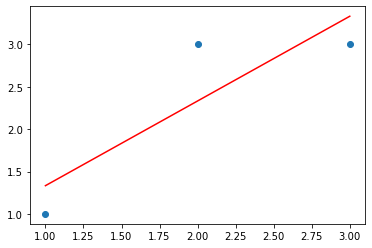
任务2
输入:[[0, 0], [1, 1], [2, 2]]——两个输入
输出:[0, 1, 2]
预测:[3, 3]
$y=w_1x_1 + w_2x_2 + b$
创建数据
1
2
| x = np.array([[0, 0], [1, 1], [2, 2]])
y = np.array([0, 1, 2])
|
模型的建立和训练
1
| from sklearn.linear_model import LinearRegression
|
1
2
|
linear_model2 = LinearRegression(fit_intercept=False)
|
1
2
|
linear_model2.fit(x, y)
|
LinearRegression(fit_intercept=False)
查看模型的参数
array([0.5, 0.5])
1
| linear_model2.intercept_
|
0.0
模型预测
1
2
|
x_test = np.array([[3, 3]])
|
1
| linear_model2.predict(x_test)
|
array([3.])
任务3:波士顿房价预测
获取数据/读取数据
1
2
|
from sklearn.datasets import load_boston
|
- data: 特征值
- target: 标签值
- feature_names: 特征名称
- DESCR: 数据集的描述信息
- filename: 导入的数据文件名称
- data_module: 数据集所在模块
1
2
3
| x = data['data']
y = data['target']
x_name = data['feature_names']
|
(506, 13)
(506,)
数据探索
1
2
3
4
5
| for i in range(x.shape[1]):
tmp_x = x[:, i]
plt.scatter(tmp_x, y, s=10)
plt.title(f'y~{x_name[i]}')
plt.show()
|

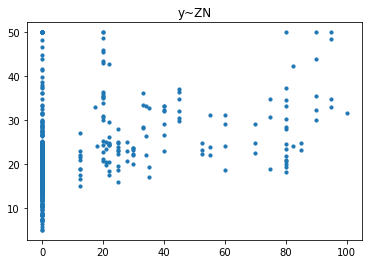
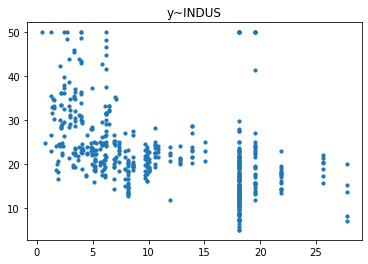

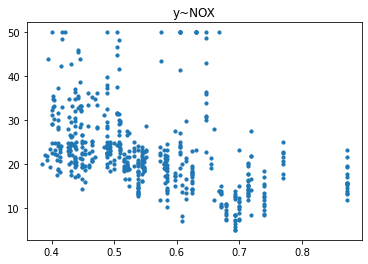
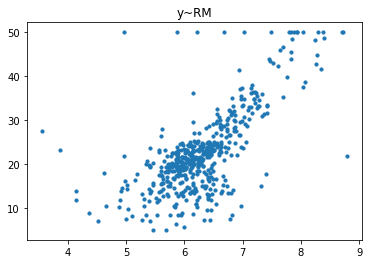

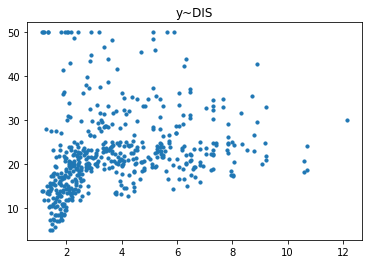


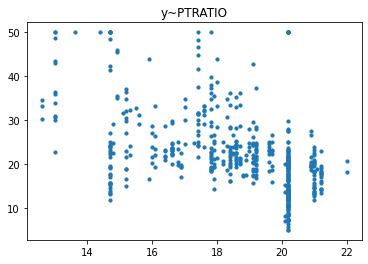
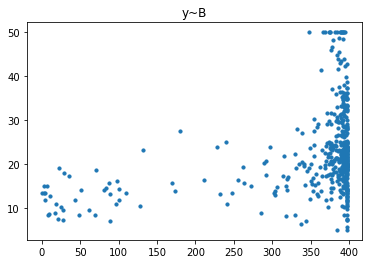

经过对散点图的观测,我们发现只有RM和LSTAT这两列与房价有比较强的相关关系,一个是正相关一个是负相关,所以后续的研究我们以RM这列作为研究对象,预测其与房价的回归模型。
数据的预处理
1
2
3
4
5
6
7
|
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
print(x_train.shape)
print(x_test.shape)
|
(404, 1)
(102, 1)
模型的建立和训练
1
| from sklearn.linear_model import LinearRegression
|
1
| linear_model3 = LinearRegression()
|
1
| linear_model3.fit(x_train, y_train)
|
LinearRegression()
查看模型参数
array([9.12377512])
1
| linear_model3.intercept_
|
-34.702321066310034
模型的预测
1
| y_pred = linear_model3.predict(x_test)
|
可视化预测直线
1
2
3
| plt.scatter(x_test, y_test)
plt.plot(x_test, y_pred, c='r')
plt.show()
|

模型的评价
回归模型的默认评价指标是$R^2$
1
| linear_model3.score(x_test, y_test)
|
0.41700102985892673
- r2_score: $R^2$值(拟合优度)
- mean_squared_error: 均方误差(MSE)
1
| from sklearn.metrics import r2_score, mean_squared_error
|
1
| r2_score(y_test, y_pred)
|
0.41700102985892673
1
| mean_squared_error(y_test, y_pred)
|
50.85450032392045
任务4:研究生录取预测
数据集下载
读取数据
1
2
| data = pd.read_csv('LogisticRegression.csv')
data
|
|
admit |
gre |
gpa |
rank |
| 0 |
0 |
380 |
3.61 |
3 |
| 1 |
1 |
660 |
3.67 |
3 |
| 2 |
1 |
800 |
4.00 |
1 |
| 3 |
1 |
640 |
3.19 |
4 |
| 4 |
0 |
520 |
2.93 |
4 |
| ... |
... |
... |
... |
... |
| 395 |
0 |
620 |
4.00 |
2 |
| 396 |
0 |
560 |
3.04 |
3 |
| 397 |
0 |
460 |
2.63 |
2 |
| 398 |
0 |
700 |
3.65 |
2 |
| 399 |
0 |
600 |
3.89 |
3 |
400 rows × 4 columns
数据探索
重复值处理
(400, 4)
1
2
|
data.drop_duplicates(inplace=True)
|
(395, 4)
说明数据集存在5条重复数据
缺失值探索
admit 0
gre 0
gpa 0
rank 0
dtype: int64
说明数据框中不存在缺失值
数据预处理
1
2
3
|
x = data.iloc[:, -3:]
y = data.iloc[:, 0]
|
1
2
| print(x.shape)
print(y.shape)
|
(395, 3)
(395,)
1
2
3
4
5
6
7
|
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
print(x_train.shape)
print(x_test.shape)
|
(316, 3)
(79, 3)
模型的建立和训练
1
| from sklearn.linear_model import LogisticRegression
|
1
| logistic_model = LogisticRegression()
|
1
| logistic_model.fit(x_train, y_train)
|
LogisticRegression()
模型的预测
1
| y_pred = logistic_model.predict(x_test)
|
模型的评价
1
2
|
logistic_model.score(x_test, y_test)
|
0.759493670886076
1
2
|
from sklearn.metrics import accuracy_score
|
1
| accuracy_score(y_test, y_pred)
|
0.759493670886076
1
2
3
4
|
from sklearn.metrics import precision_score
precision_score(y_test, y_pred)
|
0.8888888888888888
1
2
3
4
|
from sklearn.metrics import recall_score
recall_score(y_test, y_pred)
|
0.3076923076923077
1
2
3
4
|
from sklearn.metrics import f1_score
f1_score(y_test, y_pred)
|
0.4571428571428572
1
2
3
4
|
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
|
precision recall f1-score support
0 0.74 0.98 0.85 53
1 0.89 0.31 0.46 26
accuracy 0.76 79
macro avg 0.82 0.64 0.65 79
weighted avg 0.79 0.76 0.72 79