Hadoop的运行模式包括:本地模式、伪分布式以及完全分布式
- 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
- 伪分布式模式:也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
- 完全分布式模式:多台服务器组成分布式环境。生产环境使用。
本地模式
(这步可跳过,建议直接进入完全分布式模式)
在hadoop-3.1.3文件下面创建一个wcinput文件夹,并在文件夹中创建word.txt文件。
1 | cd /opt/module/hadoop-3.1.3/ |
文件内容如下:
1 | hadoop |
然后回到目录/opt/module/hadoop-3.1.3。并执行以下程序。
1 | cd /opt/module/hadoop-3.1.3 |
运行完毕后在hadoop-3.1.3目录下会生成一个,wcoutput目录。
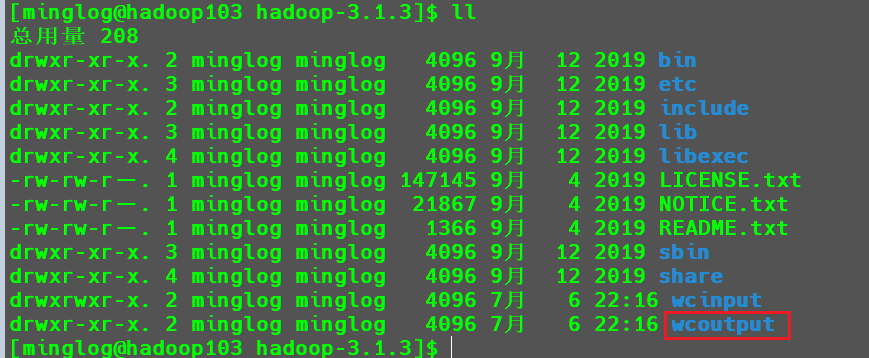
该目录中存放了刚才运行的任务的结果,使用以下命令查看结果。
1 | cat wcoutput/part-r-00000 |

完全分布式模式
前提:已安装此文章要求配置好3台虚拟机。
在MobaXterm中以minglog用户登录三个节点
登录过程类似,只是需要将登录IP地址修改为Hadoop102-104
SSH无密码登录
为了方便我们后面在使用一些工具(例如:scp、rsync等)将文件在不同的机器之间拷贝和同步不需要每次都输入机器的密码,我们需要提前将SSH无密码配置好。
首先,使用MobaXterm同时远程连接三台机器,然后点击MultiExec功能,同时在三个终端输入命令。

点击完成后显示为如下界面。
这个时候输入命令就可以同时在三个终端中生效。
首先复制以下命令
1 | ssh-keygen -t rsa |
然后在MobaXterm中点击右上角Multi-paste将命令同时粘贴到3个节点,然后连续按4次回车生成SSH的公钥和私钥
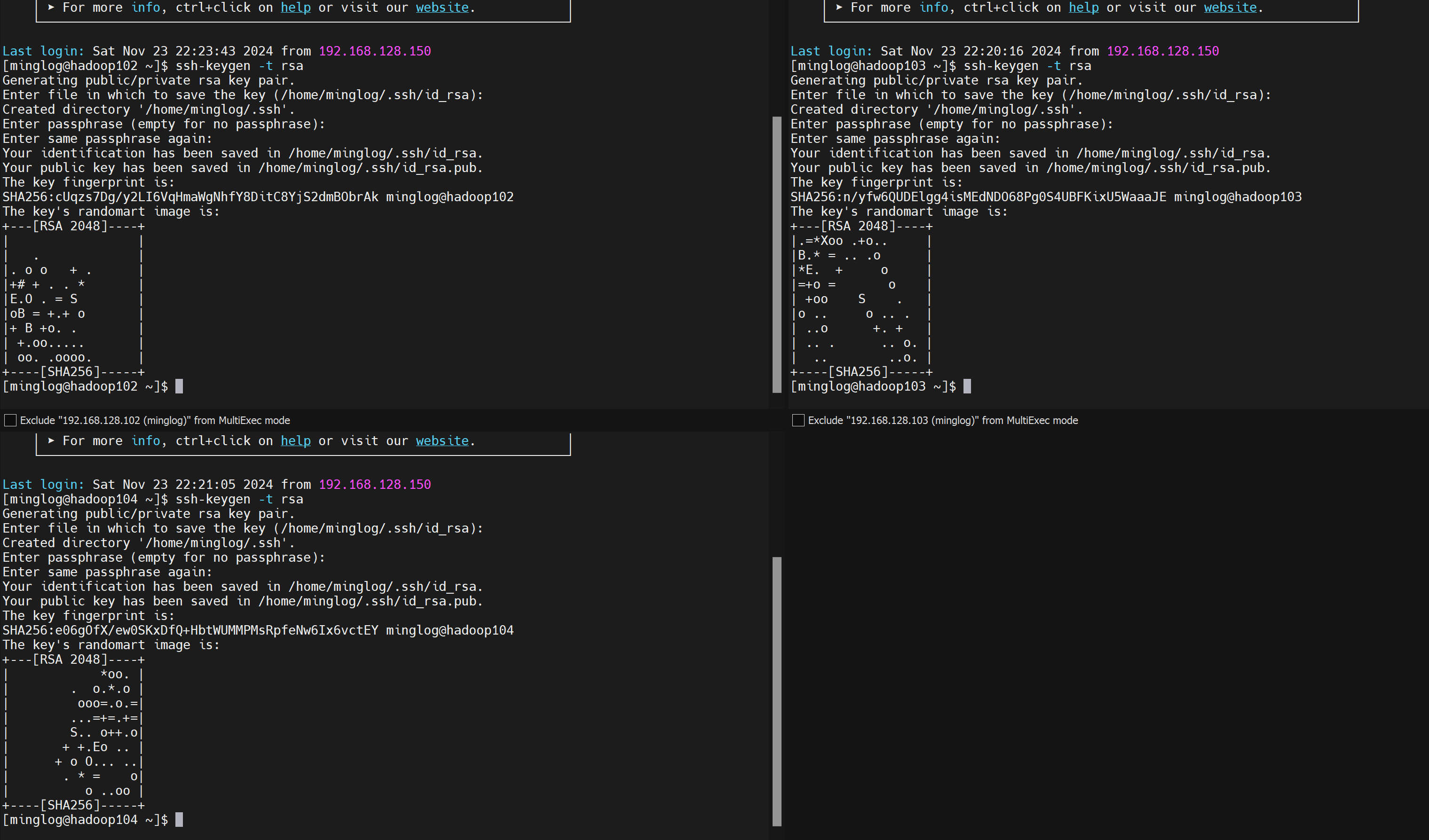
生成完毕后再复制以下内容,同时粘贴到3个终端,并按回车执行。
1 | ssh-copy-id hadoop102 |
输入yes,按回车。
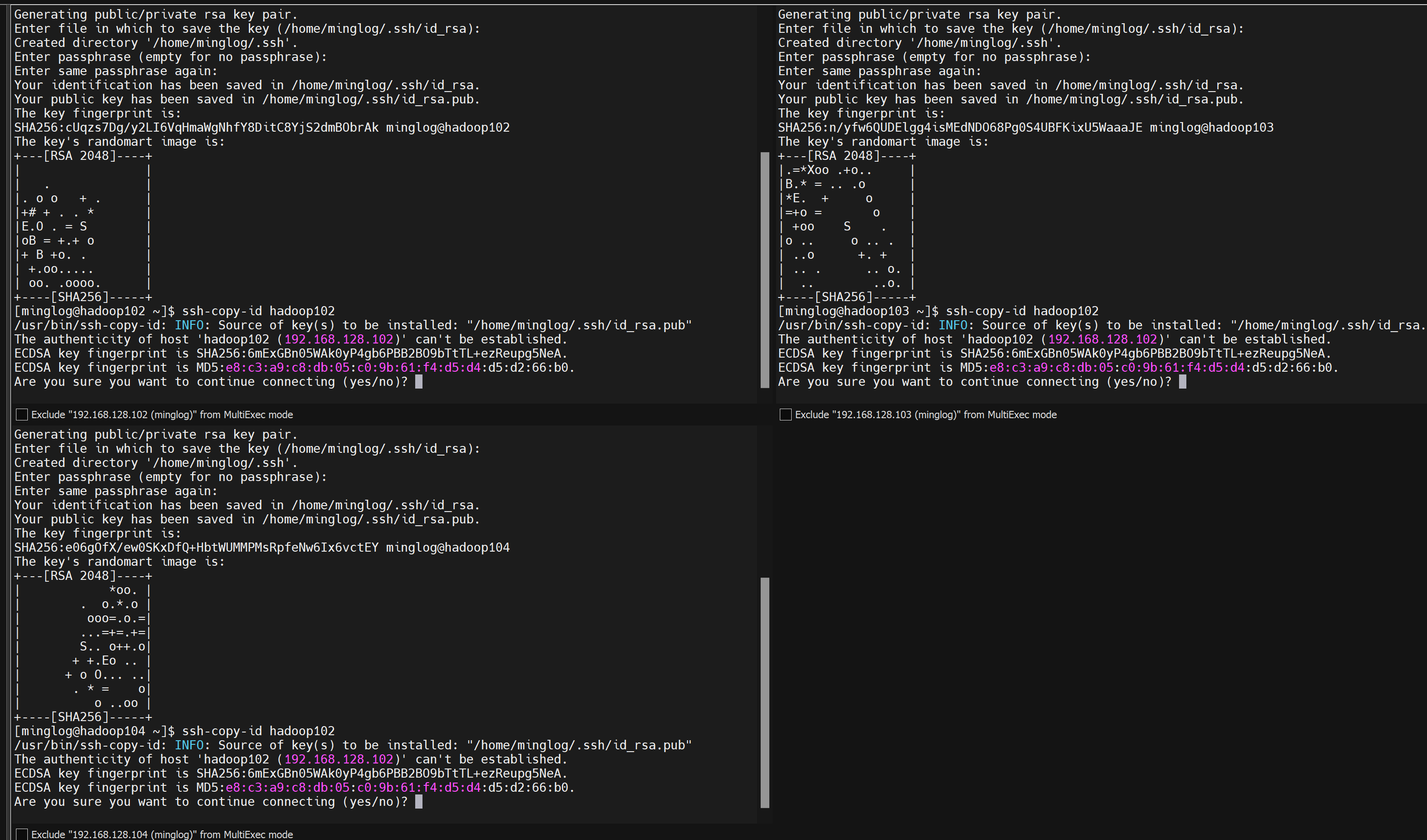
然后输入minglog的密码123456,按回车
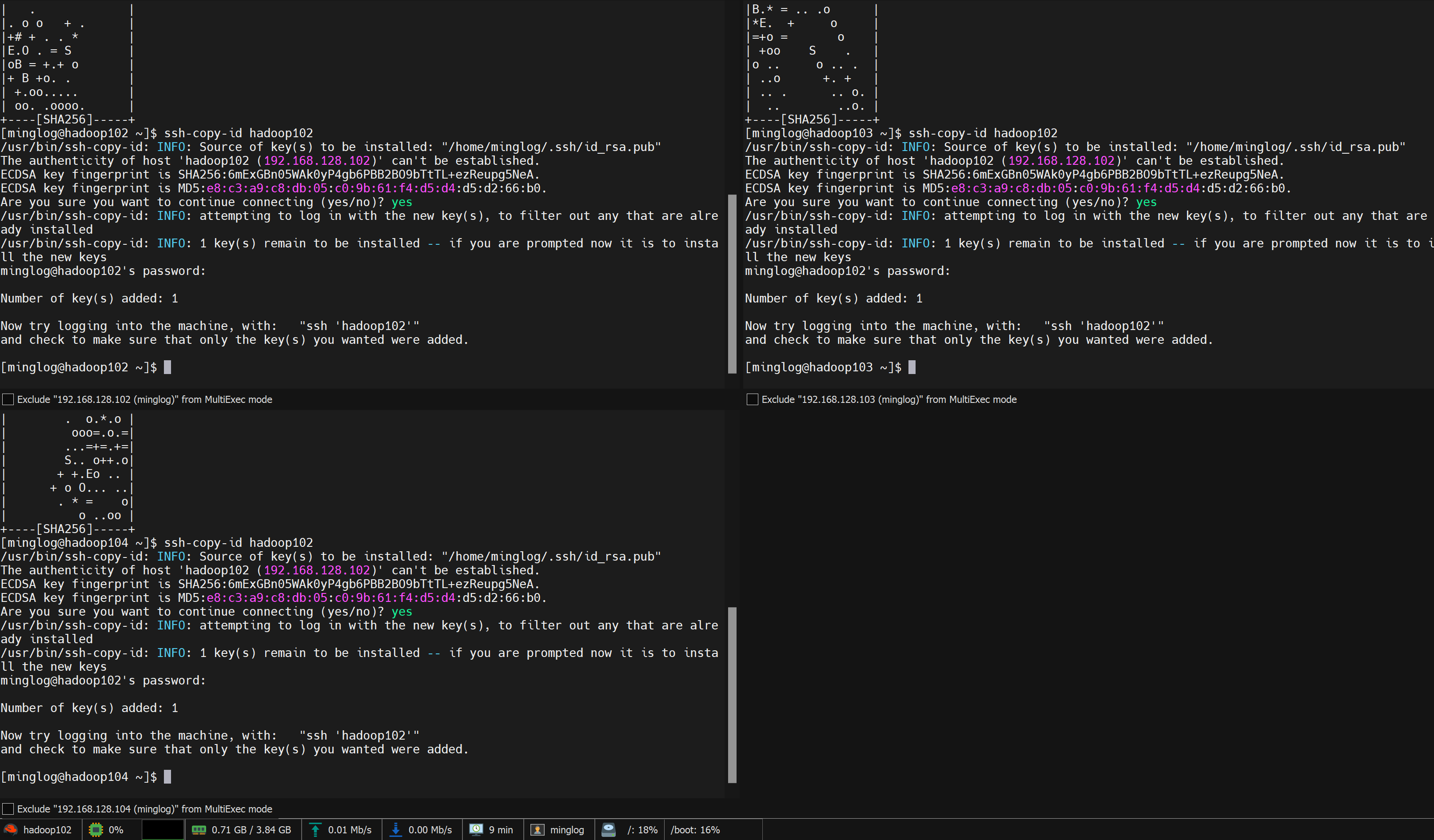
此时配置好了hadoop102节点的无密码登录。按照相同的方式配置103和104节点,这里就不再赘述。
1 | ssh-copy-id hadoop103 |
按照要求配置好所有的节点后,接下来可以测试无密码登录是否成功。
例如hadoop102登录到hadoop103。
直接输入以下内容即可,无需再次输入密码。
1 | ssh hadoop103 |

工具的使用
scp(secure copy)完全拷贝
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
例如现在有hadoop102、hadoop103和hadoop104三台机器,scp可以实现以下功能:
在
hadoop102机器上将文件拷贝到hadoop103和hadoop104。首先在机器
hadoop102上创建几个文件用于后续的文件传输演示。1
2
3vim a.txt # 输入a
vim b.txt # 输入b
vim c.txt # 输入c接下来使用以下命令,将这三个文件拷贝给
hadoop103(hadoop104同理,在此仅演示一个,后续同样。)1
scp /opt/software/* minglog@hadoop103:/opt/software

可以看到,在
hadoop103机器上也有对应文件。在
hadoop102上拉取hadoop103和hadoop104上的文件。首先清空,机器
hadoop102上/opt/software/下的所有文件1
rm -rf /opt/software/*
接下来将
hadoop103机器中的/opt/software/下的文件拉取到hadoop102中。1
scp minglog@hadoop103:/opt/software/* /opt/software/
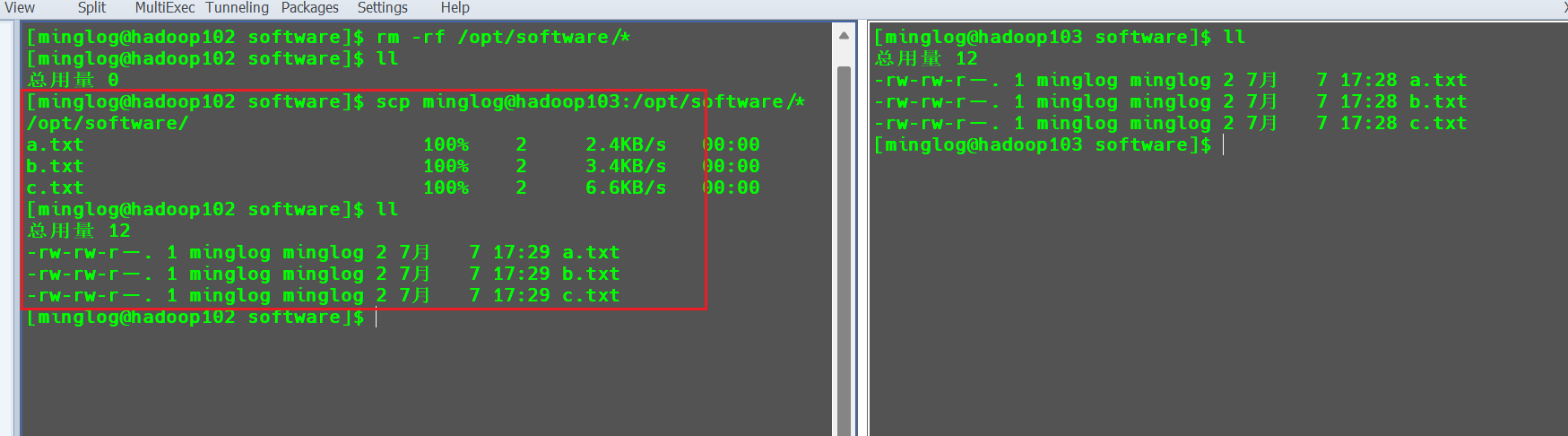
可以看到,同样可以从
hadoop103机器将文件拉取到hadoop102机器。在
hadoop102上将文件从hadoop103往hadoop104拷贝。在机器
hadoop102中输入以下代码,将hadoop103机器的文件拷贝到hadoop104机器:1
scp minglog@hadoop103:/opt/software/* minglog@hadoop104:/opt/software/
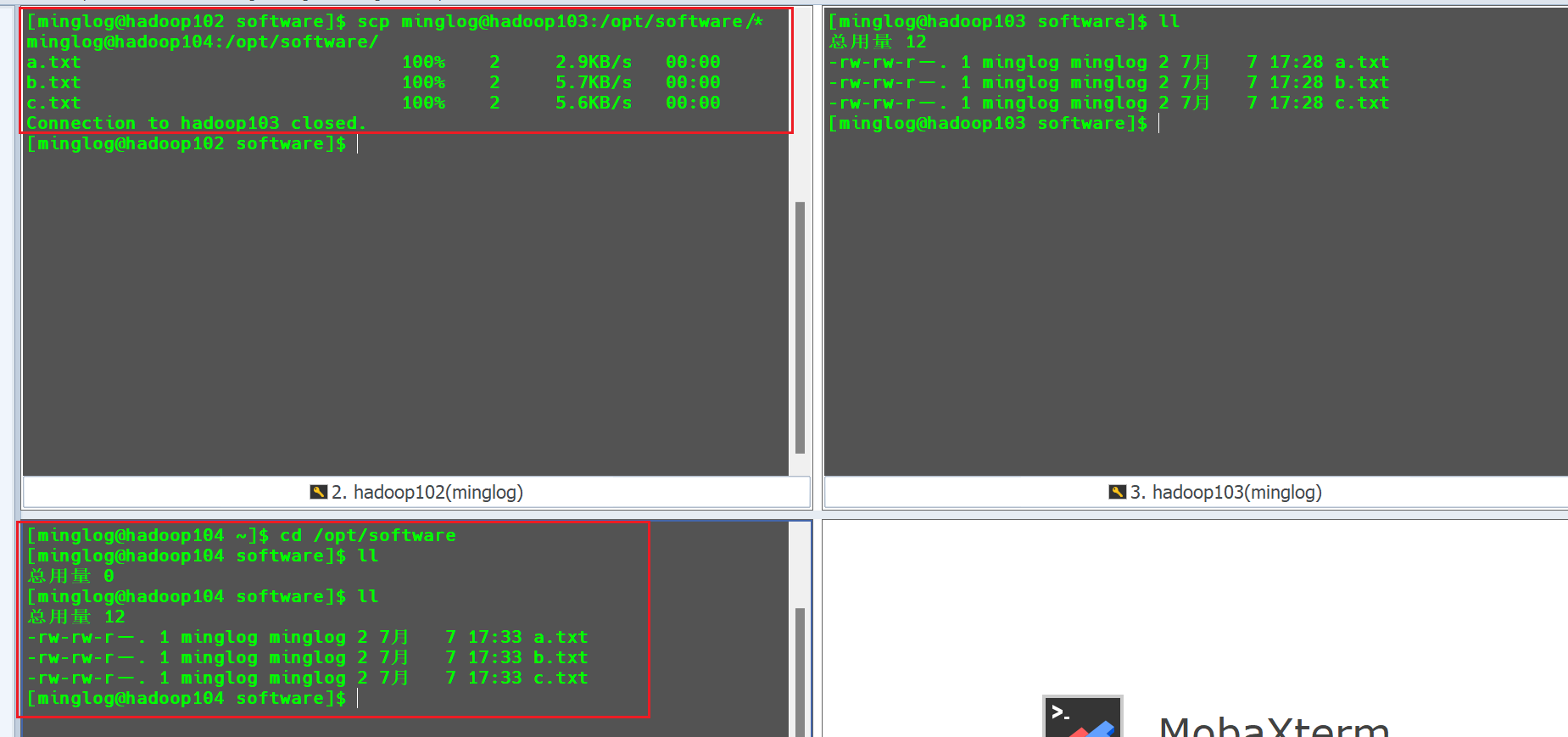
rsync远程同步工具
这里的rsync工具和scp工具不一样,scp是完全拷贝,它不会去校验这个文件是否在目的位置存在,直接拷贝过去覆盖,这样速度相对比较慢,因为每次都是重新拷贝;而rsync工具则不一样,它在拷贝是会先去校验文件是否存在,是否发送过变化,它只会把发生变化文件拷贝过去,这样拷贝的速度就相对比较快。
基本语法如下:
1 | rsync -av $pdir/$fname $user@$host:$pdir/$fname |
使用演示如下:
首先将hadoop103和hadoop104机器中的/opt/software/目录下的文件清空。
1 | rm -rf /opt/software/* |
接下来使用rsync工具将hadoop102中的文件拷贝到hadoop103。
1 | rsync -av /opt/software/* minglog@hadoop103:/opt/software/ |

传输成功。
接下来,在hadoop102中修改a.txt的内容为aaaa
1 | vim a.txt |
然后再次同步。
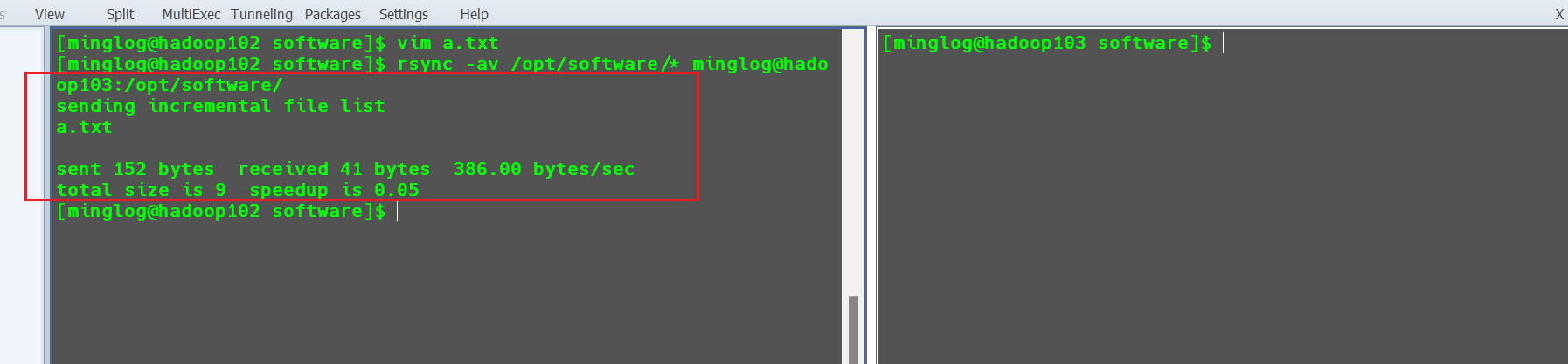
此时只会同步修改的a.txt文件,不会修改b.txt和c.txt文件。
在hadoop103中查看a.txt内容是否发生变化。
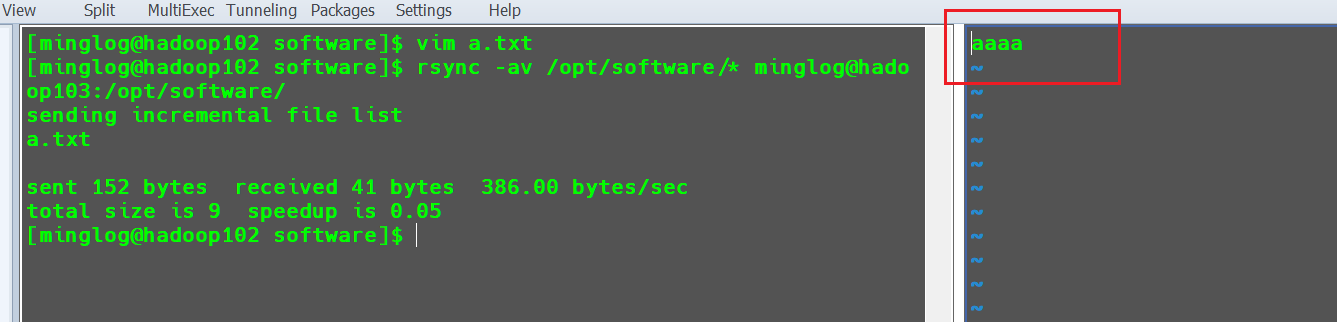
文件内容发生改变。
自写工具xsync,集群分发脚本
在rsync工具的基础上进一步开发,循环复制文件到所有节点的相同目录下。因为如果使用rsync工具,让集群中服务器的数量过多,就需要写很多次rsync命令去同步,这样显然是非常低效率。这个时候我们就需要再rsync的基础上进一步开发,使其自动将指定目录的内容分发到所有的节点。
首先,回到hadoop102节点的终端,在家目录下创建一个bin目录。
1 | mkdir ~/bin/ |
在家目录下创建一个xsync脚本
1 | vim ~/bin/xsync |
内容如下:
1 |
|
然后赋予xsync.sh脚本执行权限。
1 | chmod +x ~/bin/xsync |
然后测试脚本。将~/bin目录同步给其他节点。
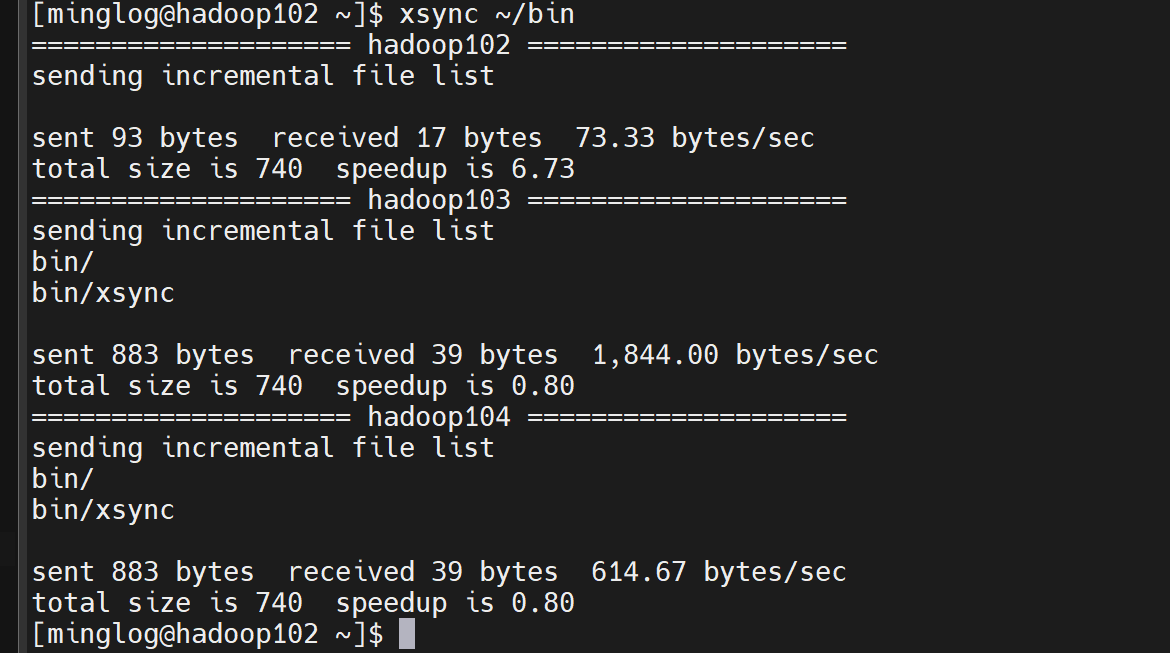
同步成功。
集群的规划与配置
集群规划
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
注意:
NameNode和SecondaryNameNode不要安装在同一台服务器ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
集群配置
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
默认配置文件
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
进入到配置文件目录
1 | cd $HADOOP_HOME/etc/hadoop |
然后按照下面的文件内容修改。
core-site.xml
1 | vim core-site.xml |
1 |
|
hdfs-site.xml
1 | vim hdfs-site.xml |
1 |
|
yarn-site.xml
1 | vim yarn-site.xml |
1 |
|
mapred-site.xml
1 | vim mapred-site.xml |
1 |
|
此外,在$HADOOP_HOME/etc/hadoop路径下还有一个文件workers,在该文件中存储了所有的节点的hostname,也需要提前配置。
1 | vim workers |
配置内容如下:
1 | hadoop102 |
分发配置文件
1 | xsync /opt/module/hadoop-3.1.3/etc/hadoop/ |
查看分发结果
在节点hadoop103中查看/opt/module/hadoop-3.1.3/etc/hadoop/workers文件内容是否发生变化。
1 | cat /opt/module/hadoop-3.1.3/etc/hadoop/workers |

分发成功。
启动集群
第一次启动集群需要在hadoop102节点上格式化NameNode。
注意:这一步只要执行一次,初始化完后,后面再次启动HDFS时不允许重复初始化。
1 | hdfs namenode -format |

注意:格式化
NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。详见2.3.2.6 常见错误。
接下来在hadoop102中启动HDFS
1 | start-dfs.sh |
第一次启动会创建相关文件夹。

启动完成后,在节点hadoop102中开启NameNode和DataNode服务,在hadoop103中会开启DataNode服务,在hadoop104中会开启DataNode和SecondaryNameNode服务,在每个节点中输入jps,可查看已运行的Java服务。
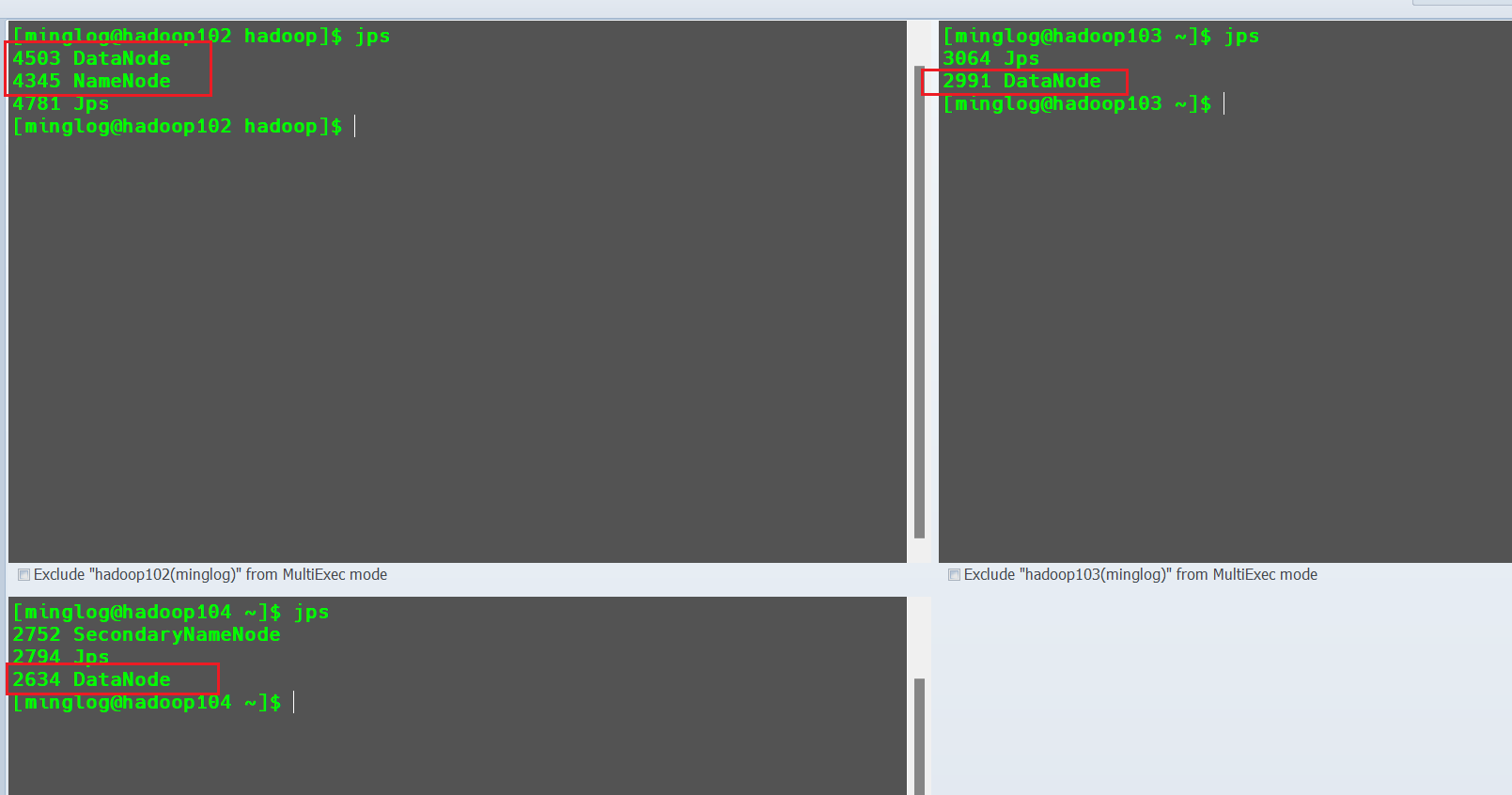
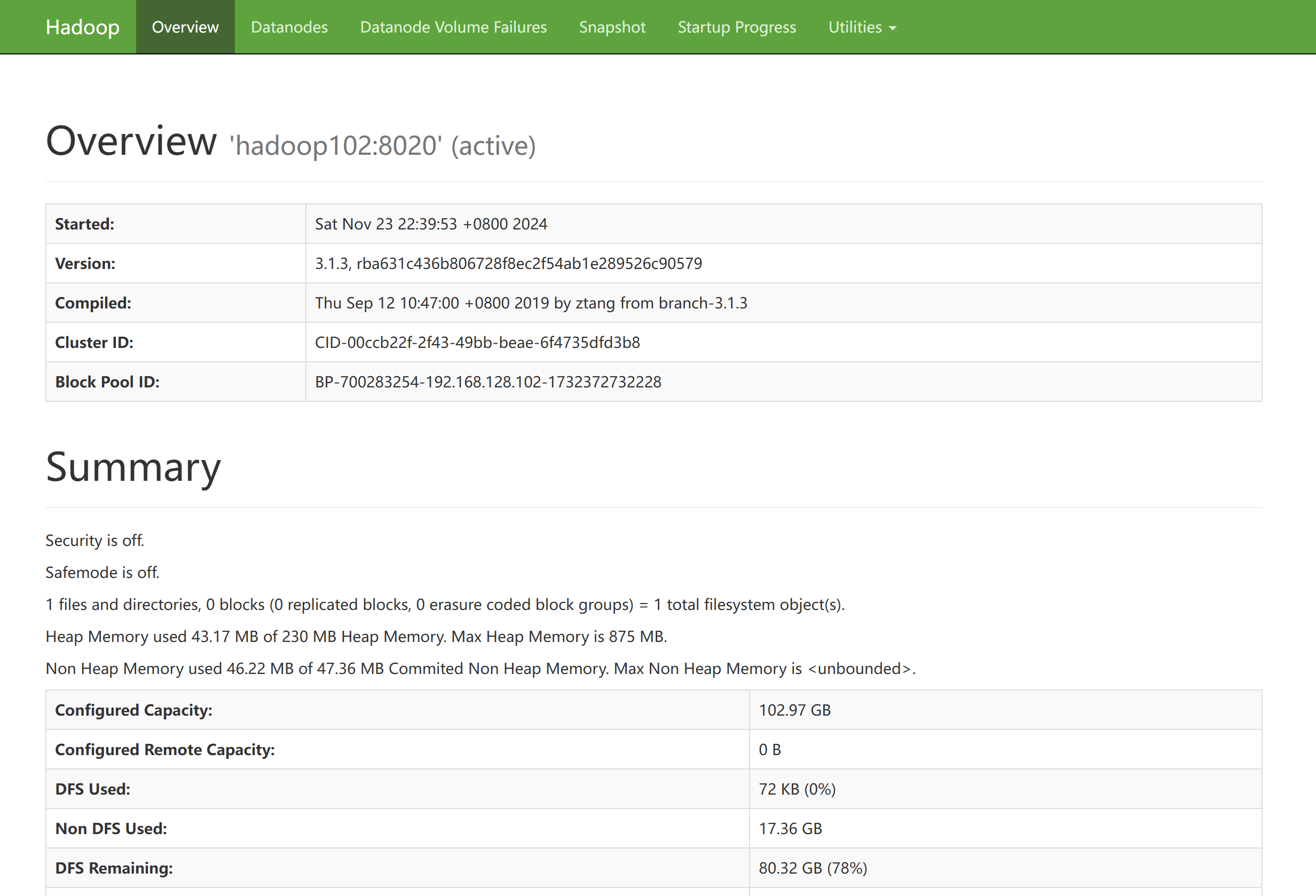
此时,HDFS服务已经开启成功。此时回到Windows主机,在浏览器中输入192.168.128.102:9870/即可进入HDFS的Web页面。
接下来去hadoop103中开启YARN服务。
1 | start-yarn.sh |

此时在hadoop103中会开启ResourceManager和NodeManager服务,在hadoop102和hadoop104中会开启NodeManager服务。
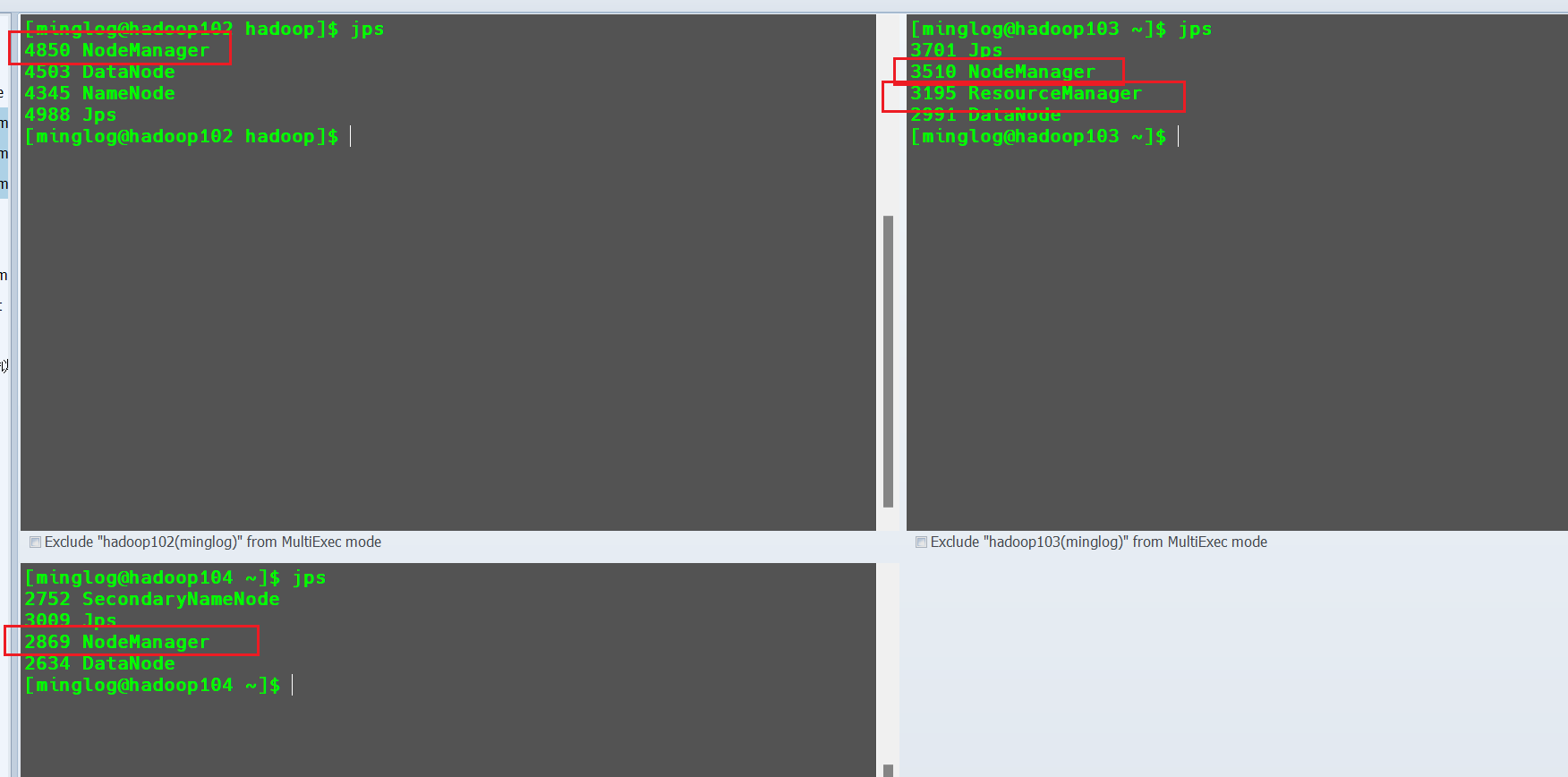
此时在Windows的浏览器中输入192.168.128.103:8088即可进入Yarn的Web页面。
至此,Hadoop已经成功启动。如果你出现了一些问题,在启动过程中报错了,你不妨看看下面的常见错误,看看有没有你的问题。
常见错误
配置错误
为了演示效果,在此我将
hdfs-site.xml中的内容修改成错误格式,如下所示。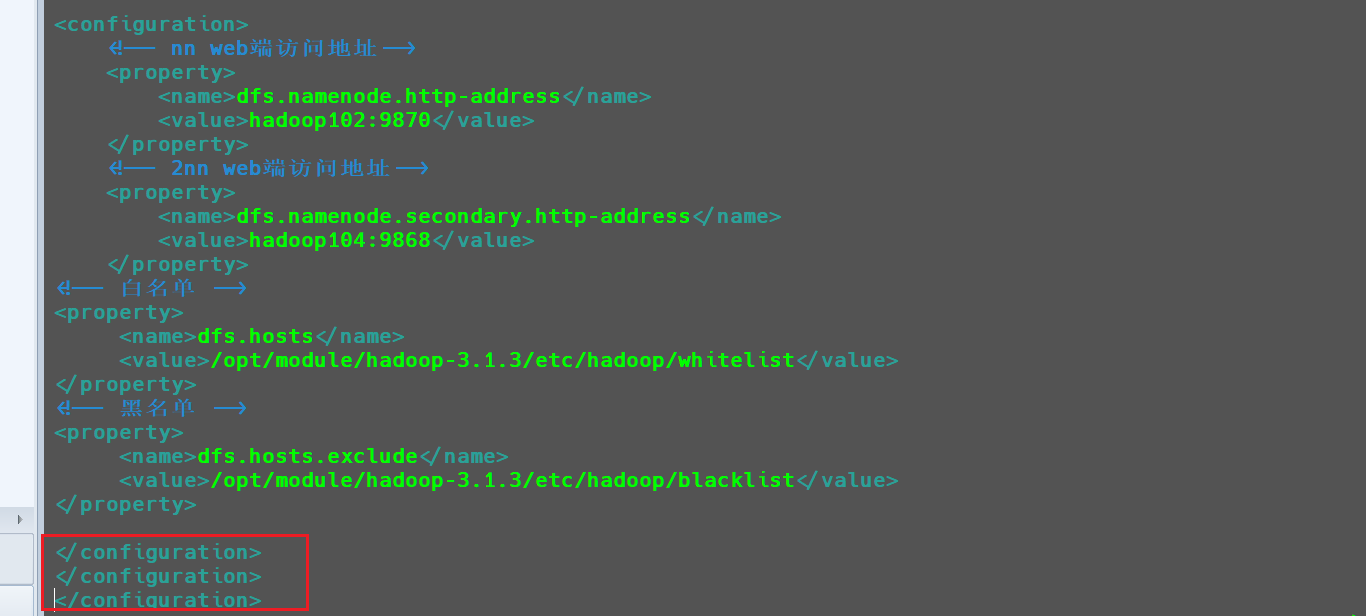
此时再次使用
start-dfs.sh开启集群服务,此时就会报错。
并且
hadoop102节点的HDFS服务也没有开启。
在此出直接报错到控制台还算是比较幸运的,有的时候报错并不显示在控制台,这个时候就需要自己去日志中查看,查看原则
哪个机器机器服务出现文件,就看哪个机器中的日志文件。例如此处的错误在日志文件中也可以看到。
1
tail -n 100 /opt/module/hadoop-3.1.3/logs/hadoop-minglog-namenode-hadoop102.log

从报错可以看出,解析
conf hdfs-site.xml错误,出现了一个额外的关闭标记符号。回到配置文件中将最后一行删除,即可恢复正常。关闭
HDFS服务后重新开启即可恢复正常。
重复初始化
NameNode重复初始化的意思是,在集群搭建完成后运行了多次
hdfs namenode -format去初始化NameNode。例如,现在我在节点
hadoop102中再次运行hdfs namenode -format。比较有代表性的特征是在控制台会提示我们输入一个
Y or N,这个时候无论输入Y还是N都会导致我们的集群出现问题。
例如我输入
Y后,再次使用以下命令去启动集群。1
start-dfs.sh
这个时候虽然看着没有问题,但是输入
jps后可以看到DataNode服务没有成功开启。
输入以下命令查看日志
1
tail -n 100 /opt/module/hadoop-3.1.3/logs/hadoop-minglog-datanode-hadoop102.log

可以看到报错为
NameNode和DataNode的clusterID不一致。解决办法是,重启所有机器后删除所有节点下的
$HADOOP_HOME下的data和logs文件夹。然后再次初始化
NameNode。为了方便删除所有节点的
data和logs文件夹,我们编写以下脚本实现。1
2
3
4
5
6
7
8
9
for host in hadoop102 hadoop103 hadoop104
do
ssh $host rm -rf /opt/module/hadoop-3.1.3/data
ssh $host rm -rf /opt/module/hadoop-3.1.3/logs
ssh $host sudo rm -rf /tmp/*
echo "================$host Clearing.=============="
done给脚本命名为
hclear,并放入/opt/module/hadoop-3.1.3/bin目录下(因为该目录具有执行权限)。1
mv hclear /opt/module/hadoop-3.1.3/bin
然后赋予执行权限
1
chmod +x /opt/module/hadoop-3.1.3/bin/hclear
运行
hclear脚本。1
hclear

然后查看
$HADOOP_HOME目录,相关目录是否删除。1
ll $HADOOP_HOME

data和logs目录删除成功。然后重启所有节点
1
2
3ssh hadoop103 sudo reboot
ssh hadoop104 sudo reboot
ssh hadoop102 sudo reboot重新执行
NameNode初始化。1
hdfs namenode -format

初始化成功。
编写Hadoop集群常用脚本
回到
Hadoop102节点中,输入以下命令开始编写脚本。1
vim ~/bin/myhadoop
输入以下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " ======启动 hadoop集群 ======="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo "------------ 启动HistoryServer -----------"
ssh hadoop102 "mapred --daemon start historyserver"
;;
"stop")
echo " ==========关闭 hadoop集群 ========="
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
echo "------------ 关闭HistoryServer -----------"
ssh hadoop102 "mapred --daemon stop historyserver"
;;
*)
echo "Input Args Error..."
;;
esac然后赋予执行权限
1
chmod +x ~/bin/myhadoop
执行以下命令使用
myhadoop关闭集群。1
myhadoop stop

再输入以下命令启动集群
1
myhadoop start
集群启动成功。
查看所有节点的
Java进程脚本jpsall。1
vim ~/bin/jpsall
输入以下内容:
1 |
|
然后赋予执行权限
1 | chmod +x ~/bin/jpsall |
使用以下命令查看所有集群的Java进程运行状态。
1 | jpsall |
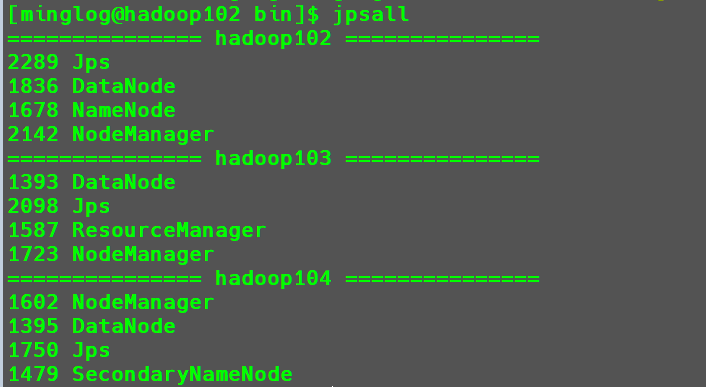
执行成功。
配置本地电脑的hosts文件
我们想在本地的电脑中输入hadoop103:8088访问YARN的页面,由于现在电脑并不知道hadoop103对应的是哪个IP地址,所以此时无法访问页面。
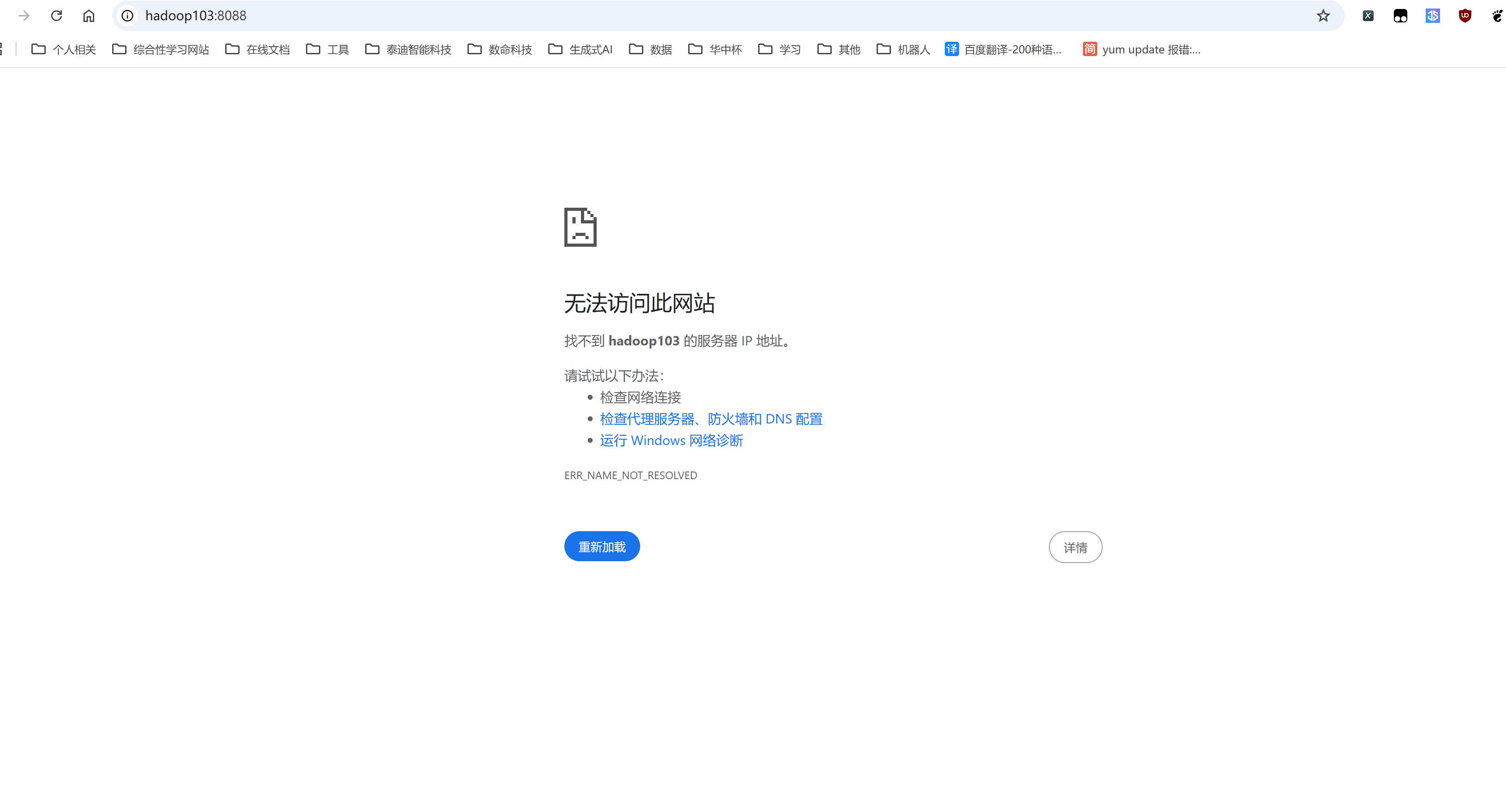
解决的办法久是修改本地电脑的DNS解析。
在文件浏览器中打开目录C:\Windows\System32\drivers\etc
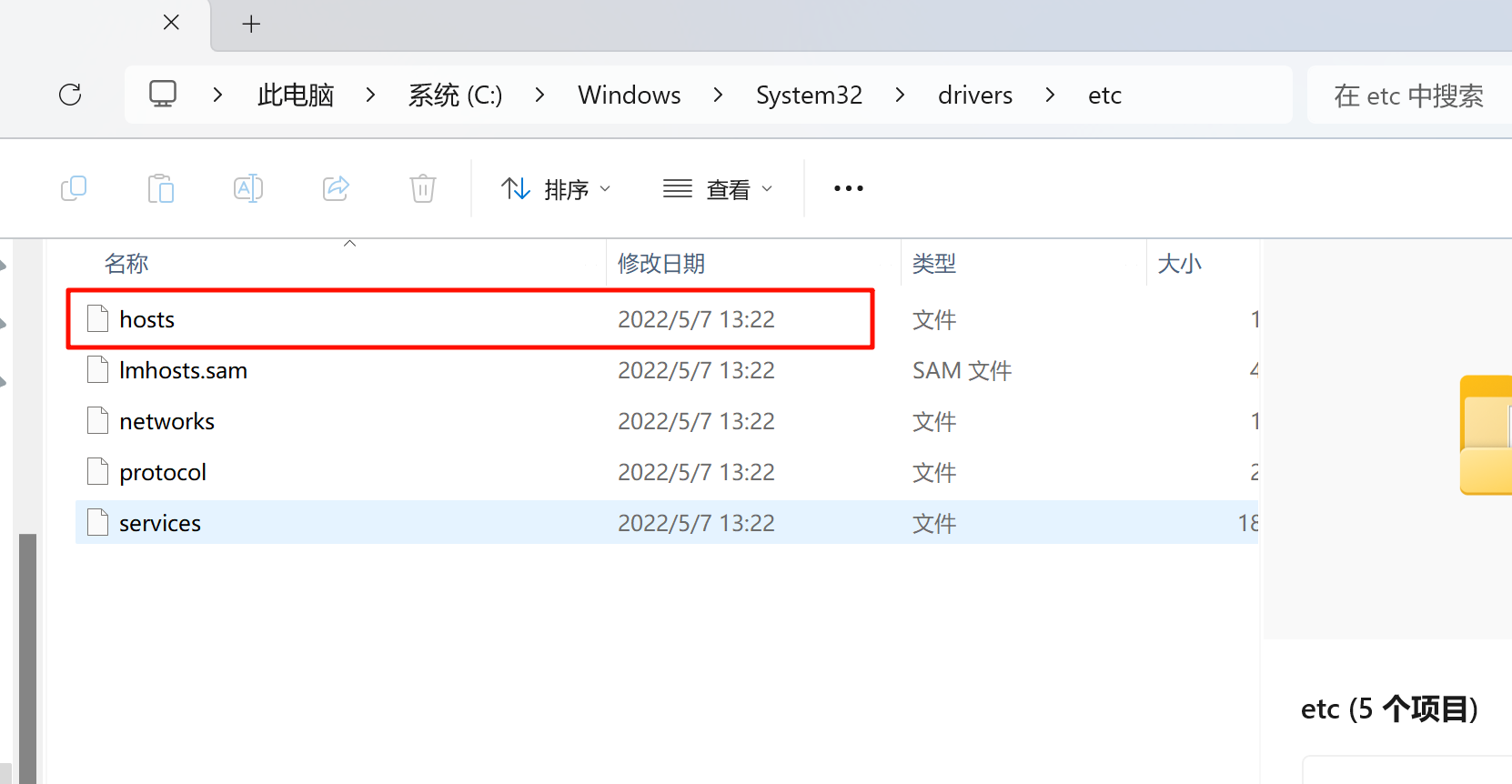
选中hosts文件复制到桌面。
然后右键桌面上的hosts文件点击在记事本中编辑。
在文件中粘贴以下内容后保存。
1 | 192.168.128.100 hadoop100 |
然后将桌面上的这个hosts文件复制回C:\Windows\System32\drivers\etc,选择替换原来的文件。

这个时候再次进入到hadoop103:8088即可看到YARN的Web页面。
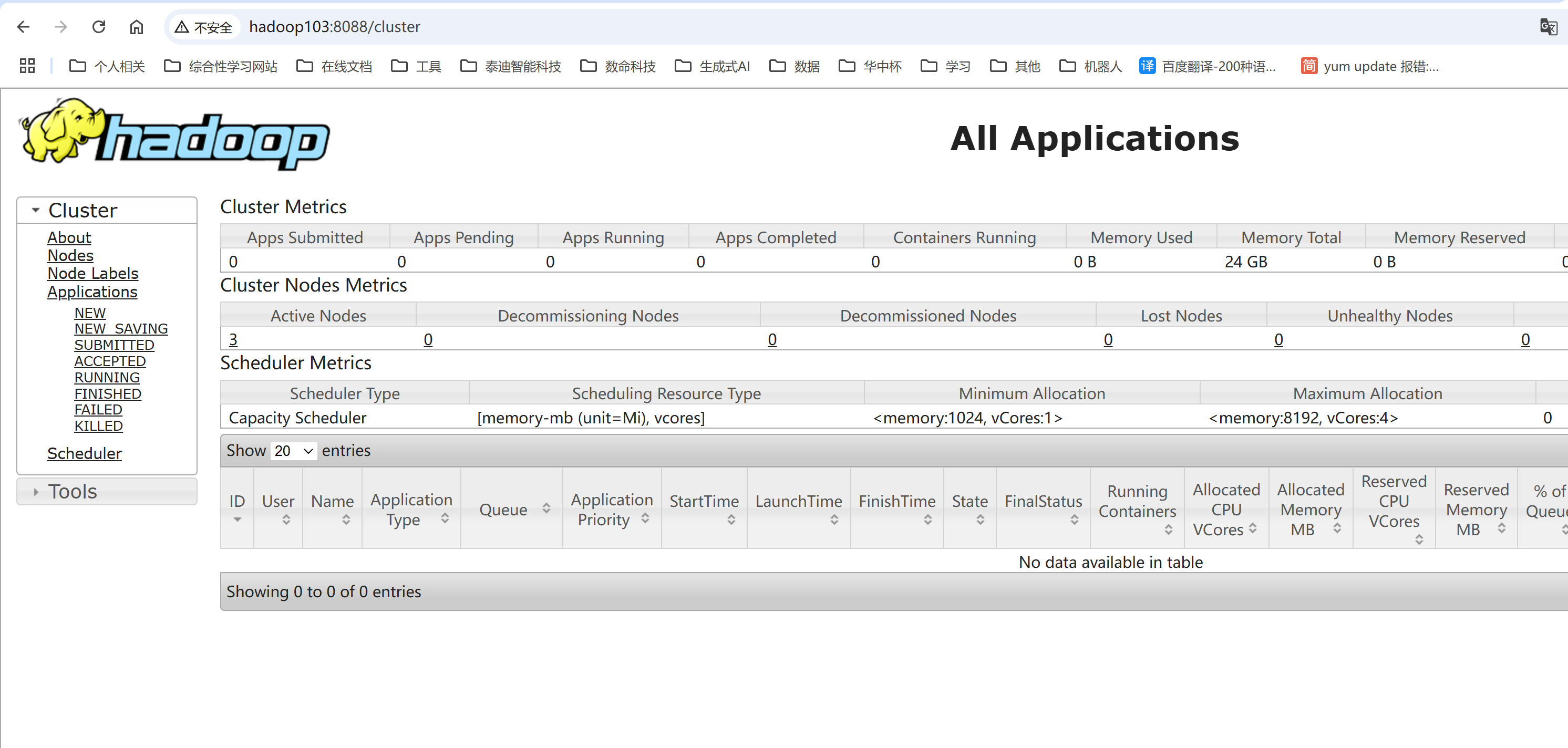
接下来查看相关服务的WEB页面,并演示其简单功能。
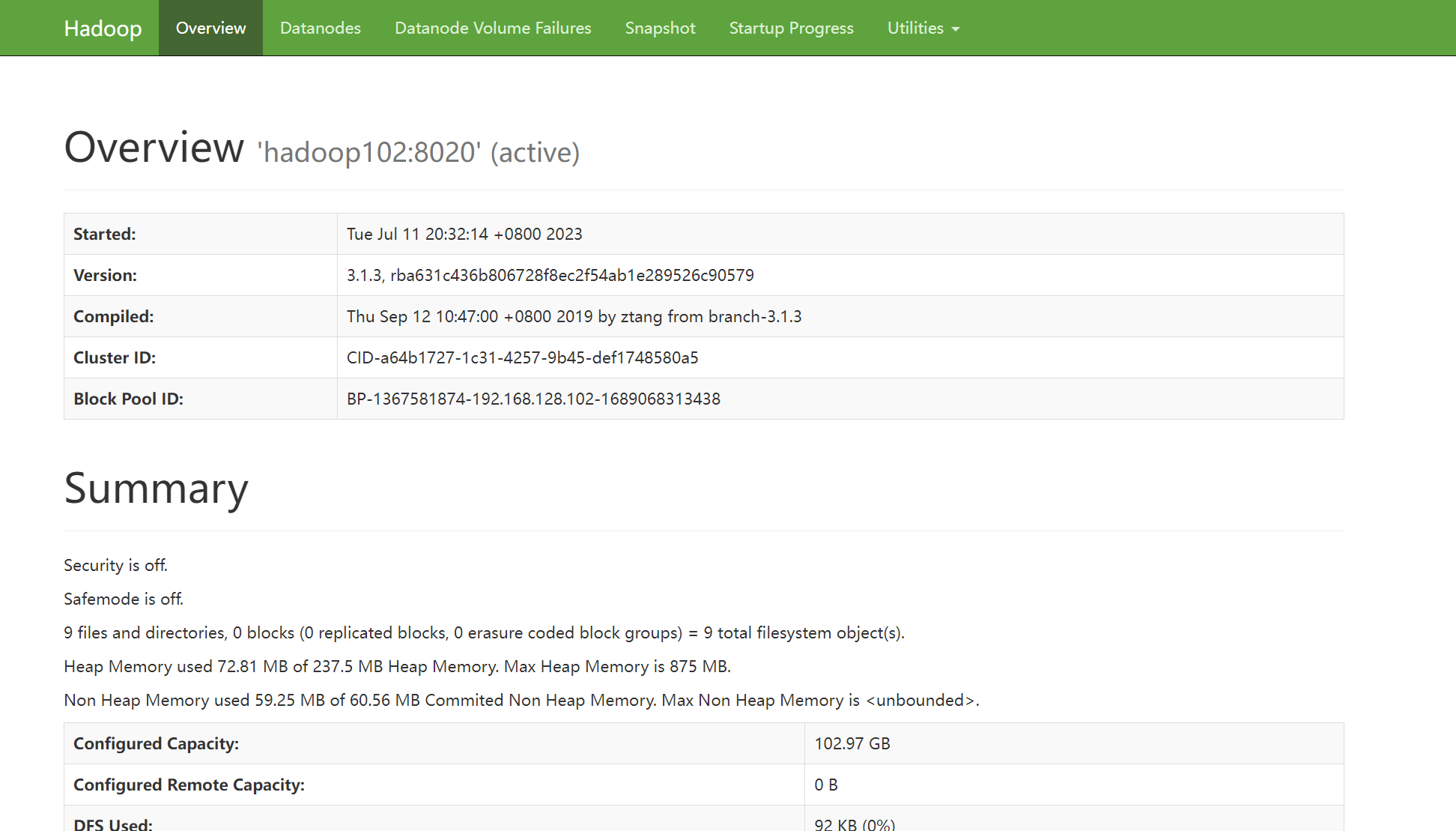
HDFS的WEB页面简单操作
HDFS页面也可以正常访问。打开HDFS Web页面
点击文件浏览器
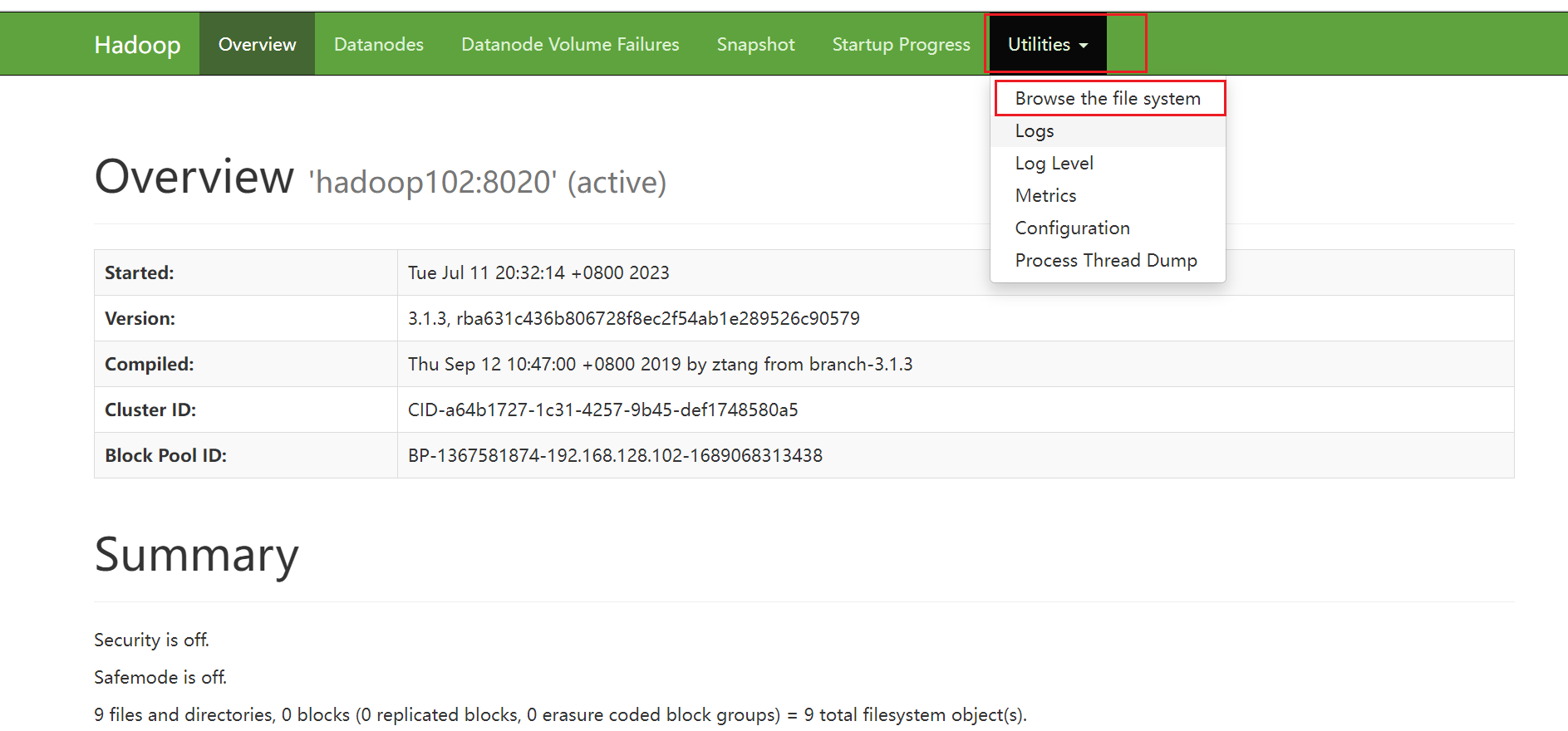
在根目录下创建input文件夹
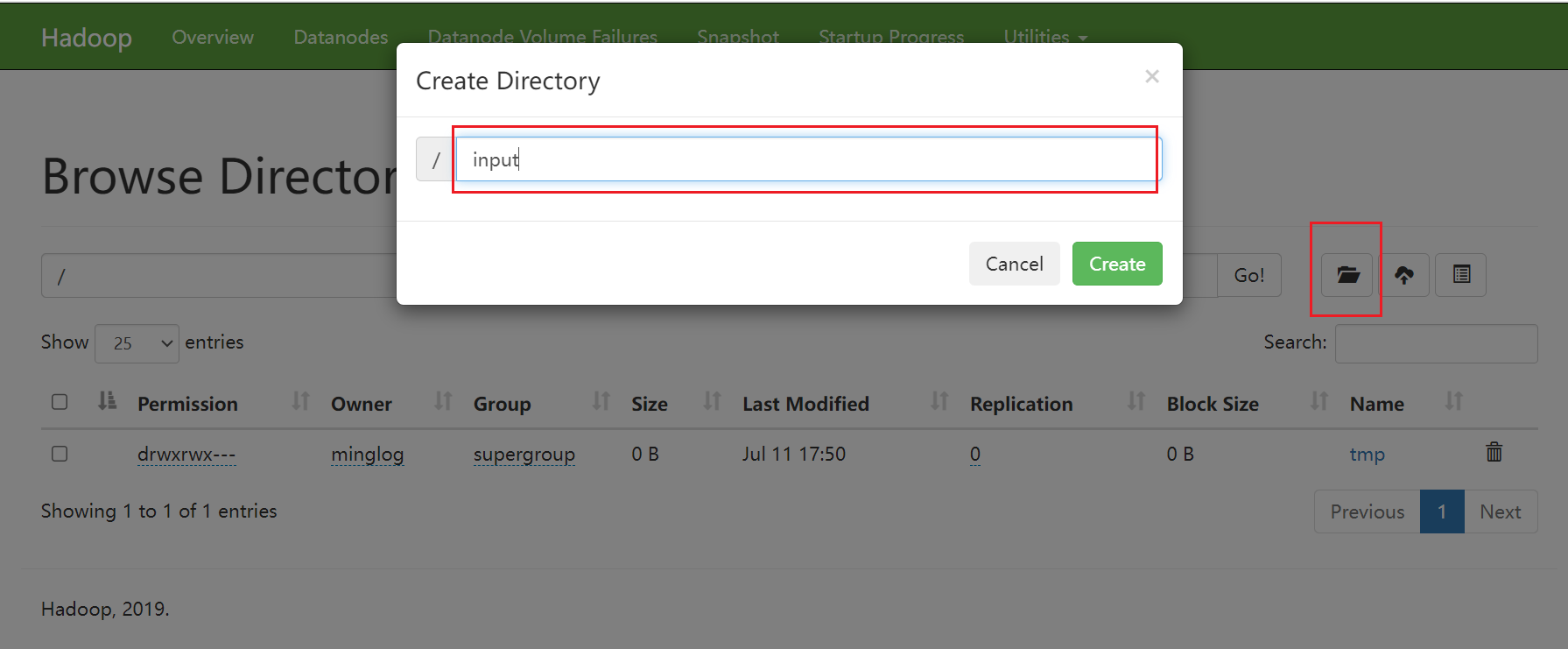
然后进入到/input文件夹,并上传文件到该文件夹下。
随便编辑几个文本文件上传到该文件夹下,上传的文件将用于后续执行WordCount任务。
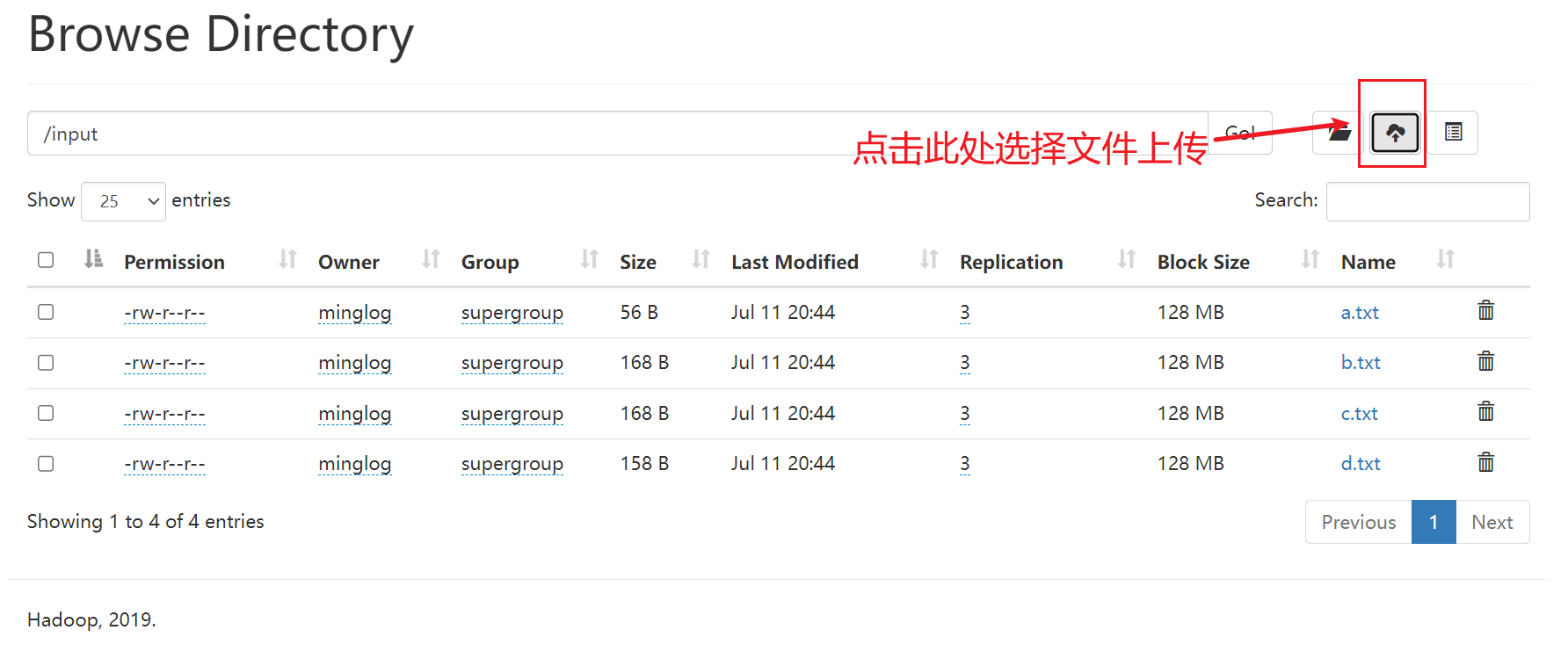
全部没问题后,可以将刚刚编写的两个脚本同步到其他节点
1 | xsync ~/bin/ |
配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
配置mapred-site.xml
修改mapred-site.xml配置文件
1 | vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml |
增加以下内容:
1 | <!-- 历史服务器端地址 --> |
分发配置。
1 | xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml |
在hadoop102节点中启动历史服务器。
1 | mapred --daemon start historyserver |
查看历史服务器是否启动。
1 | jps |
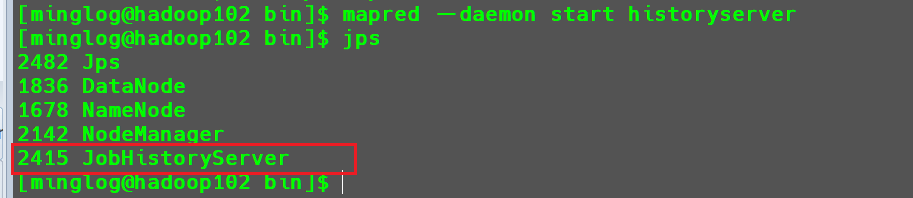
历史服务器启动成功。
在该网址下可以查看对应的页面内容。
配置日志聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
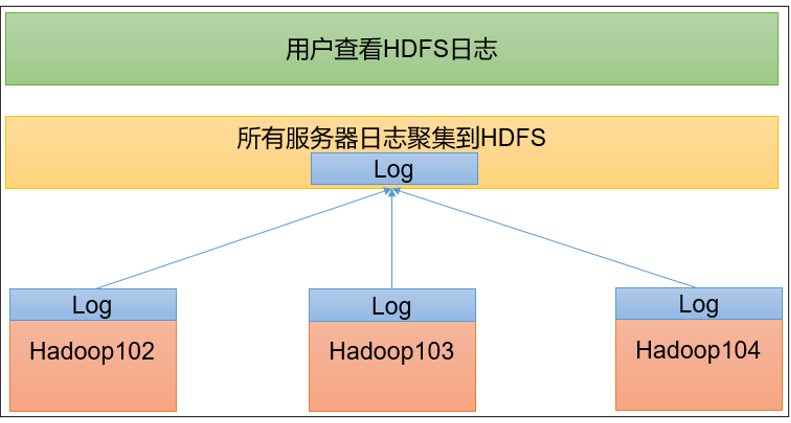
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动
NodeManager、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
修改yarn-site.xml配置
1 | vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml |
增加以下内容:
1 | <!-- 开启日志聚集功能 --> |
分发配置
1 | xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml |
重新启动Hadoop集群。
1 | myhadoop stop |
完毕完成后重新启动。
1 | myhadoop start |
如果集群中运行过任务,则需要执行以下代码删除HDFS中的输出文件。如果没有运行过任务可跳过此步骤。
1 | hadoop fs -rm -r /output |
使用集群执行WordCount任务
1 | cd /opt/module/hadoop-3.1.3/ |
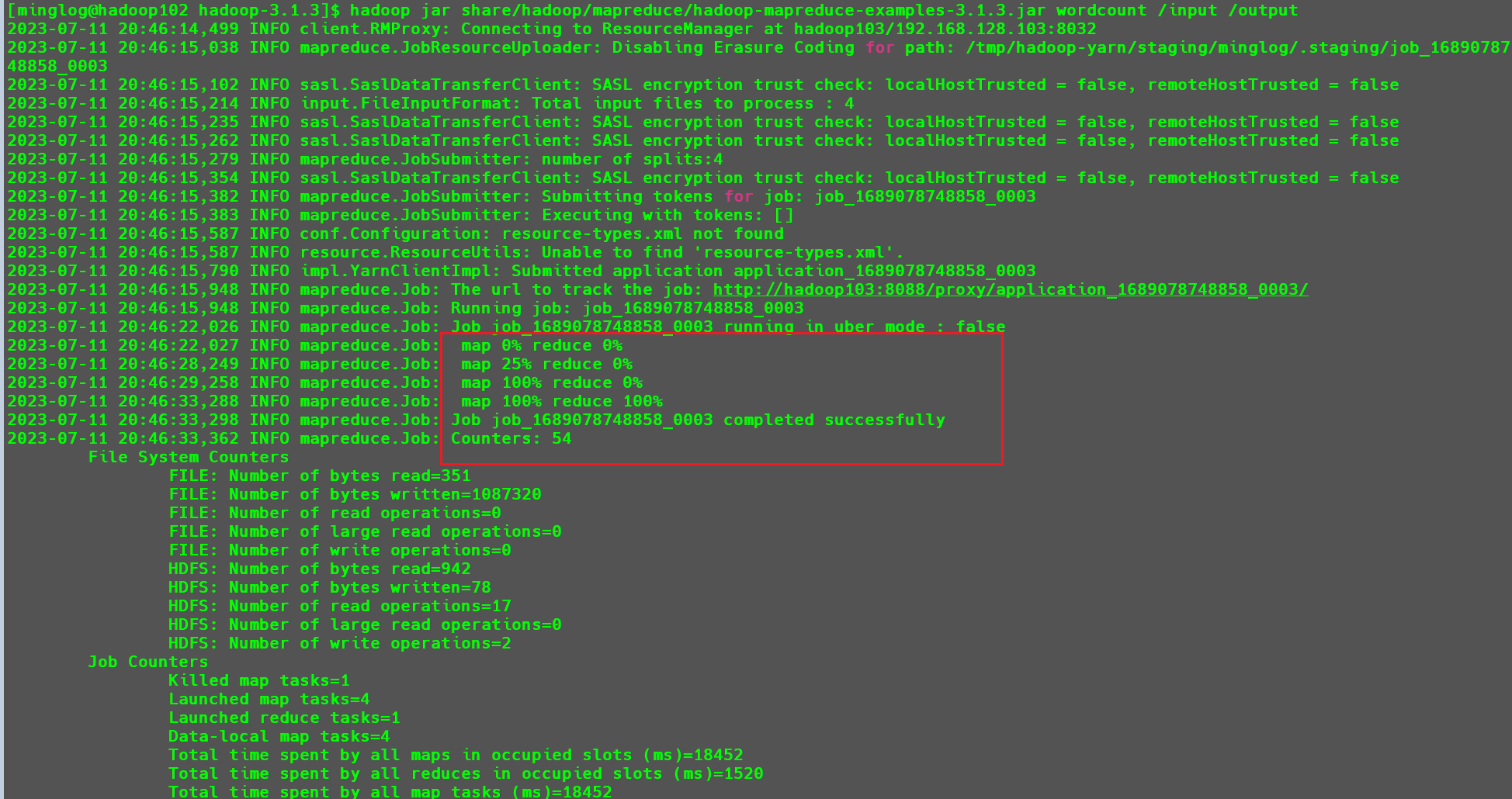
任务执行成功,在HDFS下即可生成一个output文件夹,任务执行的结果存放在该文件夹下。
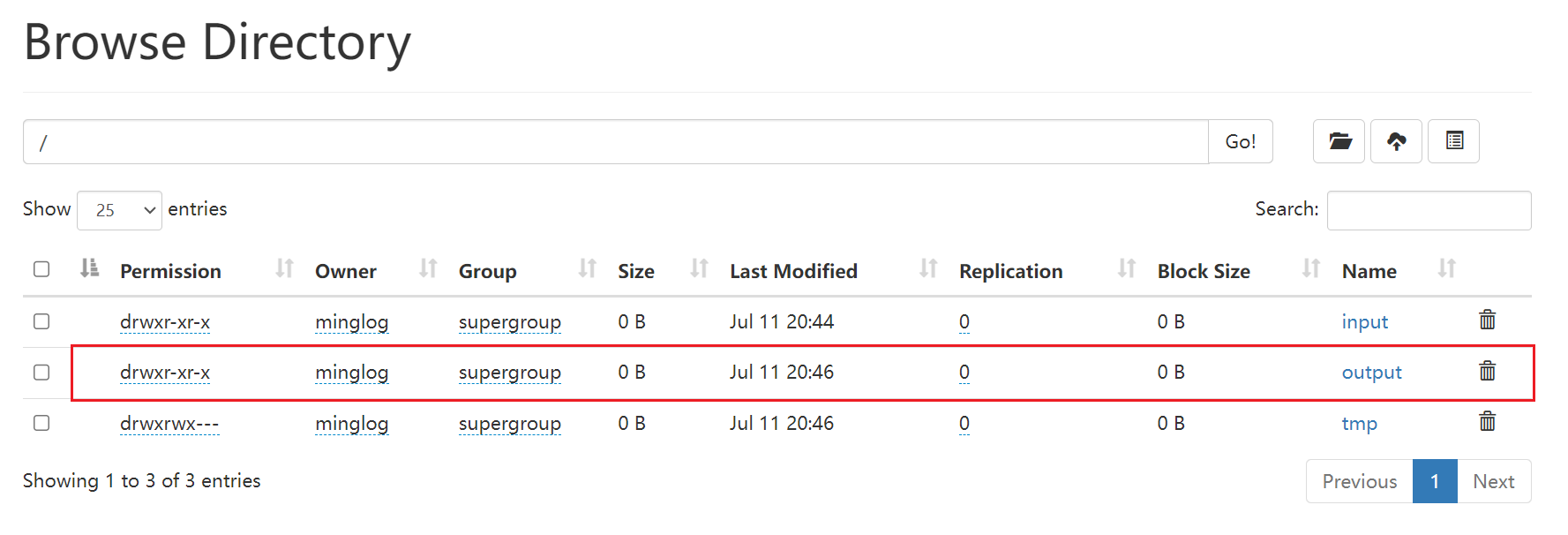
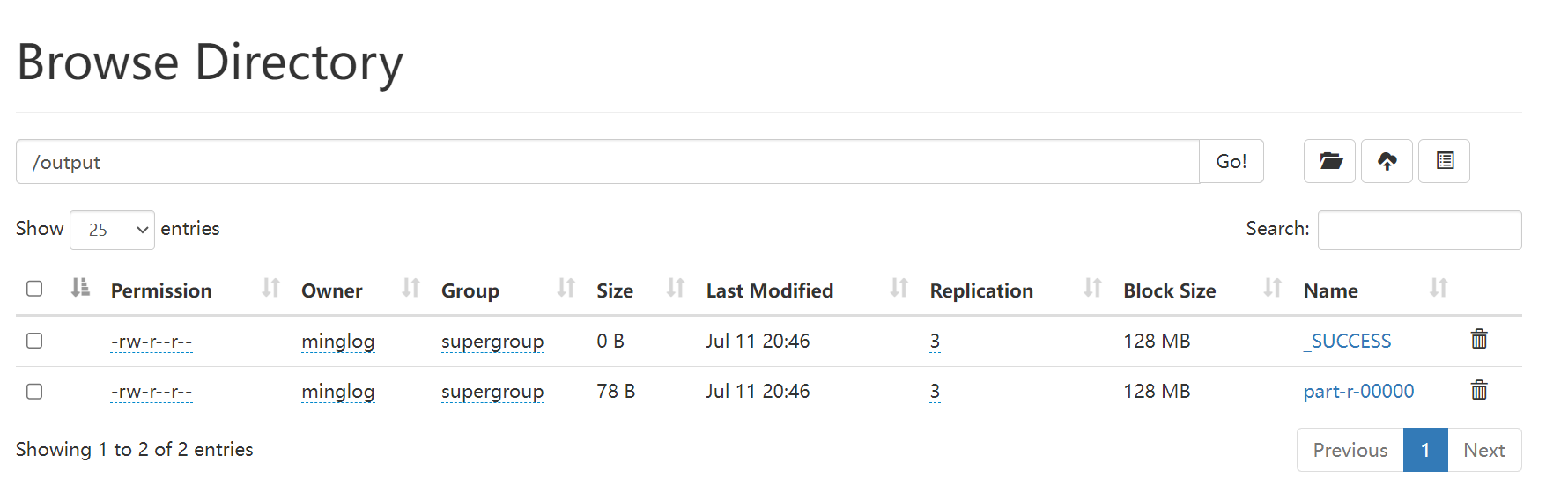
使用命令查看文件内容。
1 | hdfs dfs -cat /output/part-r-00000 |

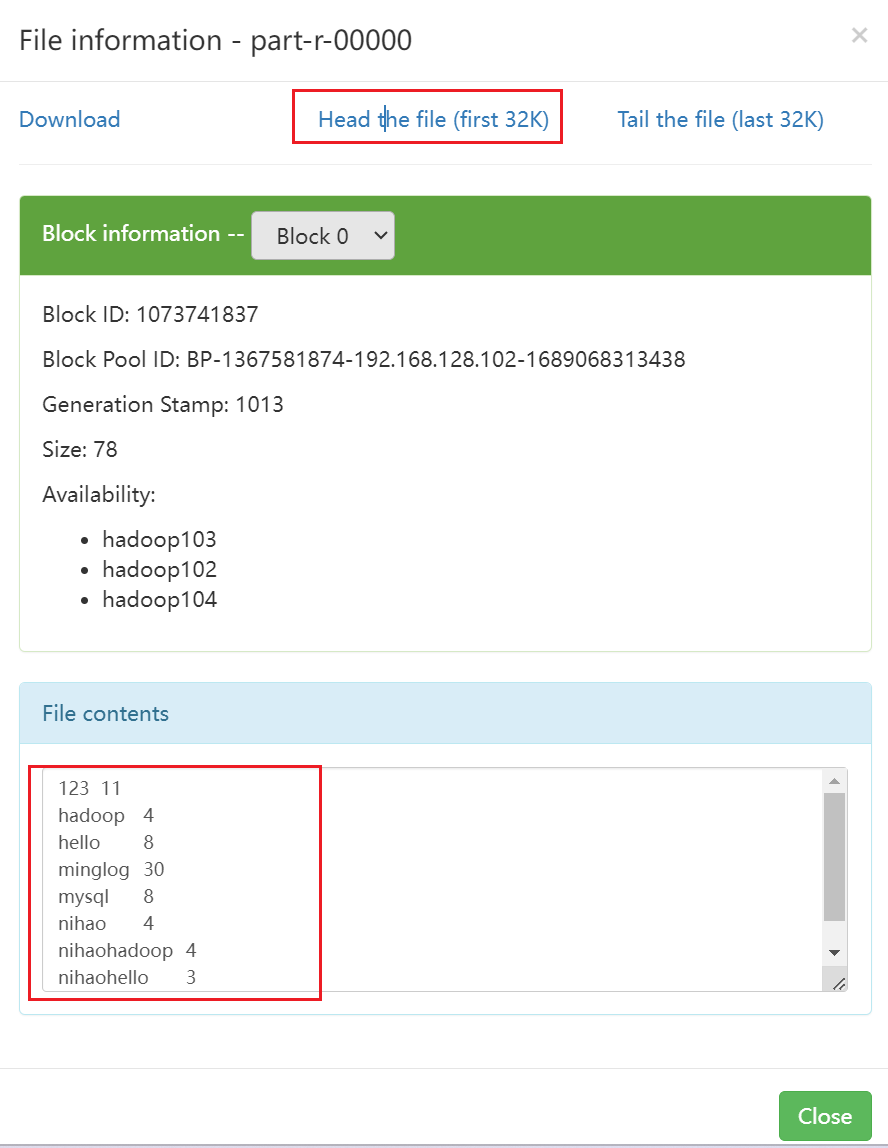
除了可以使用命令查看,还可以在HDFS Web界面中点击文件查看。
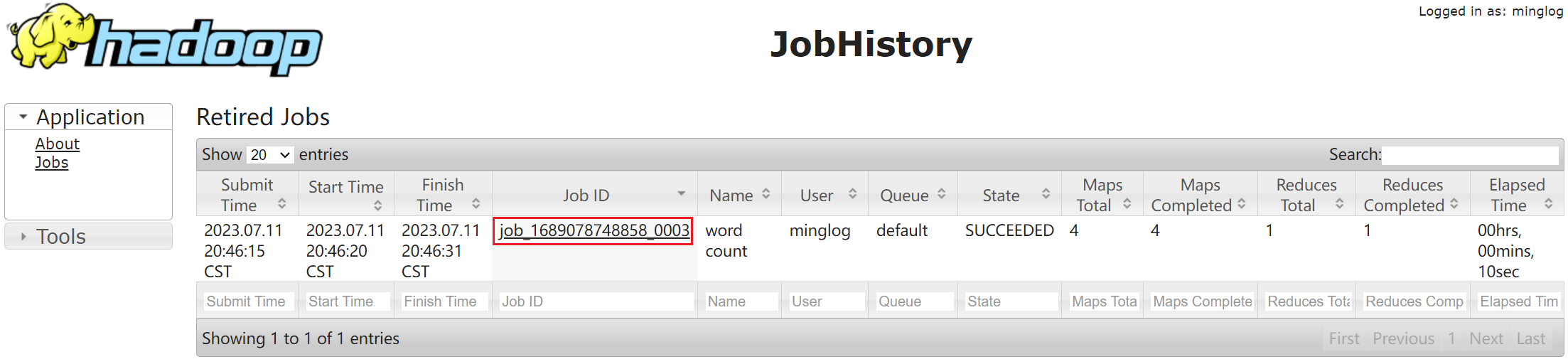
此时再次查看历史任务,即可看到刚刚执行的WordCount任务。
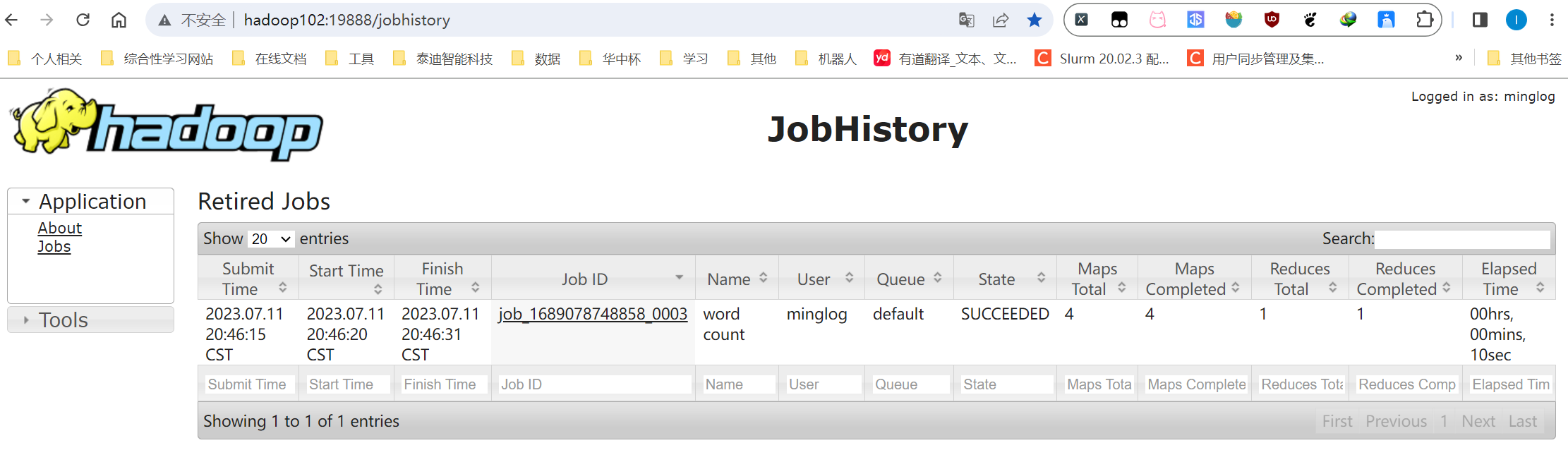
点击Job ID即可进入该任务详情。
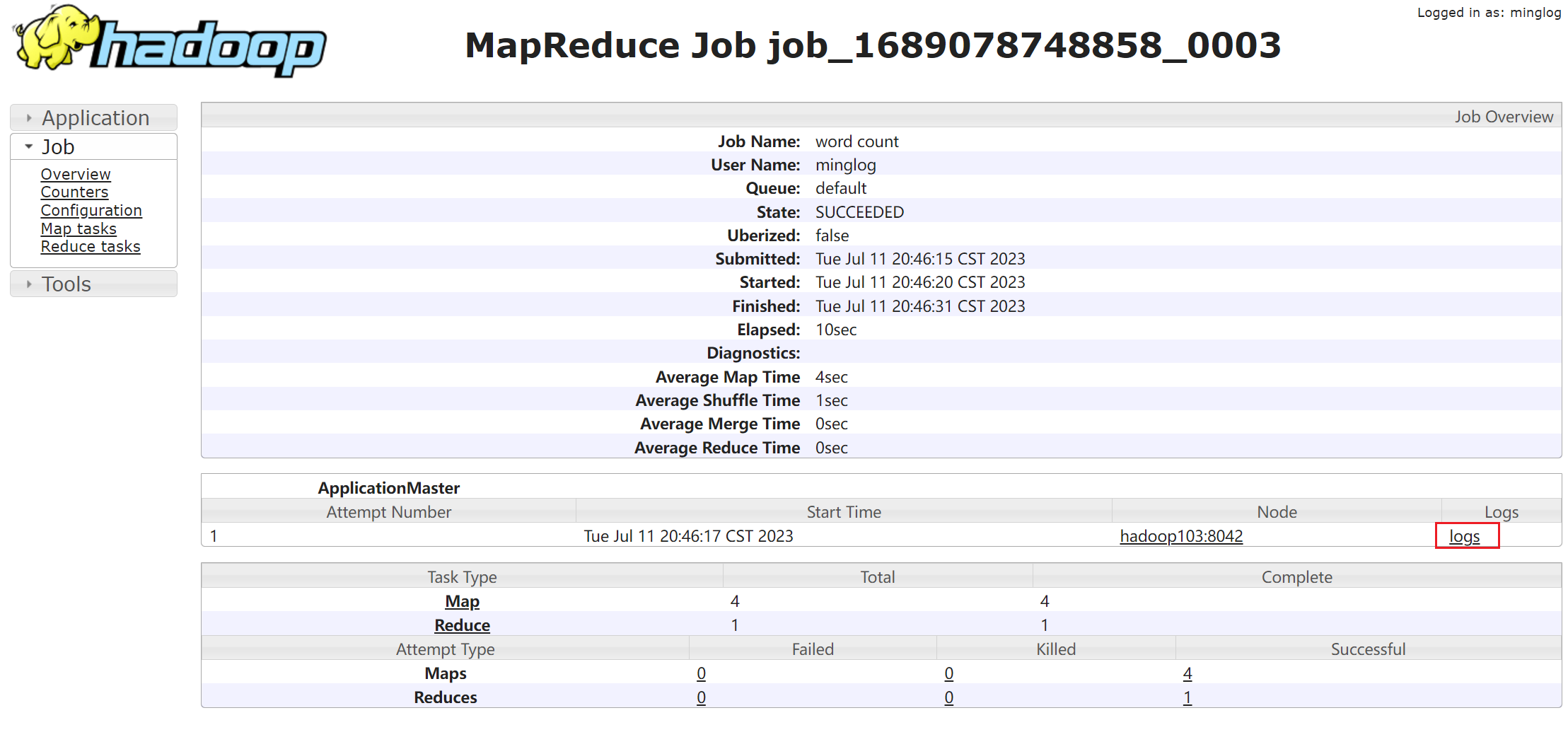
继续点击Logs还可查看该任务的日志。
集群时间同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同步。
需求
找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,生产环境根据任务对时间的准确程度要求周期同步。测试环境为了尽快看到效果,采用1分钟同步一次。

时间服务器配置
查看hadoop102服务状态和开机自启动状态(如果开着就关掉)
1
2sudo systemctl status ntpd
sudo systemctl is-enabled ntpd修改
hadoop102的ntp.conf配置文件1
sudo vim /etc/ntp.conf
首先,授权
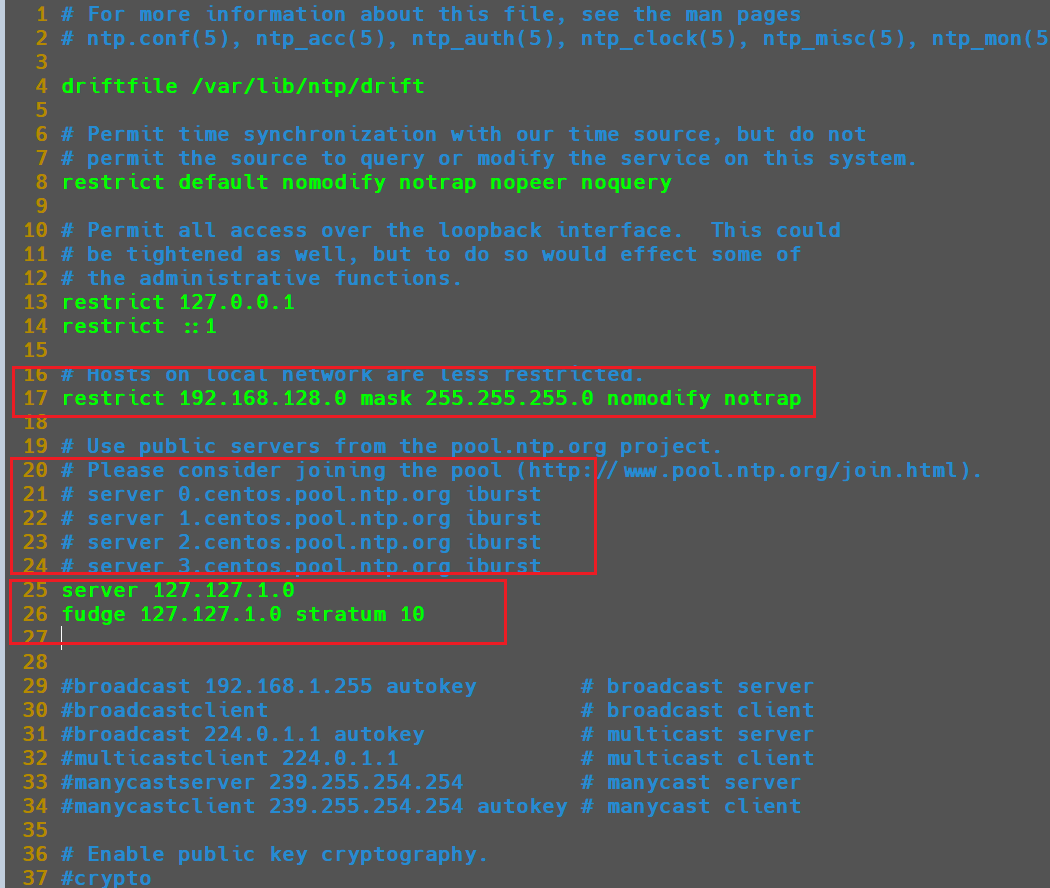
192.168.128.0-192.168.128.255网段上的所有机器可以从这台机器上查询和同步时间)将
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap修改为以下内容:1
restrict 192.168.128.0 mask 255.255.255.0 nomodify notrap
然后,设置集群不使用其他互联网上的时间
将以下几行内容注释。
1
2
3
4#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst最后设置,当网络连接丢失时,依然使用本地时间作为时间服务器为集群中的其他节点提供时间同步。
添加以下内容:
1
2server 127.127.1.0
fudge 127.127.1.0 stratum 10修改的配置文件内容见下图所示。
修改
hadoop102的/etc/sysconfig/ntpd文件1
sudo vim /etc/sysconfig/ntpd
增加以下内容:
1
SYNC_HWCLOCK=yes
重新启动
ntpd服务,并设置开机自启。1
2sudo systemctl start ntpd
sudo systemctl enable ntpd至此,
hadoop102节点配置完毕。其他节点配置。
关闭所有节点上
ntp服务和自启动1
2
3
4
5ssh hadoop103 sudo systemctl stop ntpd
ssh hadoop103 sudo systemctl disable ntpd
ssh hadoop104 sudo systemctl stop ntpd
ssh hadoop104 sudo systemctl disable ntpd在其他机器配置1分钟与时间服务器同步一次
1
2ssh hadoop103
sudo crontab -e添加以下内容
1
*/1 * * * * /usr/sbin/ntpdate hadoop102
继续配置
hadoop104节点。1
2ssh hadoop104
sudo crontab -e同样添加以下内容
1
*/1 * * * * /usr/sbin/ntpdate hadoop102
接下来将
hadoop104的节点时间进行修改1
sudo date -s "1991-11-11 11:11:11"

过1分钟后再次查看,发现时间自动修改了。

时间服务器配置成功。
至此,集群的基本搭建工作完成。