经过前面教程,我们现在已经搭建好了一个Slurm系统。为了方便管理,我们还需要开发相关的shell脚本用于对集群的管理,在这里我写了三个脚本。
脚本目录
在master1节点目录/root/tools
add_user.sh:新建用户,并赋予用户访问集群资源权限。del_user.sh:删除用户,并移除用户访问集群资源权限。restartSlurm.sh:重启所有的Slurm节点。
脚本详细内容
add_user.sh
1
| sh /root/tools/add_user.sh username <password>
|
根据是否指定初始密码,该脚本有两种使用方式。
使用方法:不指定初始密码
1
| sh /root/tools/add_user.sh username
|
此时会给用户分配一个默认密码:dzdx123456
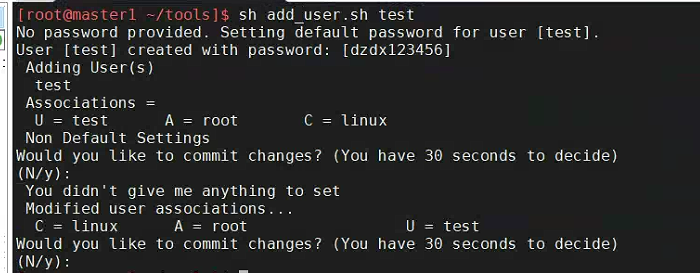
使用方法:指定初始密码
1
| sh /root/tools/add_user.sh username password
|
此时创建出来的密码为指定的密码
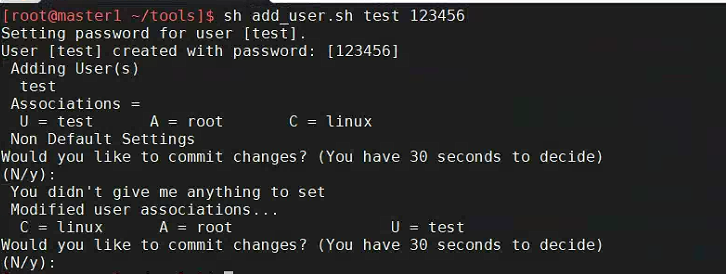
代码
Shell脚本如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| #!/bin/bash
username=$1
if id -u $username >/dev/null 2>&1; then
echo "User $username already exists."
exit -1
fi
# 判断管理员是否给了密码
if [ $# -lt 2 ]
then
password="dzdx123456"
echo "No password provided. Setting default password for user [$username]."
else
password=$2
echo "Setting password for user [$username]."
fi
# 添加用户
# master1节点
useradd -m $username -g diskLimit
# 设置用户家目录最大容量为1.5T
userid=$(id -u $username)
# NFS节点
ssh nfsServer "useradd -M -u $userid $username -g diskLimit"
ssh nfsServer "quotaoff -a && quotaon -ug /home"
# 设置密码
echo "$username:$password" | sudo chpasswd
# 打印设置结果
echo "User [$username] created with password: [$password]"
# 给用户配置Slurm权限
echo "y" | sacctmgr add user name=$username account=root
# 分配访问权限
echo "y" | sacctmgr modify user name=$username partition=compute
# 创建资源限制
echo "y" | sacctmgr modify user name=$username set maxjobs=10 # 设最大作业数为10
#限制具体计算资源使用
#sacctmgr modify account name=$username set GrpTRES="cpu=4,memory=16G,node=1"
#sacctmgr modify account name=$username set GrpTRESMins="cpu=1,memory=1G,node=1"
|
del_user.sh
使用方法
1
| sh /root/tools/del_user.sh username
|
输入以上命令后会弹出一个确认消息

只有当输入为y时,才会执行用户删除操作。
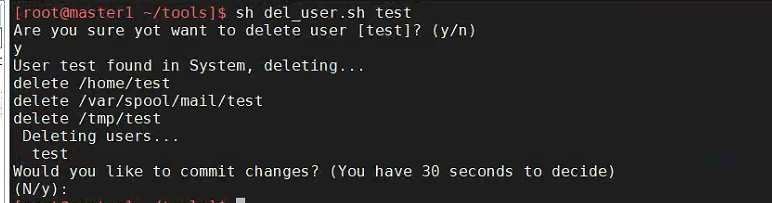
此时会自动删除用户,并将用户相关目录一并移除。
当输入其他内容则取消当前删除操作。
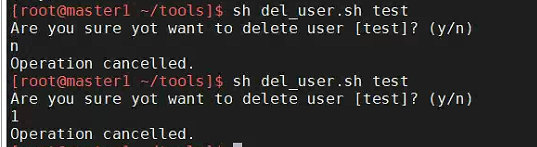
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| #!/bin/bash
username=$1
echo "Are you sure yot want to delete user [$username]? (y/n)"
read answer
if [ "$answer" != "${answer#[Yy]}" ]; then
# 判断用户是否存在
if id -u $username >/dev/null 2>&1; then
echo "User $username found in System, deleting..."
# 删除用户
userdel $username # master1节点
ssh nfsServer "userdel $username" # nfsServer节点
# 删除用户家目录
rm -rf /home/$username
echo "delete /home/$username"
# 删除用户邮件目录
rm -rf /var/spool/mail/$username # master1节点
ssh nfsServer "rm -rf /var/spool/mail/$username" # nfsServer节点
echo "delete /var/spool/mail/$username"
# 删除用户临时文件夹
rm -rf /tmp/$username # master1节点
ssh nfsServer "rm -rf /tmp/$username" # nfsServer节点
echo "delete /tmp/$username"
# 在Account中删除对应的用户
echo "y" | sacctmgr delete user where name=$username
else
echo "User $username not found in system."
exit -1
fi
else
echo "Operation cancelled."
exit -1
fi
|
restartSlurm.sh
使用方法
1
| sh /root/tools/restartSlurm.sh
|
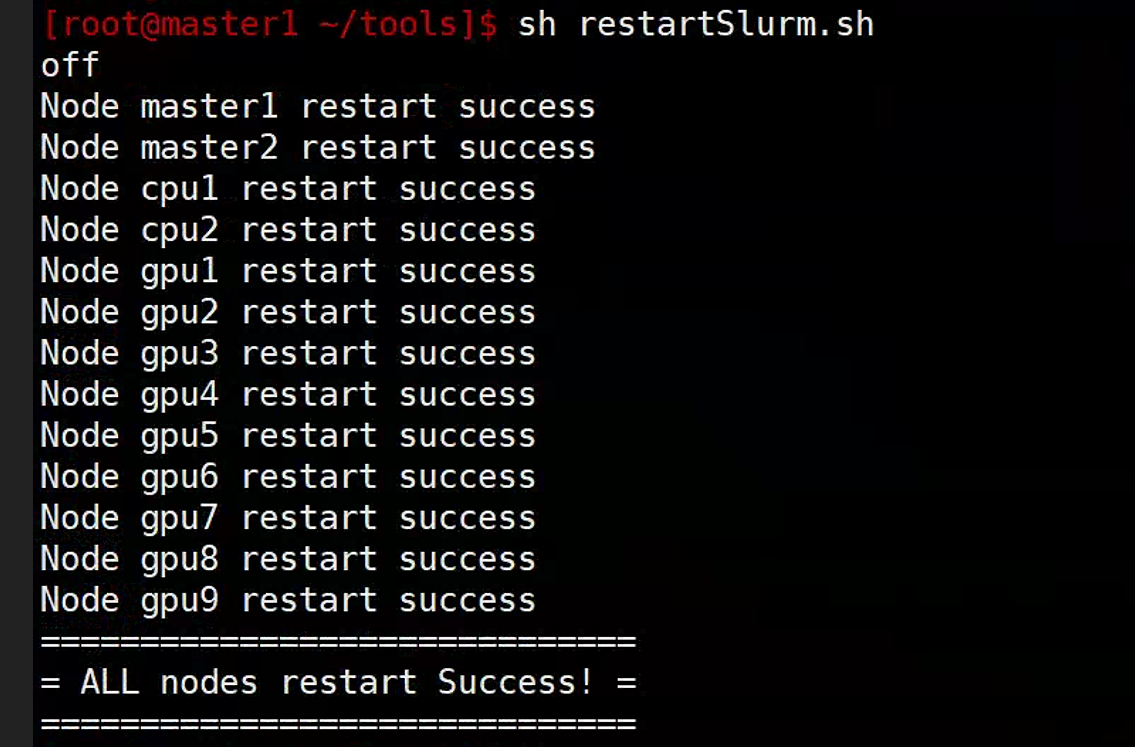
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| echo off
# 重启主节点
slurmdbd restart
slurmctld -c && systemctl restart slurmctld
slurmd -c && systemctl restart slurmd
echo "Node master1 restart success"
# 重启其他节点
ssh master2 "slurmd -c && systemctl restart slurmd"
echo "Node master2 restart success"
ssh cpu1 "slurmd -c && systemctl restart slurmd"
echo "Node cpu1 restart success"
ssh cpu2 "slurmd -c && systemctl restart slurmd"
echo "Node cpu2 restart success"
ssh gpu1 "slurmd -c && systemctl restart slurmd"
echo "Node gpu1 restart success"
ssh gpu2 "slurmd -c && systemctl restart slurmd"
echo "Node gpu2 restart success"
ssh gpu3 "slurmd -c && systemctl restart slurmd"
echo "Node gpu3 restart success"
ssh gpu4 "slurmd -c && systemctl restart slurmd"
echo "Node gpu4 restart success"
ssh gpu5 "slurmd -c && systemctl restart slurmd"
echo "Node gpu5 restart success"
ssh gpu6 "slurmd -c && systemctl restart slurmd"
echo "Node gpu6 restart success"
ssh gpu7 "slurmd -c && systemctl restart slurmd"
echo "Node gpu7 restart success"
ssh gpu8 "slurmd -c && systemctl restart slurmd"
echo "Node gpu8 restart success"
ssh gpu9 "slurmd -c && systemctl restart slurmd"
echo "Node gpu9 restart success"
echo "=============================="
echo "= ALL nodes restart Success! ="
echo "=============================="
|
用户创建完后操作集群进行计算演示
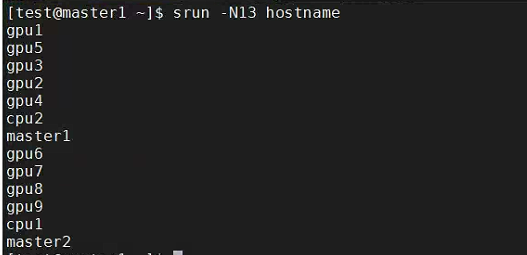
切换用户账号

调用集群执行简单命令
打印13个节点的hostname。
执行结果没有问题,集群资源调用成功。
GPU资源调用测试
我在test用户下创建了一个testGPU.py脚本,用于测试GPU环境是否可用,代码如下:
1
2
| import tensorflow as tf
print(tf.config.list_physical_devices('GPU'))
|
使用集群资源调用脚本。(随机选取3个GPU节点,访问其GPU节点)
1
| srun --gres=gpu:2 -N3 python3 testGPU.py
|
成功访问到3个节点的GPU资源。
