项目环境介绍 本项目使用的深度学习框架为Tensorflow2,详细环境信息如下:
Python=3.8.16
Tensorflow=2.9.1
keras=2.10.0
cudatoolkit=11.3.1
cudnn=8.2.1
为了防止因数据集过大导致显存过载,首先配置一下Tensorflow调用GPU的规则,设置为动态显存申请。由于这个配置项必须在代码的最前方声明,故提前说明。
在TensorFlow中,GPU内存默认是一次性分配的,这意味着如果模型占用的内存超过可用内存的限制,将无法运行模型,而会出现OOM(Out Of Memory)错误。为了解决这个问题,TensorFlow提供了函数set_memory_growth,它可以让TensorFlow动态分配GPU内存,只使用所需的GPU内存。总之,使用set_memory_growth函数,可以在程序运行时分配所需的GPU内存,而不是在程序启动时将GPU内存分配给TensorFlow,这样可以避免在运行大型模型时出现内存不足的问题。
1 2 3 from tensorflow.config.experimental import list_physical_devices, set_memory_growthphysical_devices = list_physical_devices('GPU' ) set_memory_growth(physical_devices[0 ], True )
项目背景与目标 项目背景 众所周知,猫和狗之间有很多的区别。
从所属科目来看,猫属于猫科动物,狗属于犬科动物;
从体型来看,一般的狗的体型要比猫大;
从叫声来看,猫发出的叫声是喵喵~,而狗发出的叫声是汪汪~
等等,正是因为猫和狗之前的诸多不同,我们人类很容易就能将其区别开,那么我们能否让电脑去捕获这些特征,让电脑识别出猫和狗呢?
项目目标 利用所提供的猫和狗的图片数据,设计并训练出一个能够根据图片区分出猫和狗的模型。
数据:数据集下载
训练集:10000(猫)+10000(狗)
验证集:1250(猫)+1250(狗)
测试集:2500(猫+狗)
数据预处理 根据对原始数据的观察,我们需要做以下预处理操作。
图像尺寸统一,将所有图片的尺寸统一为(150, 150):这是由于神经网络在进行数据输入时,必须要求输入的数据是统一的。
像素归一化:神经网络训练时一般使用较小的权重值来进行拟合,当训练数据的值是较大整数值时,可能对模型的训练速度产生一定的影响,解决办法是将其进行像素值归一化处理。
图像增强:数据增强是深度学习中非常重要的一部分,它可以扩大数据集,提高模型的鲁棒性和泛化能力,降低模型过拟合的风险,进而提高模型的性能和效果。
扩大数据集:数据增强技术通过改变原始图像,如旋转、裁剪、翻转等,可以产生一些新的图像,从而扩大数据集。这对于数据集较小的情况下特别有效,可以防止模型过拟合,提高模型的泛化能力。
增强模型的鲁棒性:数据增强可以增加数据的多样性,使得模型更具有鲁棒性,即对于一定程度的图像扭曲、遮挡、噪声等干扰仍能产生较为准确的预测结果。
降低模型过拟合:过度依赖训练数据样本可能导致过拟合,即在训练数据上表现很好,但是在测试数据上表现很差。通过数据增强,可以生成更多样本,在一定程度上减少过拟合现象,提高模型的泛化能力。
提高模型的性能:数据增强可以让模型使用更多的信息来进行学习,使得模型训练得更充分,进而提高模型的性能。
数据增强 数据增强又分为在线数据增强和离线数据增强。
在线数据增强通常是在模型训练时动态地对数据进行增强,比如对图像进行旋转、缩放、平移、裁剪、翻转、加噪声等操作,从而增加数据的多样性。在线数据增强的优点是能够在模型训练过程中实时地增加训练数据,但也会造成额外的计算开销和内存占用。
离线数据增强则是在训练前对原始数据进行扩充,比如生成新的图像、音频、文本等,从而增加数据的数量和多样性。离线数据增强的优点是可以节省训练时间和计算资源,但需要额外的数据生成和存储工作。
在本项目中,由于训练使用的数据集数据量较大,如果采用离线数据增强的方式,会生成大量新图片数据存储到本地,造成时间和存储空间的浪费。
故在本项目中使用在线数据增强的方式进行处理,在Keras中存在对应的在线数据增强生成器from tensorflow.keras.preprocessing.image import ImageDataGenerator。该生成器对象可以在实例化的时候定义数据增强的方式。
例如:
rotation_range:整数,数据提升时图片随机转动的角度。随机选择图片的角度,是一个0~180的度数,取值为0~180。
width_shift_range:浮点数,图片宽度的某个比例,数据提升时图片随机水平偏移的幅度
height_shift_range:浮点数,图片高度的某个比例,数据提升时图片随机竖直偏移的幅度。
horizontal_flip:布尔值,进行随机水平翻转。随机的对图片进行水平翻转,这个参数适用于水平翻转不影响图片语义的时候。
vertical_flip:布尔值,进行随机竖直翻转。
rescale: 值将在执行其他处理前乘到整个图像上,我们的图像在RGB通道都是0~255的整数,这样的操作可能使图像的值过高或过低,所以我们将这个值定为0~1之间的数。
这里仅列出一小部分,详见Keras官方文档
定义相关路径和参数 1 2 3 4 train_path = '' ../data/dogVScat_data/train/' val_path = ' '../data/dogVScat_data/val/' test_path = '' ../data/dogVScat_data/test/'
1 2 3 4 5 6 size = (150 , 150 ) trian_batch_size = 32 val_batch_size = 8
定义图像生成器 1 2 from tensorflow import kerasfrom tensorflow.keras.preprocessing.image import ImageDataGenerator
1 img_generator = ImageDataGenerator(rescale=1 /255 )
使用图像生成器导入数据 在使用图像生成器时,有一个前提,必须要求所有的图片在一个大文件夹中,大文件夹中有多个子文件夹,用来存储不同类别的图片数据。
例如:
定义训练集生成器 1 2 3 4 5 6 7 train_generator = img_generator.flow_from_directory( directory=train_path, target_size=size, class_mode='binary' , batch_size = trian_batch_size, shuffle=True )
Found 20000 images belonging to 2 classes.
定义验证集生成器 1 2 3 4 5 6 7 8 val_generator = img_generator.flow_from_directory( directory=val_path, target_size=size, class_mode='binary' , batch_size = val_batch_size, shuffle=True )
Found 2500 images belonging to 2 classes.
展示一个生成器的生成结果 1 res = next (train_generator)
1 2 3 tmp_img = res[0 ] tmp_img.shape
(32, 150, 150, 3)
1 2 3 tmp_label = res[1 ] tmp_label
array([0., 1., 0., 0., 1., 0., 1., 1., 1., 0., 0., 0., 0., 0., 0., 1., 0.,
0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 1., 0.],
dtype=float32)
1 2 3 4 5 6 7 plt.figure(figsize=(10 , 10 ), dpi=500 ) for i in range (len (tmp_label[:16 ])): ax = plt.subplot(4 , 4 , i+1 ) ax.set_title(label_dic[tmp_label[i]]) ax.axis('off' ) ax.imshow(tmp_img[i]) plt.show()
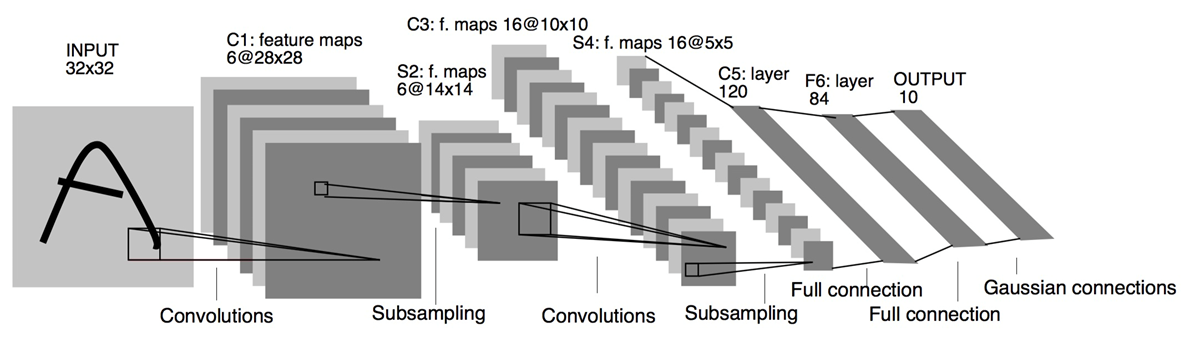
模型搭建 在本项目中我们选用的模型为经典的LeNet-5神经网络模型,模型结构如下图所示:
1 2 3 4 5 from tensorflow import kerasfrom tensorflow.keras import layersfrom tensorflow.keras import lossesfrom tensorflow.keras import metricsfrom tensorflow.keras import optimizers
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 model = keras.Sequential(name='LeNet5' ) model.add(keras.layers.Conv2D(filters=6 , kernel_size=(5 , 5 ), strides=(1 , 1 ), input_shape=(150 , 150 , 3 ), activation='relu' )) model.add(keras.layers.MaxPool2D()) model.add(keras.layers.Conv2D(filters=16 , kernel_size=(5 , 5 ), strides=(1 , 1 ), activation='relu' )) model.add(keras.layers.MaxPool2D()) model.add(keras.layers.Flatten()) model.add(keras.layers.Dense(units=120 , activation='relu' )) model.add(keras.layers.Dense(units=84 , activation='relu' )) model.add(keras.layers.Dense(units=1 , activation='sigmoid' ))
模型的编译 1 model.compile (optimizer='adam' , loss=losses.binary_crossentropy, metrics=metrics.binary_accuracy)
模型的训练 1 history = model.fit(train_generator, steps_per_epoch=100 , epochs=10 , verbose=1 , validation_data=val_generator, validation_steps=8 )
Epoch 1/10
100/100 [==============================] - 5s 42ms/step - loss: 7.4331 - binary_accuracy: 0.5678 - val_loss: 0.6062 - val_binary_accuracy: 0.7656
Epoch 2/10
100/100 [==============================] - 4s 40ms/step - loss: 0.6712 - binary_accuracy: 0.6006 - val_loss: 0.6717 - val_binary_accuracy: 0.6562
Epoch 3/10
100/100 [==============================] - 4s 40ms/step - loss: 0.6344 - binary_accuracy: 0.6606 - val_loss: 0.6986 - val_binary_accuracy: 0.5156
Epoch 4/10
100/100 [==============================] - 4s 40ms/step - loss: 0.6029 - binary_accuracy: 0.6800 - val_loss: 0.7661 - val_binary_accuracy: 0.5781
Epoch 5/10
100/100 [==============================] - 4s 39ms/step - loss: 0.6031 - binary_accuracy: 0.6856 - val_loss: 0.5327 - val_binary_accuracy: 0.7188
Epoch 6/10
100/100 [==============================] - 4s 40ms/step - loss: 0.5514 - binary_accuracy: 0.7309 - val_loss: 0.5909 - val_binary_accuracy: 0.6719
Epoch 7/10
100/100 [==============================] - 4s 39ms/step - loss: 0.5325 - binary_accuracy: 0.7428 - val_loss: 0.5306 - val_binary_accuracy: 0.6406
Epoch 8/10
100/100 [==============================] - 4s 42ms/step - loss: 0.4777 - binary_accuracy: 0.7763 - val_loss: 0.7278 - val_binary_accuracy: 0.6562
Epoch 9/10
100/100 [==============================] - 4s 41ms/step - loss: 0.4717 - binary_accuracy: 0.7809 - val_loss: 0.7141 - val_binary_accuracy: 0.6250
Epoch 10/10
100/100 [==============================] - 4s 41ms/step - loss: 0.4344 - binary_accuracy: 0.8081 - val_loss: 0.6835 - val_binary_accuracy: 0.7188
设置回调函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 model_check_point = keras.callbacks.ModelCheckpoint( filepath='best_model.h5' , monitor='val_binary_accuracy' , verbose=1 , save_best_only=True , save_weights_only=False , mode='auto' ) early_stopping = keras.callbacks.EarlyStopping( monitor='val_binary_accuracy' , min_delta=0 , patience=10 , verbose=1 , mode='auto' ) from keras import backend as Kdef scheduler (epoch ): if epoch % 5 == 0 and epoch != 0 : lr = K.get_value(model.optimizer.lr) K.set_value(model.optimizer.lr, lr * 0.9 ) print ("lr changed to {}" .format (lr * 0.9 )) return K.get_value(model.optimizer.lr) learning_rate_scheduler = keras.callbacks.LearningRateScheduler(scheduler, verbose=1 ) csv_logger = keras.callbacks.CSVLogger('training.log' , separator=',' , append=False ) callbacks = [model_check_point, early_stopping, learning_rate_scheduler, csv_logger]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 model = keras.Sequential(name='LeNet5' ) model.add(keras.layers.Conv2D(filters=6 , kernel_size=(5 , 5 ), strides=(1 , 1 ), input_shape=(150 , 150 , 3 ), activation='relu' )) model.add(keras.layers.MaxPool2D()) model.add(keras.layers.Conv2D(filters=16 , kernel_size=(5 , 5 ), strides=(1 , 1 ), activation='relu' )) model.add(keras.layers.MaxPool2D()) model.add(keras.layers.Flatten()) model.add(keras.layers.Dense(units=120 , activation='relu' )) model.add(keras.layers.Dense(units=84 , activation='relu' )) model.add(keras.layers.Dense(units=1 , activation='sigmoid' ))
1 model.compile (optimizer='adam' , loss=losses.binary_crossentropy, metrics=metrics.binary_accuracy)
1 history = model.fit(train_generator, steps_per_epoch=100 , epochs=100 , verbose=1 , validation_data=val_generator, validation_steps=8 , callbacks=callbacks)
Epoch 1: LearningRateScheduler setting learning rate to 0.0010000000474974513.
Epoch 1/100
99/100 [============================>.] - ETA: 0s - loss: 0.6766 - binary_accuracy: 0.5732
Epoch 1: val_binary_accuracy improved from -inf to 0.68750, saving model to best_model.h5
100/100 [==============================] - 5s 46ms/step - loss: 0.6754 - binary_accuracy: 0.5756 - val_loss: 0.5892 - val_binary_accuracy: 0.6875 - lr: 0.0010
Epoch 2: LearningRateScheduler setting learning rate to 0.0010000000474974513.
Epoch 2/100
100/100 [==============================] - ETA: 0s - loss: 0.6036 - binary_accuracy: 0.6597
Epoch 2: val_binary_accuracy improved from 0.68750 to 0.75000, saving model to best_model.h5
100/100 [==============================] - 5s 45ms/step - loss: 0.6036 - binary_accuracy: 0.6597 - val_loss: 0.5050 - val_binary_accuracy: 0.7500 - lr: 0.0010
Epoch 3: LearningRateScheduler setting learning rate to 0.0010000000474974513.
Epoch 3/100
99/100 [============================>.] - ETA: 0s - loss: 0.5689 - binary_accuracy: 0.6995
Epoch 3: val_binary_accuracy did not improve from 0.75000
100/100 [==============================] - 4s 44ms/step - loss: 0.5700 - binary_accuracy: 0.6988 - val_loss: 0.6376 - val_binary_accuracy: 0.6875 - lr: 0.0010
Epoch 4: LearningRateScheduler setting learning rate to 0.0010000000474974513.
Epoch 4/100
100/100 [==============================] - ETA: 0s - loss: 0.5661 - binary_accuracy: 0.7138
Epoch 4: val_binary_accuracy improved from 0.75000 to 0.76562, saving model to best_model.h5
100/100 [==============================] - 4s 43ms/step - loss: 0.5661 - binary_accuracy: 0.7138 - val_loss: 0.4945 - val_binary_accuracy: 0.7656 - lr: 0.0010
Epoch 5: LearningRateScheduler setting learning rate to 0.0010000000474974513.
Epoch 5/100
99/100 [============================>.] - ETA: 0s - loss: 0.5255 - binary_accuracy: 0.7421
Epoch 5: val_binary_accuracy improved from 0.76562 to 0.81250, saving model to best_model.h5
100/100 [==============================] - 4s 43ms/step - loss: 0.5253 - binary_accuracy: 0.7422 - val_loss: 0.4567 - val_binary_accuracy: 0.8125 - lr: 0.0010
lr changed to 0.0009000000427477062
Epoch 6: LearningRateScheduler setting learning rate to 0.0009000000427477062.
Epoch 6/100
99/100 [============================>.] - ETA: 0s - loss: 0.4889 - binary_accuracy: 0.7620
Epoch 6: val_binary_accuracy improved from 0.81250 to 0.82812, saving model to best_model.h5
100/100 [==============================] - 4s 42ms/step - loss: 0.4880 - binary_accuracy: 0.7622 - val_loss: 0.4246 - val_binary_accuracy: 0.8281 - lr: 9.0000e-04
Epoch 7: LearningRateScheduler setting learning rate to 0.0009000000427477062.
Epoch 7/100
99/100 [============================>.] - ETA: 0s - loss: 0.4685 - binary_accuracy: 0.7743
Epoch 7: val_binary_accuracy did not improve from 0.82812
100/100 [==============================] - 4s 41ms/step - loss: 0.4685 - binary_accuracy: 0.7744 - val_loss: 0.4741 - val_binary_accuracy: 0.7500 - lr: 9.0000e-04
Epoch 8: LearningRateScheduler setting learning rate to 0.0009000000427477062.
Epoch 8/100
99/100 [============================>.] - ETA: 0s - loss: 0.4374 - binary_accuracy: 0.7989
Epoch 8: val_binary_accuracy did not improve from 0.82812
100/100 [==============================] - 4s 42ms/step - loss: 0.4376 - binary_accuracy: 0.7987 - val_loss: 0.5664 - val_binary_accuracy: 0.6406 - lr: 9.0000e-04
Epoch 9: LearningRateScheduler setting learning rate to 0.0009000000427477062.
Epoch 9/100
99/100 [============================>.] - ETA: 0s - loss: 0.4539 - binary_accuracy: 0.7926
Epoch 9: val_binary_accuracy did not improve from 0.82812
100/100 [==============================] - 4s 41ms/step - loss: 0.4530 - binary_accuracy: 0.7934 - val_loss: 0.5788 - val_binary_accuracy: 0.7188 - lr: 9.0000e-04
Epoch 10: LearningRateScheduler setting learning rate to 0.0009000000427477062.
Epoch 10/100
99/100 [============================>.] - ETA: 0s - loss: 0.4373 - binary_accuracy: 0.8040
Epoch 10: val_binary_accuracy did not improve from 0.82812
100/100 [==============================] - 4s 41ms/step - loss: 0.4379 - binary_accuracy: 0.8034 - val_loss: 0.5112 - val_binary_accuracy: 0.7969 - lr: 9.0000e-04
lr changed to 0.0008100000384729356
Epoch 11: LearningRateScheduler setting learning rate to 0.0008100000559352338.
Epoch 11/100
99/100 [============================>.] - ETA: 0s - loss: 0.4136 - binary_accuracy: 0.8122
Epoch 11: val_binary_accuracy did not improve from 0.82812
100/100 [==============================] - 4s 41ms/step - loss: 0.4139 - binary_accuracy: 0.8128 - val_loss: 0.4942 - val_binary_accuracy: 0.7969 - lr: 8.1000e-04
Epoch 12: LearningRateScheduler setting learning rate to 0.0008100000559352338.
Epoch 12/100
99/100 [============================>.] - ETA: 0s - loss: 0.3779 - binary_accuracy: 0.8330
Epoch 12: val_binary_accuracy did not improve from 0.82812
100/100 [==============================] - 4s 42ms/step - loss: 0.3782 - binary_accuracy: 0.8331 - val_loss: 0.4771 - val_binary_accuracy: 0.8125 - lr: 8.1000e-04
Epoch 13: LearningRateScheduler setting learning rate to 0.0008100000559352338.
Epoch 13/100
99/100 [============================>.] - ETA: 0s - loss: 0.3853 - binary_accuracy: 0.8314
Epoch 13: val_binary_accuracy did not improve from 0.82812
100/100 [==============================] - 4s 41ms/step - loss: 0.3836 - binary_accuracy: 0.8325 - val_loss: 0.6342 - val_binary_accuracy: 0.6719 - lr: 8.1000e-04
Epoch 14: LearningRateScheduler setting learning rate to 0.0008100000559352338.
Epoch 14/100
99/100 [============================>.] - ETA: 0s - loss: 0.3323 - binary_accuracy: 0.8573
Epoch 14: val_binary_accuracy did not improve from 0.82812
100/100 [==============================] - 4s 42ms/step - loss: 0.3314 - binary_accuracy: 0.8575 - val_loss: 0.4888 - val_binary_accuracy: 0.7656 - lr: 8.1000e-04
Epoch 15: LearningRateScheduler setting learning rate to 0.0008100000559352338.
Epoch 15/100
100/100 [==============================] - ETA: 0s - loss: 0.3395 - binary_accuracy: 0.8534
Epoch 15: val_binary_accuracy improved from 0.82812 to 0.84375, saving model to best_model.h5
100/100 [==============================] - 4s 42ms/step - loss: 0.3395 - binary_accuracy: 0.8534 - val_loss: 0.4309 - val_binary_accuracy: 0.8438 - lr: 8.1000e-04
lr changed to 0.0007290000503417104
Epoch 16: LearningRateScheduler setting learning rate to 0.0007290000794455409.
Epoch 16/100
99/100 [============================>.] - ETA: 0s - loss: 0.3116 - binary_accuracy: 0.8753
Epoch 16: val_binary_accuracy did not improve from 0.84375
100/100 [==============================] - 4s 41ms/step - loss: 0.3119 - binary_accuracy: 0.8756 - val_loss: 0.3444 - val_binary_accuracy: 0.8281 - lr: 7.2900e-04
Epoch 17: LearningRateScheduler setting learning rate to 0.0007290000794455409.
Epoch 17/100
99/100 [============================>.] - ETA: 0s - loss: 0.2847 - binary_accuracy: 0.8842
Epoch 17: val_binary_accuracy did not improve from 0.84375
100/100 [==============================] - 4s 41ms/step - loss: 0.2850 - binary_accuracy: 0.8834 - val_loss: 0.4776 - val_binary_accuracy: 0.8125 - lr: 7.2900e-04
Epoch 18: LearningRateScheduler setting learning rate to 0.0007290000794455409.
Epoch 18/100
99/100 [============================>.] - ETA: 0s - loss: 0.2925 - binary_accuracy: 0.8810
Epoch 18: val_binary_accuracy did not improve from 0.84375
100/100 [==============================] - 4s 41ms/step - loss: 0.2925 - binary_accuracy: 0.8813 - val_loss: 0.3710 - val_binary_accuracy: 0.8125 - lr: 7.2900e-04
Epoch 19: LearningRateScheduler setting learning rate to 0.0007290000794455409.
Epoch 19/100
99/100 [============================>.] - ETA: 0s - loss: 0.2544 - binary_accuracy: 0.9018
Epoch 19: val_binary_accuracy did not improve from 0.84375
100/100 [==============================] - 4s 41ms/step - loss: 0.2542 - binary_accuracy: 0.9016 - val_loss: 0.4350 - val_binary_accuracy: 0.8125 - lr: 7.2900e-04
Epoch 20: LearningRateScheduler setting learning rate to 0.0007290000794455409.
Epoch 20/100
100/100 [==============================] - ETA: 0s - loss: 0.2393 - binary_accuracy: 0.9038
Epoch 20: val_binary_accuracy did not improve from 0.84375
100/100 [==============================] - 4s 41ms/step - loss: 0.2393 - binary_accuracy: 0.9038 - val_loss: 0.8589 - val_binary_accuracy: 0.6875 - lr: 7.2900e-04
lr changed to 0.0006561000715009868
Epoch 21: LearningRateScheduler setting learning rate to 0.0006561000482179224.
Epoch 21/100
99/100 [============================>.] - ETA: 0s - loss: 0.2071 - binary_accuracy: 0.9192
Epoch 21: val_binary_accuracy did not improve from 0.84375
100/100 [==============================] - 4s 41ms/step - loss: 0.2074 - binary_accuracy: 0.9187 - val_loss: 0.4638 - val_binary_accuracy: 0.7969 - lr: 6.5610e-04
Epoch 22: LearningRateScheduler setting learning rate to 0.0006561000482179224.
Epoch 22/100
99/100 [============================>.] - ETA: 0s - loss: 0.1757 - binary_accuracy: 0.9343
Epoch 22: val_binary_accuracy did not improve from 0.84375
100/100 [==============================] - 4s 40ms/step - loss: 0.1748 - binary_accuracy: 0.9347 - val_loss: 0.5891 - val_binary_accuracy: 0.7500 - lr: 6.5610e-04
Epoch 23: LearningRateScheduler setting learning rate to 0.0006561000482179224.
Epoch 23/100
99/100 [============================>.] - ETA: 0s - loss: 0.1737 - binary_accuracy: 0.9378
Epoch 23: val_binary_accuracy did not improve from 0.84375
100/100 [==============================] - 4s 41ms/step - loss: 0.1728 - binary_accuracy: 0.9381 - val_loss: 0.6565 - val_binary_accuracy: 0.7500 - lr: 6.5610e-04
Epoch 24: LearningRateScheduler setting learning rate to 0.0006561000482179224.
Epoch 24/100
99/100 [============================>.] - ETA: 0s - loss: 0.1539 - binary_accuracy: 0.9489
Epoch 24: val_binary_accuracy improved from 0.84375 to 0.85938, saving model to best_model.h5
100/100 [==============================] - 4s 43ms/step - loss: 0.1549 - binary_accuracy: 0.9484 - val_loss: 0.3733 - val_binary_accuracy: 0.8594 - lr: 6.5610e-04
Epoch 25: LearningRateScheduler setting learning rate to 0.0006561000482179224.
Epoch 25/100
99/100 [============================>.] - ETA: 0s - loss: 0.1448 - binary_accuracy: 0.9508
Epoch 25: val_binary_accuracy did not improve from 0.85938
100/100 [==============================] - 4s 40ms/step - loss: 0.1455 - binary_accuracy: 0.9506 - val_loss: 0.6035 - val_binary_accuracy: 0.7656 - lr: 6.5610e-04
lr changed to 0.0005904900433961303
Epoch 26: LearningRateScheduler setting learning rate to 0.0005904900608584285.
Epoch 26/100
99/100 [============================>.] - ETA: 0s - loss: 0.1366 - binary_accuracy: 0.9542
Epoch 26: val_binary_accuracy did not improve from 0.85938
100/100 [==============================] - 4s 40ms/step - loss: 0.1393 - binary_accuracy: 0.9541 - val_loss: 0.4766 - val_binary_accuracy: 0.8281 - lr: 5.9049e-04
Epoch 27: LearningRateScheduler setting learning rate to 0.0005904900608584285.
Epoch 27/100
99/100 [============================>.] - ETA: 0s - loss: 0.1207 - binary_accuracy: 0.9596
Epoch 27: val_binary_accuracy did not improve from 0.85938
100/100 [==============================] - 4s 40ms/step - loss: 0.1211 - binary_accuracy: 0.9591 - val_loss: 0.9246 - val_binary_accuracy: 0.7500 - lr: 5.9049e-04
Epoch 28: LearningRateScheduler setting learning rate to 0.0005904900608584285.
Epoch 28/100
100/100 [==============================] - ETA: 0s - loss: 0.1131 - binary_accuracy: 0.9625
Epoch 28: val_binary_accuracy did not improve from 0.85938
100/100 [==============================] - 4s 42ms/step - loss: 0.1131 - binary_accuracy: 0.9625 - val_loss: 1.0707 - val_binary_accuracy: 0.7188 - lr: 5.9049e-04
Epoch 29: LearningRateScheduler setting learning rate to 0.0005904900608584285.
Epoch 29/100
99/100 [============================>.] - ETA: 0s - loss: 0.0898 - binary_accuracy: 0.9719
Epoch 29: val_binary_accuracy did not improve from 0.85938
100/100 [==============================] - 4s 40ms/step - loss: 0.0893 - binary_accuracy: 0.9722 - val_loss: 0.8163 - val_binary_accuracy: 0.7656 - lr: 5.9049e-04
Epoch 30: LearningRateScheduler setting learning rate to 0.0005904900608584285.
Epoch 30/100
99/100 [============================>.] - ETA: 0s - loss: 0.1082 - binary_accuracy: 0.9624
Epoch 30: val_binary_accuracy did not improve from 0.85938
100/100 [==============================] - 4s 40ms/step - loss: 0.1075 - binary_accuracy: 0.9628 - val_loss: 0.7376 - val_binary_accuracy: 0.7969 - lr: 5.9049e-04
lr changed to 0.0005314410547725857
Epoch 31: LearningRateScheduler setting learning rate to 0.0005314410664141178.
Epoch 31/100
99/100 [============================>.] - ETA: 0s - loss: 0.0848 - binary_accuracy: 0.9722
Epoch 31: val_binary_accuracy did not improve from 0.85938
100/100 [==============================] - 4s 41ms/step - loss: 0.0847 - binary_accuracy: 0.9722 - val_loss: 0.6468 - val_binary_accuracy: 0.7656 - lr: 5.3144e-04
Epoch 32: LearningRateScheduler setting learning rate to 0.0005314410664141178.
Epoch 32/100
99/100 [============================>.] - ETA: 0s - loss: 0.0616 - binary_accuracy: 0.9804
Epoch 32: val_binary_accuracy did not improve from 0.85938
100/100 [==============================] - 4s 40ms/step - loss: 0.0640 - binary_accuracy: 0.9797 - val_loss: 0.8088 - val_binary_accuracy: 0.7344 - lr: 5.3144e-04
Epoch 33: LearningRateScheduler setting learning rate to 0.0005314410664141178.
Epoch 33/100
99/100 [============================>.] - ETA: 0s - loss: 0.0685 - binary_accuracy: 0.9811
Epoch 33: val_binary_accuracy did not improve from 0.85938
100/100 [==============================] - 4s 40ms/step - loss: 0.0706 - binary_accuracy: 0.9806 - val_loss: 0.9013 - val_binary_accuracy: 0.7969 - lr: 5.3144e-04
Epoch 34: LearningRateScheduler setting learning rate to 0.0005314410664141178.
Epoch 34/100
99/100 [============================>.] - ETA: 0s - loss: 0.0432 - binary_accuracy: 0.9858
Epoch 34: val_binary_accuracy did not improve from 0.85938
100/100 [==============================] - 4s 40ms/step - loss: 0.0432 - binary_accuracy: 0.9859 - val_loss: 0.8229 - val_binary_accuracy: 0.7188 - lr: 5.3144e-04
Epoch 34: early stopping
引入回调函数,模型一共训练了34轮,最优模型的精度为85.938%
接下来使用该模型对测试集进行预测并将预测结果可视化。
1 2 3 from tensorflow import kerasimport cv2import os
1 best_model = keras.models.load_model('best_model.h5' )
1 2 3 4 5 6 7 8 9 all_test_imgs = os.listdir(test_path) index_img = np.random.choice(range (len (all_test_imgs)), 16 , replace=False ) imgs = [] for i in index_img: img = cv2.imread(test_path + all_test_imgs[i]) img = cv2.resize(img, (150 , 150 )) imgs.append(img) imgs = np.array(imgs)
1 2 3 y_pred = best_model.predict(imgs) y_pred = [1 if i > 0.5 else 0 for i in y_pred] y_pred
1/1 [==============================] - 1s 583ms/step
1 import matplotlib.pyplot as plt
1 label_dic = {0 :'cat' , 1 :'dog' }
1 2 3 4 5 6 7 plt.figure(figsize=(10 , 10 )) for i in range (len (y_pred)): ax = plt.subplot(4 , 4 , i+1 ) ax.set_title(label_dic[y_pred[i]]) ax.axis('off' ) ax.imshow(imgs[i][:, :, ::-1 ]) plt.show()
从可视化结果可以看出,模型的效果不好,16张图片预测错误了4张。
使用迁移学习去改善模型训练效果 1 2 3 from tensorflow.keras.applications import resnet50conv_base = resnet50.ResNet50(weights='imagenet' , include_top=False , input_shape=(150 , 150 , 3 ))
1 2 3 4 5 6 7 8 for layers in conv_base.layers[:]: layers.trainable = False x = conv_base.output x = keras.layers.GlobalAveragePooling2D()(x) x = keras.layers.Dense(256 , activation='relu' )(x) predictions = keras.layers.Dense(1 , activation='sigmoid' )(x) model = keras.Model(inputs=conv_base.input , outputs=predictions)
1 2 3 model.compile (optimizer='adam' , loss=losses.binary_crossentropy, metrics=metrics.binary_accuracy)
重新定义回调函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 model_check_point = keras.callbacks.ModelCheckpoint( filepath='best_model.h5' , monitor='val_binary_accuracy' , verbose=1 , save_best_only=True , save_weights_only=False , mode='auto' ) early_stopping = keras.callbacks.EarlyStopping( monitor='val_binary_accuracy' , min_delta=0 , patience=10 , verbose=1 , mode='auto' ) from keras import backend as Kdef scheduler (epoch ): if epoch % 5 == 0 and epoch != 0 : lr = K.get_value(model.optimizer.lr) K.set_value(model.optimizer.lr, lr * 0.9 ) print ("lr changed to {}" .format (lr * 0.9 )) return K.get_value(model.optimizer.lr) learning_rate_scheduler = keras.callbacks.LearningRateScheduler(scheduler, verbose=1 ) csv_logger = keras.callbacks.CSVLogger('training.log' , separator=',' , append=False ) callbacks = [model_check_point, early_stopping, learning_rate_scheduler, csv_logger]
定义生成器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 img_generator = ImageDataGenerator(preprocessing_function=keras.applications.resnet.preprocess_input) train_generator = img_generator.flow_from_directory( train_path, target_size=size, batch_size=16 , class_mode='binary' , shuffle=True ) val_generator = img_generator.flow_from_directory( val_path, target_size=size, batch_size=8 , class_mode='binary' , shuffle=True )
Found 20000 images belonging to 2 classes.
Found 2500 images belonging to 2 classes.
1 2 3 4 5 6 7 8 history = model.fit( train_generator, steps_per_epoch=100 , epochs=100 , verbose=1 , validation_data=val_generator, validation_steps=8 , callbacks=callbacks)
Epoch 1: LearningRateScheduler setting learning rate to 0.0010000000474974513.
Epoch 1/100
100/100 [==============================] - ETA: 0s - loss: 0.2755 - binary_accuracy: 0.9044
Epoch 1: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 13s 112ms/step - loss: 0.2755 - binary_accuracy: 0.9044 - val_loss: 0.1234 - val_binary_accuracy: 0.9531 - lr: 0.0010
Epoch 2: LearningRateScheduler setting learning rate to 0.0010000000474974513.
Epoch 2/100
100/100 [==============================] - ETA: 0s - loss: 0.1476 - binary_accuracy: 0.9406
Epoch 2: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 105ms/step - loss: 0.1476 - binary_accuracy: 0.9406 - val_loss: 0.1852 - val_binary_accuracy: 0.9062 - lr: 0.0010
Epoch 3: LearningRateScheduler setting learning rate to 0.0010000000474974513.
Epoch 3/100
100/100 [==============================] - ETA: 0s - loss: 0.1350 - binary_accuracy: 0.9463
Epoch 3: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 105ms/step - loss: 0.1350 - binary_accuracy: 0.9463 - val_loss: 0.0791 - val_binary_accuracy: 0.9375 - lr: 0.0010
Epoch 4: LearningRateScheduler setting learning rate to 0.0010000000474974513.
Epoch 4/100
100/100 [==============================] - ETA: 0s - loss: 0.1435 - binary_accuracy: 0.9450
Epoch 4: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 105ms/step - loss: 0.1435 - binary_accuracy: 0.9450 - val_loss: 0.1381 - val_binary_accuracy: 0.9219 - lr: 0.0010
Epoch 5: LearningRateScheduler setting learning rate to 0.0010000000474974513.
Epoch 5/100
100/100 [==============================] - ETA: 0s - loss: 0.1267 - binary_accuracy: 0.9463
Epoch 5: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 106ms/step - loss: 0.1267 - binary_accuracy: 0.9463 - val_loss: 0.0838 - val_binary_accuracy: 0.9531 - lr: 0.0010
lr changed to 0.0009000000427477062
Epoch 6: LearningRateScheduler setting learning rate to 0.0009000000427477062.
Epoch 6/100
100/100 [==============================] - ETA: 0s - loss: 0.1179 - binary_accuracy: 0.9556
Epoch 6: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 106ms/step - loss: 0.1179 - binary_accuracy: 0.9556 - val_loss: 0.0130 - val_binary_accuracy: 1.0000 - lr: 9.0000e-04
Epoch 7: LearningRateScheduler setting learning rate to 0.0009000000427477062.
Epoch 7/100
100/100 [==============================] - ETA: 0s - loss: 0.1143 - binary_accuracy: 0.9506
Epoch 7: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 106ms/step - loss: 0.1143 - binary_accuracy: 0.9506 - val_loss: 0.0915 - val_binary_accuracy: 0.9688 - lr: 9.0000e-04
Epoch 8: LearningRateScheduler setting learning rate to 0.0009000000427477062.
Epoch 8/100
100/100 [==============================] - ETA: 0s - loss: 0.0939 - binary_accuracy: 0.9594
Epoch 8: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 106ms/step - loss: 0.0939 - binary_accuracy: 0.9594 - val_loss: 0.0665 - val_binary_accuracy: 0.9688 - lr: 9.0000e-04
Epoch 9: LearningRateScheduler setting learning rate to 0.0009000000427477062.
Epoch 9/100
100/100 [==============================] - ETA: 0s - loss: 0.1167 - binary_accuracy: 0.9469
Epoch 9: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 106ms/step - loss: 0.1167 - binary_accuracy: 0.9469 - val_loss: 0.0630 - val_binary_accuracy: 0.9688 - lr: 9.0000e-04
Epoch 10: LearningRateScheduler setting learning rate to 0.0009000000427477062.
Epoch 10/100
100/100 [==============================] - ETA: 0s - loss: 0.1151 - binary_accuracy: 0.9500
Epoch 10: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 105ms/step - loss: 0.1151 - binary_accuracy: 0.9500 - val_loss: 0.0387 - val_binary_accuracy: 1.0000 - lr: 9.0000e-04
lr changed to 0.0008100000384729356
Epoch 11: LearningRateScheduler setting learning rate to 0.0008100000559352338.
Epoch 11/100
100/100 [==============================] - ETA: 0s - loss: 0.0924 - binary_accuracy: 0.9681
Epoch 11: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 106ms/step - loss: 0.0924 - binary_accuracy: 0.9681 - val_loss: 0.0819 - val_binary_accuracy: 0.9688 - lr: 8.1000e-04
Epoch 12: LearningRateScheduler setting learning rate to 0.0008100000559352338.
Epoch 12/100
100/100 [==============================] - ETA: 0s - loss: 0.1084 - binary_accuracy: 0.9556
Epoch 12: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 106ms/step - loss: 0.1084 - binary_accuracy: 0.9556 - val_loss: 0.1482 - val_binary_accuracy: 0.9375 - lr: 8.1000e-04
Epoch 13: LearningRateScheduler setting learning rate to 0.0008100000559352338.
Epoch 13/100
100/100 [==============================] - ETA: 0s - loss: 0.0998 - binary_accuracy: 0.9569
Epoch 13: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 107ms/step - loss: 0.0998 - binary_accuracy: 0.9569 - val_loss: 0.0780 - val_binary_accuracy: 0.9688 - lr: 8.1000e-04
Epoch 14: LearningRateScheduler setting learning rate to 0.0008100000559352338.
Epoch 14/100
100/100 [==============================] - ETA: 0s - loss: 0.0989 - binary_accuracy: 0.9631
Epoch 14: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 106ms/step - loss: 0.0989 - binary_accuracy: 0.9631 - val_loss: 0.0957 - val_binary_accuracy: 0.9688 - lr: 8.1000e-04
Epoch 15: LearningRateScheduler setting learning rate to 0.0008100000559352338.
Epoch 15/100
100/100 [==============================] - ETA: 0s - loss: 0.1124 - binary_accuracy: 0.9600
Epoch 15: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 106ms/step - loss: 0.1124 - binary_accuracy: 0.9600 - val_loss: 0.0735 - val_binary_accuracy: 0.9688 - lr: 8.1000e-04
lr changed to 0.0007290000503417104
Epoch 16: LearningRateScheduler setting learning rate to 0.0007290000794455409.
Epoch 16/100
100/100 [==============================] - ETA: 0s - loss: 0.0928 - binary_accuracy: 0.9644
Epoch 16: val_binary_accuracy did not improve from 1.00000
100/100 [==============================] - 11s 106ms/step - loss: 0.0928 - binary_accuracy: 0.9644 - val_loss: 0.0382 - val_binary_accuracy: 1.0000 - lr: 7.2900e-04
Epoch 16: early stopping
可以发现使用迁移学习后模型在验证集上的精确率到了100%,效果显著提升。
模型的预测 刚才我们已经使用3种方式生成了模型,我们使用最后一次迁移学习生成的模型进行预测
1 2 3 from tensorflow import kerasimport cv2import os
1 best_model = keras.models.load_model('best_model.h5' )
1 2 3 4 5 6 7 8 9 all_test_imgs = os.listdir(test_path) index_img = np.random.choice(range (len (all_test_imgs)), 16 , replace=False ) imgs = [] for i in index_img: img = cv2.imread(test_path + all_test_imgs[i]) img = cv2.resize(img, (150 , 150 )) imgs.append(img) imgs = np.array(imgs)
1 2 3 y_pred = best_model.predict(imgs) y_pred = [1 if i > 0.5 else 0 for i in y_pred] y_pred
1/1 [==============================] - 1s 583ms/step
[0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0]
1 import matplotlib.pyplot as plt
1 label_dic = {0 :'cat' , 1 :'dog' }
1 2 3 4 5 6 7 plt.figure(figsize=(10 , 10 )) for i in range (len (y_pred)): ax = plt.subplot(4 , 4 , i+1 ) ax.set_title(label_dic[y_pred[i]]) ax.axis('off' ) ax.imshow(imgs[i][:, :, ::-1 ]) plt.show()