最近忙一个项目,给某个高校部署高性能计算集群,采用的是Slurm系统进行集群资源管理。一共涉及到13个节点,其中有9个节点是有GPU卡的,要想使用GPU进行高性能计算就必须安装相应的显卡驱动和CUDA,在安装这个驱动的时候遇到了很多问题,在此记录详细步骤如下:
首先需要查看电脑中的显卡信息
输入以下命令:
1 | lspci | grep -i nvidia |

如果提示
lspci命令找不到,则需要先下载:
可以看到我这个节点有2块Tesla T4显卡,那么在后续在官网去找驱动时,也需要按照型号去寻找对应的驱动。
事情往往不会这么顺利,并不是所有的显卡使用改行命令都能输出对应的型号,在其中一个节点中就输出了以下内容。

从结果中很难看出对应的显卡型号,这个时候就需要去NVIDIA官网搜索,进入到以下网址:http://pci-ids.ucw.cz/mods/PC/10de?action=help?help=pci
将上方输出的编号20b2输入到网页中相应位置,点击Jump。
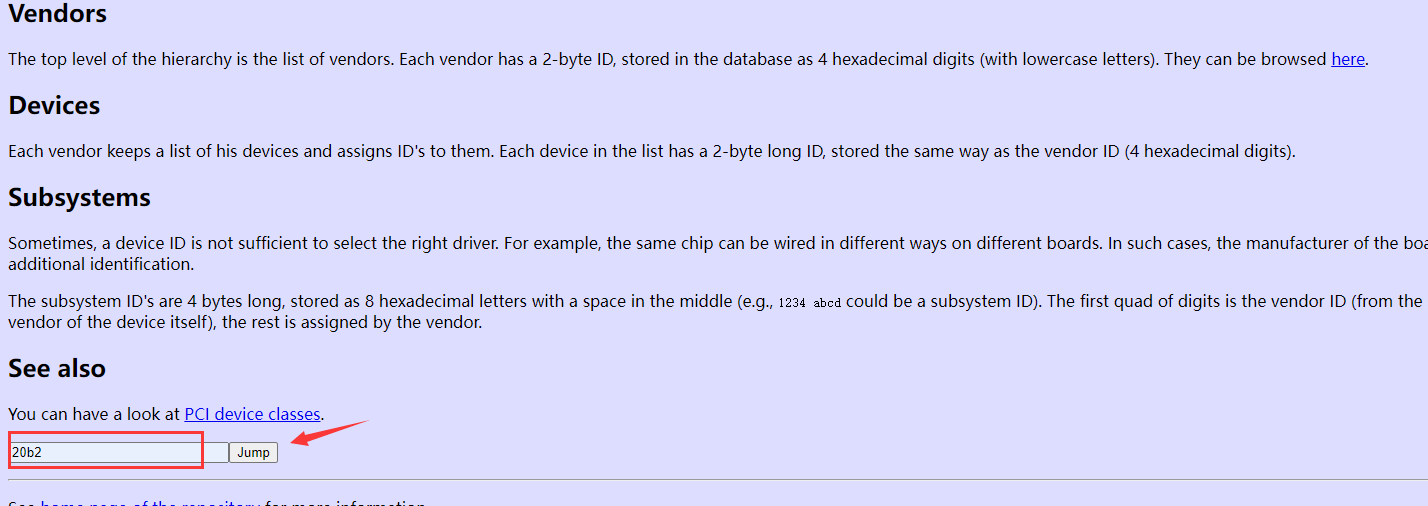

返回出来的结果如图所示,可以看出这个节点中的显卡是2块Telsa A100 80G显卡。
通过以上步骤我们可以获取到每一个节点的显卡信息,如果没有任何输出则说明没有显卡。
例如:

在官网中下载对应显卡的官方驱动
进入以下网址:https://www.nvidia.cn/Download/index.aspx?lang=cn
按照图示参数选择,即可下载对应的显卡驱动,这里我以Telsa A100为例,注意要想使用NVIDIA进行高性能计算必须要安装CUDA驱动,在此我们选择的是11.7版本。
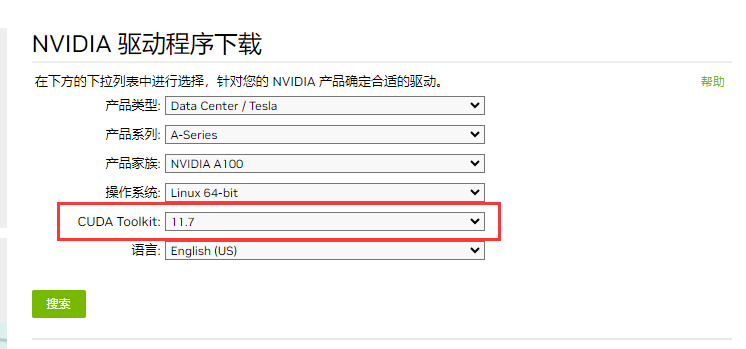
点击搜索后,再点击Download。

然后点击Agree&Download后开始下载。
安装与系统内核对应的kernel-devel与kernel-headers
这一步也是我踩了大量的坑后才总结出来的,直接去安装显卡驱动会报以下错误。
1 | ./A100_NVIDIA-Linux-x86_64-515.105.01.run |

驱动安装失败,安装log文件提示说源码树未发现或者版本不匹配
查看Linux内核
输入命令:
1 | cat /proc/version |

查看系统中已有的kernel-devel与kernel-headers
输入命令:
1 | yum info kernel-devel kernel-headers |
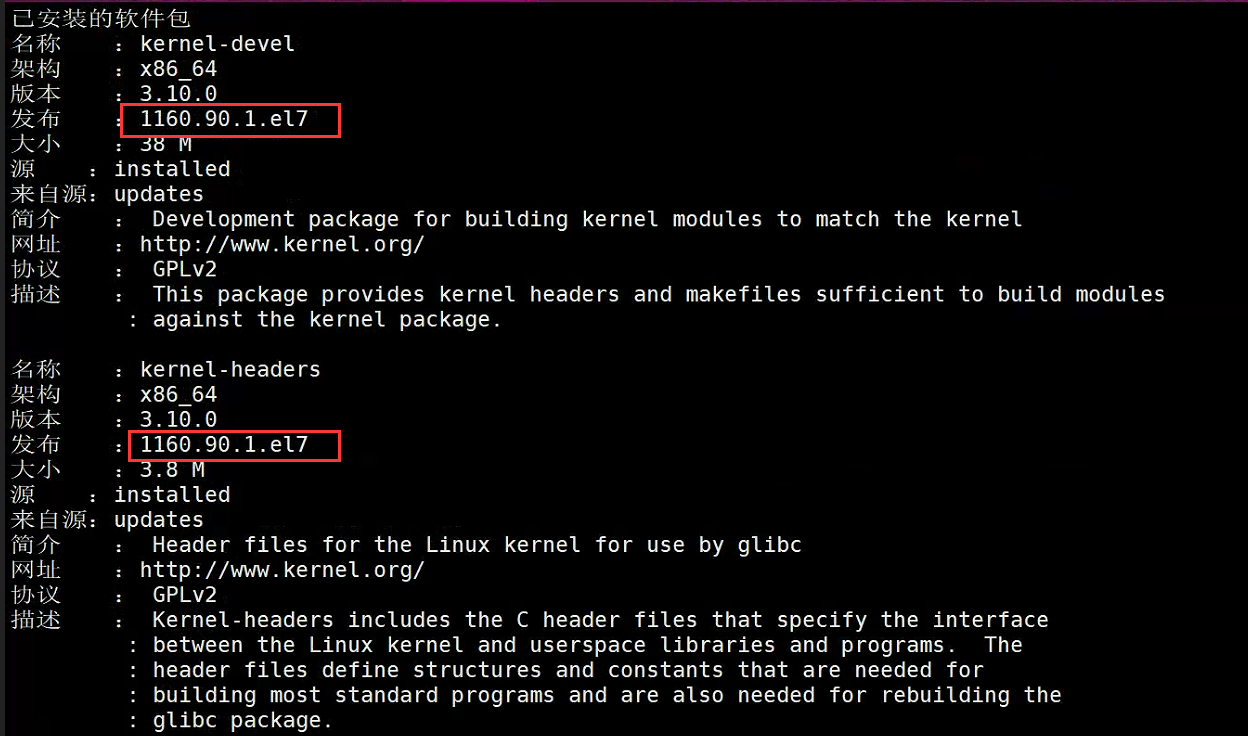
发现两者不匹配,Linux内核中的版本是1160.71.1.el7,而现有的kernel-devel与kernel-headers的的版本是1160.90.1.el7。
现在需要下载和Linux内核中相匹配的kernel-devel与kernel-headers。
进入网站:https://pkgs.org/download/kernel-headers
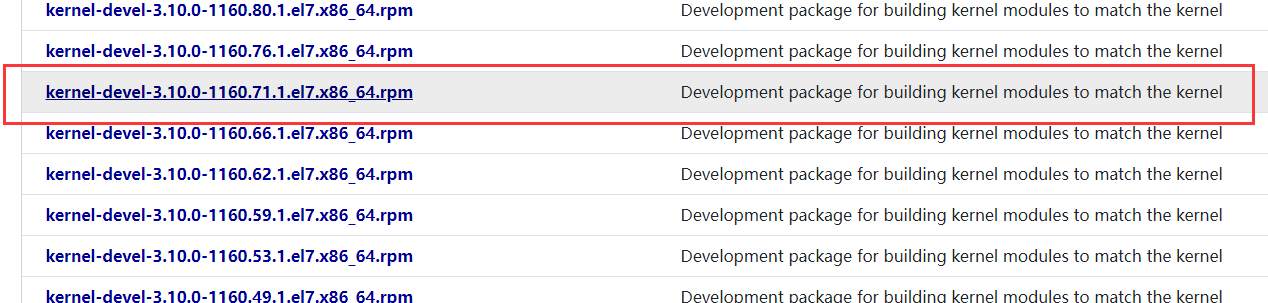
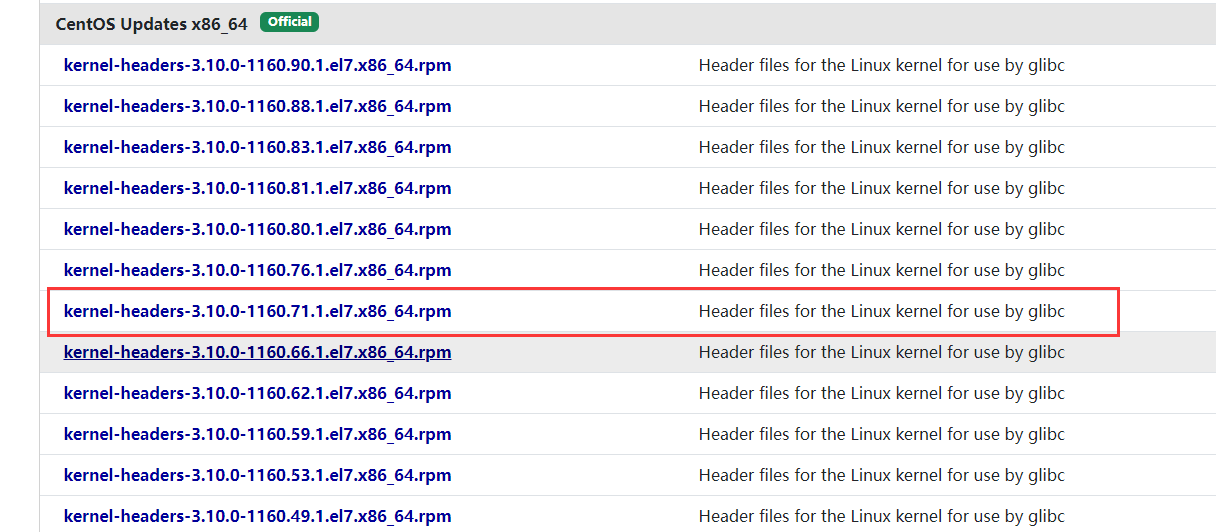
然后输入以下代码进行安装:
1 | rpm -ivh *.rpm --nodeps --force |

安装依赖环境
1 | yum install kernel-devel gcc dkms -y |
禁用nouveau(重启后生效)
修改dist-blacklist.conf文件
1 | vim /lib/modprobe.d/dist-blacklist.conf |
1 | 将nvidiafb注释掉: |
重建 initramfs image
1 | mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak |
重启系统
1 | reboot |
禁用前:输入代码lsmod |grep nouveau
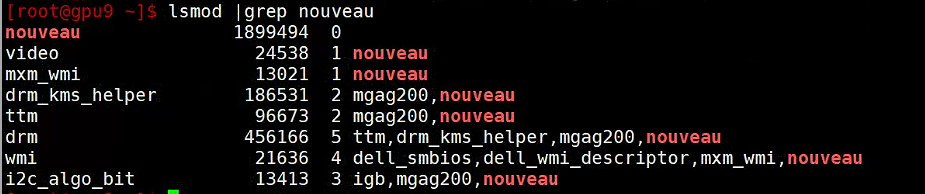
禁用后:

开始安装:

安装成功:

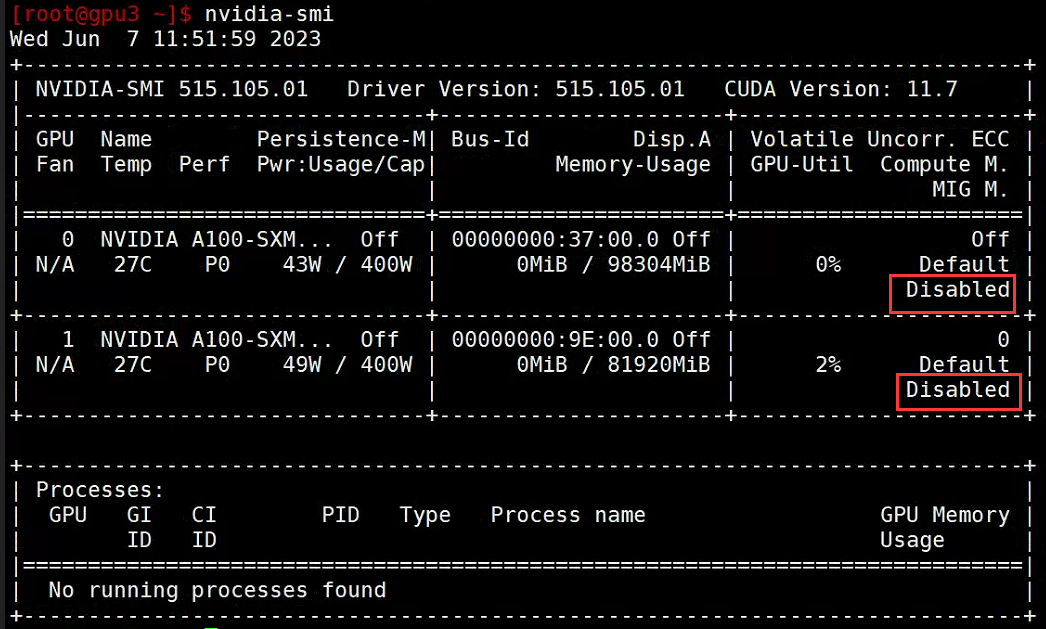
但是此时MIG服务是未开启的。
开启MIG服务(不是所有显卡都支持A100需要安装)
此步骤一般不建议开启,除非有特殊要求,需要将一个GPU分为多个资源,进行不同的任务。
英伟达的多实例技术是一种可以将单个物理GPU资源分割成多个虚拟GPU资源的技术。这种技术可以帮助多个用户或应用程序共享一块物理GPU而不会相互干扰,从而提高了GPU资源的利用率。
具体来说,英伟达的多实例技术通过将单个物理GPU分割成多个虚拟GPU,每个虚拟GPU都可以被不同的用户或应用程序访问。每个虚拟GPU都有自己的显存和计算资源,并且可以独立地运行不同的计算任务。这意味着多个用户或应用程序可以同时使用同一块物理GPU,而不会相互干扰或影响对方的计算任务。
多实例技术还可以为不同的虚拟GPU配置不同的计算能力,以满足不同用户或应用程序的需求。例如,一些虚拟GPU可以被配置为支持图形渲染,而其他虚拟GPU可以被配置为支持深度学习计算等高性能计算任务。
总的来说,英伟达的多实例技术可以帮助用户更好地管理和利用GPU资源,并且可以提高GPU资源的利用率和灵活性。
1 | sudo nvidia-smi -i 0 -mig 1 # 开启编号为0的显卡MIG服务 |
再次查看显卡信息:
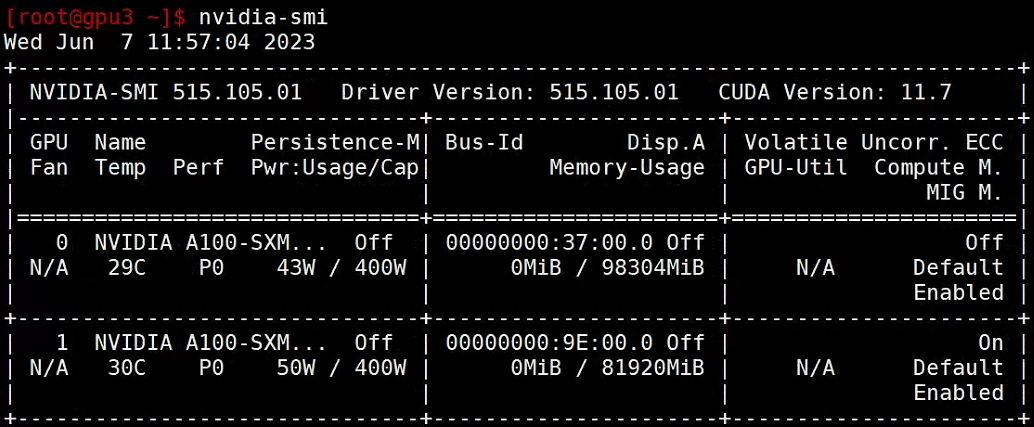
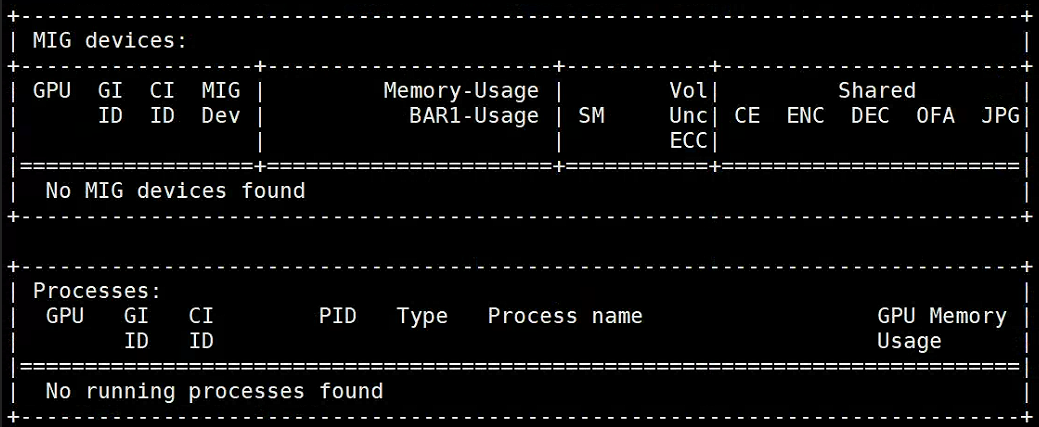
此时MIG服务已被开启,并且MIG设备为空。
安装CUDA驱动
1 | sh cuda_11.7.1_515.65.01_linux.run |

输入accept
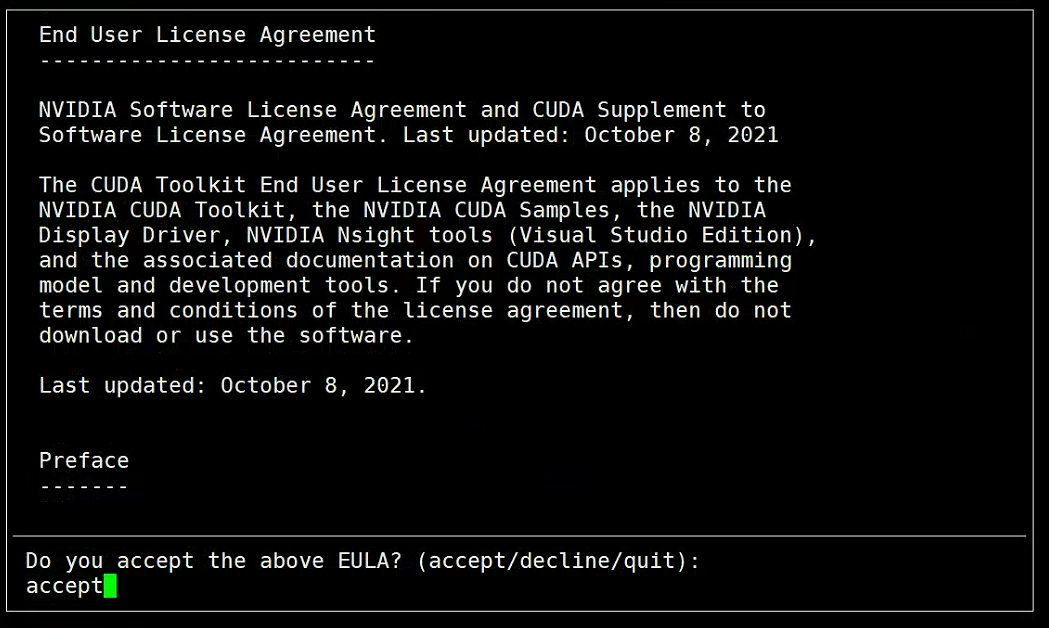
选择Install.
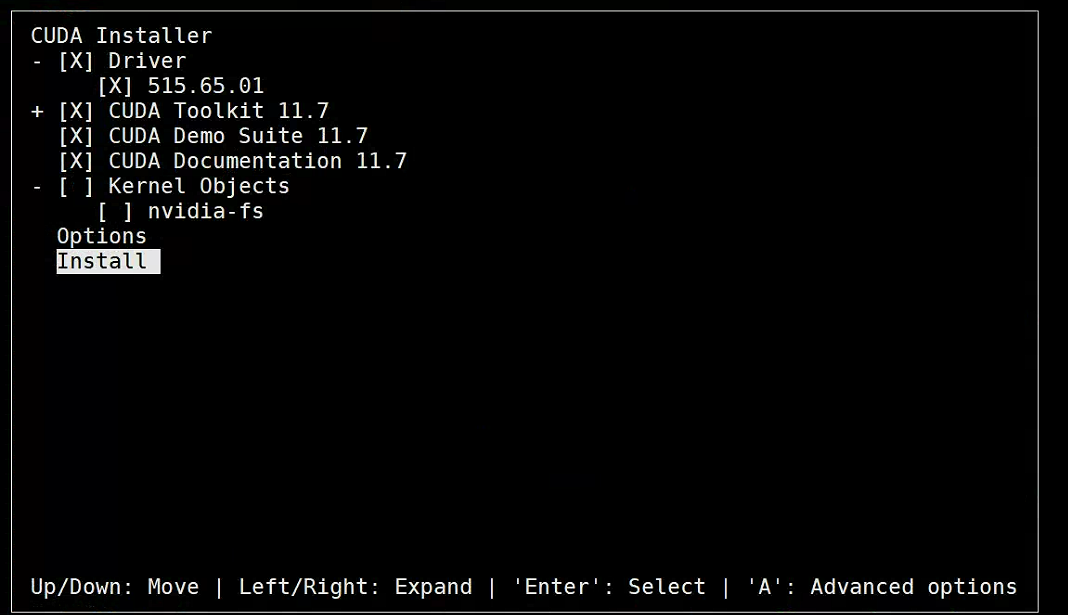
出现如下输出说明安装成功。
添加环境变量:
1 | vim ~/.bashrc |
在文件中添加以下内容:
1 | export PATH=/usr/local/cuda-11.7/bin:$PATH |
保存后输入以下代码使其生效
1 | source ~/.bashrc |
然后输入nvcc -V查看CUDA是否安装成功。
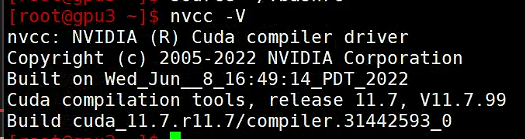
安装成功!
安装CUDNN驱动
1 | sudo cp cudnn-linux-x86_64-8.9.1.23_cuda11-archive/include/cudnn*.h /usr/local/cuda/include |
输出以下内容表示安装成功。
