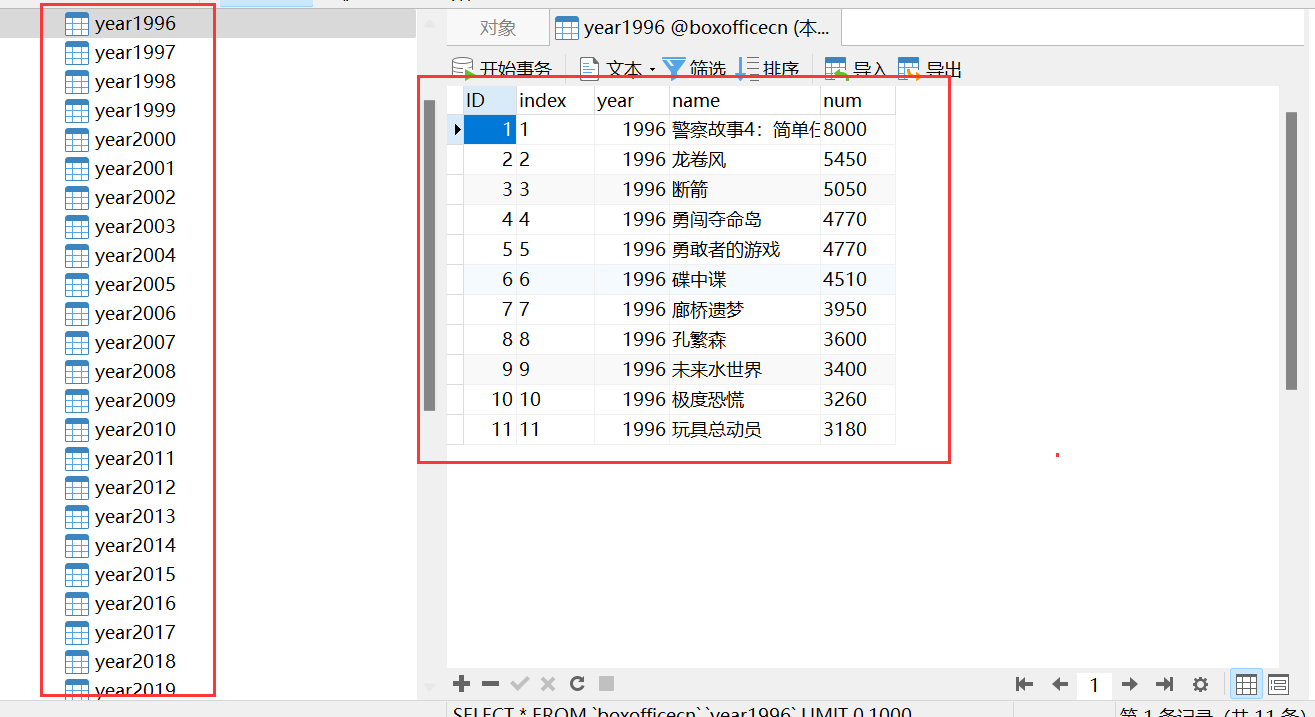
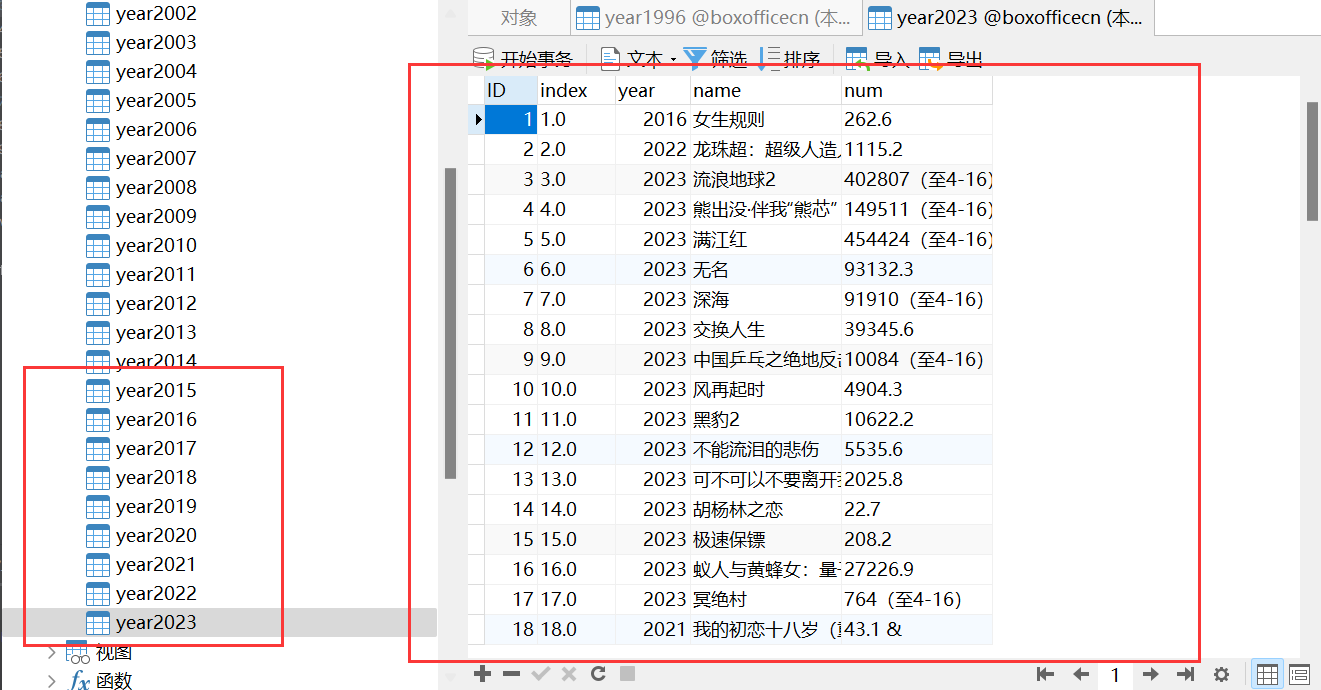
目标网址:http://www.boxofficecn.com/boxofficecn
抓取目标:
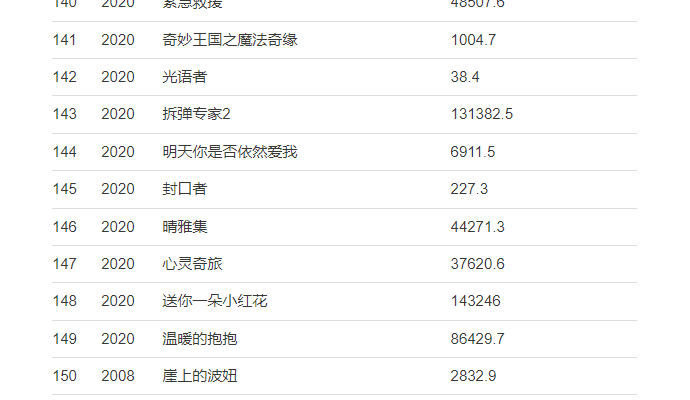
大陆票房1994年至2023年所有票房数据。
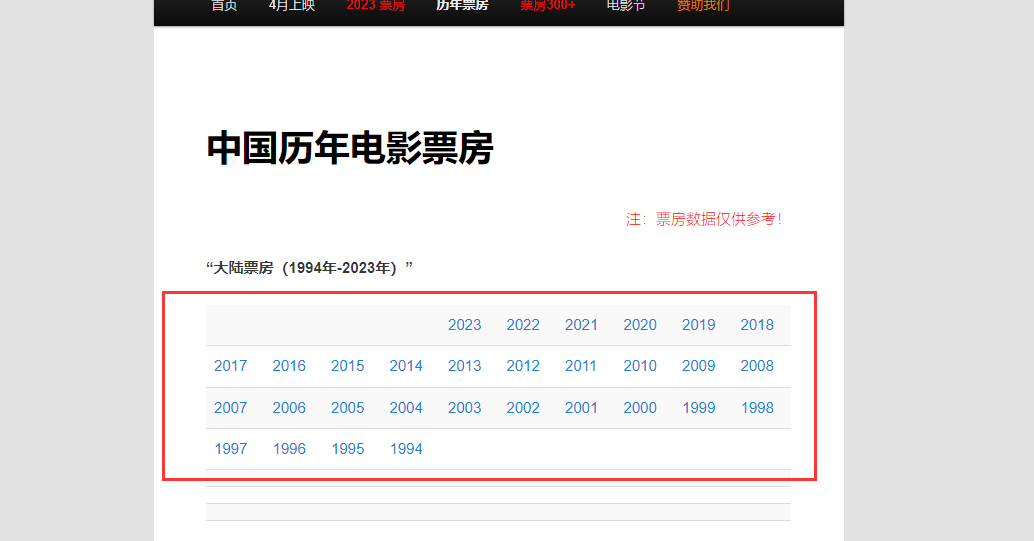
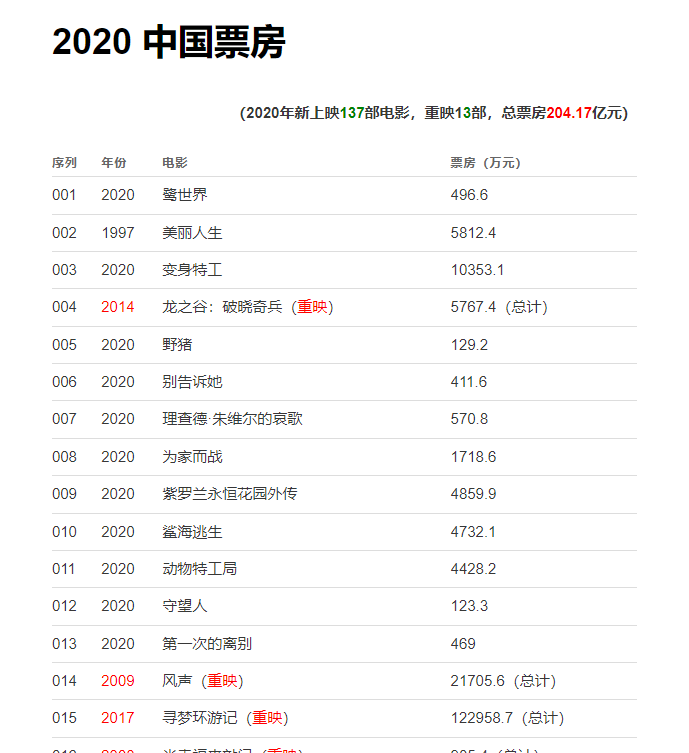
具体内容以2020年为例,抓取(序列,年份,电影,票房数据)。
要求:
将数据存储到数据库中,每个年份的票房为一个数据表,并且要求代码能够自动的创建数据表。
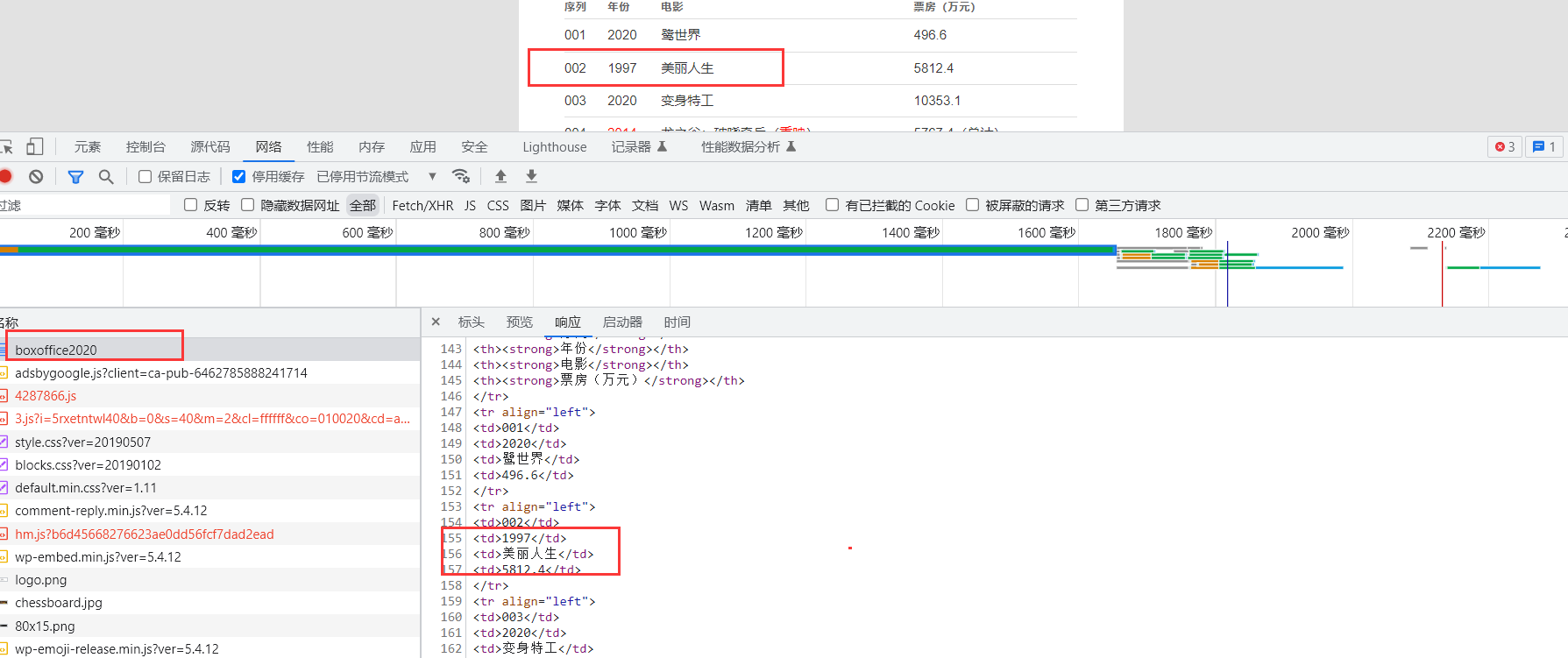
网页分析
由于本案例提出的目的主要是为了使用线程池,实现网络爬虫IO操作。此案例数据相对比较简单,无任何反爬和加密措施,在网页的源代码中即可获取。
数据抓取
在使用线程池处理任务时,一般会使用队列Queue存储任务,并将任务分发给各个线程。
定义分发任务函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| from queue import Queue
def set_work():
"""
设置任务
:return: queue 包含任务的队列
"""
q = Queue()
for year in range(1994, 2024):
q.put(year)
print('*'*20)
print(f"成功添加{q.qsize()}个任务")
print('*'*20)
return q
|
任务函数work,该函数需要传入3个参数。
Queue:包含所有任务的队列cursor:数据库的游标lock:线程锁,这里使用线程锁的原因是因为我们数据需要存储到数据库中,不使用线程锁会导致多个线程同时在数据库中进行数据的插入,为了保证数据的安全性,这种操作在数据库中是不允许的。
同时在work函数中还定义了创建数据表,插入数据等SQL语句。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| import threading
import requests
import pymysql
from concurrent.futures.thread import ThreadPoolExecutor
from lxml import etree
import pandas as pd
def work(q: Queue, cursor, lock):
"""
获取并解析数据
:param year: 指定年份
:return: None 直接将数据存储到数据库中
"""
try:
while q.qsize():
year = q.get()
delectTable_sql = f"""DROP TABLE IF EXISTS `year{year}`;"""
with lock:
cursor.execute(delectTable_sql)
print(delectTable_sql)
createTable_sql = f"""
CREATE TABLE `year{year}` (
`ID` int(0) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '计数变量',
`index` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL COMMENT '序号',
`year` int NULL DEFAULT NULL COMMENT '上映年份',
`name` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL COMMENT '电影名称',
`num` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL COMMENT '票房',
PRIMARY KEY (`ID`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = Dynamic;
"""
with lock:
cursor.execute(createTable_sql)
print(f'CREATE TABLE `YEAR{year}`')
url = f"http://www.boxofficecn.com/boxoffice" + str(year)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
}
response = requests.get(url, headers)
html = etree.HTML(response.text)
all_data = html.xpath("//table")[0]
table = etree.tostring(all_data, encoding='utf-8').decode()
df = pd.read_html(table, encoding='utf-8', header=0)[0]
df.dropna(inplace=True)
results = list(df.T.to_dict().values())
for i in results:
values = list(i.values())
print(f'{year}:', values)
sql = f"insert into `year{year}` VALUES (null, '{values[0]}', {values[1]}, '{values[2]}', '{values[3]}');"
with lock:
cursor.execute(sql)
conn.commit()
except Exception as e:
print(e)
|
主函数。主函数中包含整个任务的执行逻辑,刚开始连接数据库,然后创建并分配任务到队列中,分发任务到每个线程,提交线程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| if __name__ == '__main__':
conn = pymysql.connect(host='localhost',
port=3306,
database="boxofficecn",
user='root',
password='123456')
q = set_work()
lock = threading.Lock()
cursor = conn.cursor()
with ThreadPoolExecutor(16) as t:
for i in range(8):
t.submit(work, q, cursor, lock)
cursor.close()
conn.close()
|
抓取结果