HDFS概述
HDFS产生的背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
HDFS优缺点
HDFS有三大优点:
高容错性:
HDFS在存储数据的时候可以进行备份,备份多个副本,这样一台机器中的数据出现了问题,还可以从其他机器自动拷贝过来,这种机制极大的提高了HDFS的容错性。HDFS默认的副本数量为3。在
HDFS Web界面可以看出来。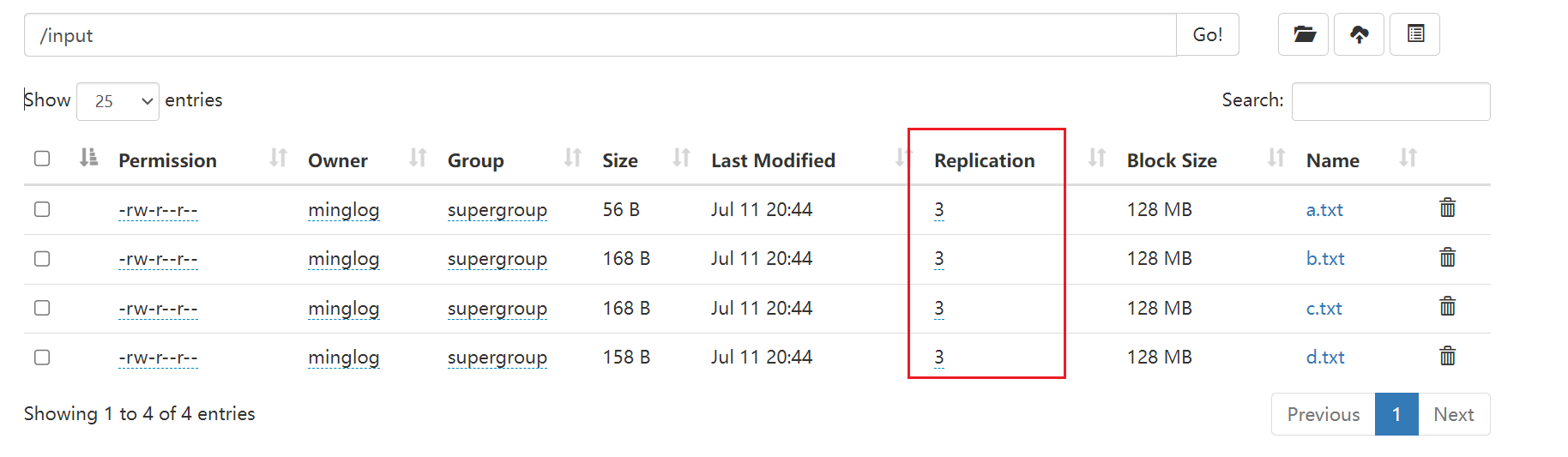
适合处理大数据
数据规模:能够处理数据规模达到
GB、TB甚至是PB级别的数据。文件规模:能够处理百万规模以上的文件数量,数量相当之大。
可构建在廉价的机器上,通过多副本机制,提高可靠性。
同样,HDFS也有三大缺点:
- 不适合低延迟数据访问,比如毫秒级别的存储数据,是做不到的。
- 无法高效的对大量小文件进行存储。每存储一个文件,在
NameNode服务中会占用一定的内存(约为4KB)用来存储数据存储的位置信息。由于NameNode的内存是有限的,这样是不可取的。小文件的寻址时间会超过读取时间,这样违反了HDFS的设计目标。 - 不支持并发写入、文件随机修改。
HDFS组成架构
HDFS有四大组成部分:
NameNode:就是Master,它是一个主管、管理者。- 管理
HDFS的名称空间。 - 配置副本策略。
- 管理数据块(Block)的映射信息。
- 处理客户端读写请求。
- 管理
DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作。- 存储实际的数据块。
- 执行数据块的读/写操作。
Client:就是客户端。- 文件切分。文件上传
HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传。 - 与
NameNode交互,获取文件的位置信息。 - 与
DataNode交互,读取或写入数据。 Client提供一些命令来管理HDFS,比如NameNode格式化。Client可以通过一些命令来访问HDFS,比如对HDFS增删改查操作。
- 文件切分。文件上传
SecondaryNameNode:并非NameNode的备份。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。- 辅助
NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode。 - 在紧急情况下,可辅助恢复
NameNode。
- 辅助
HDFS文件块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2.x和3.x版本中是128M,1.x中是64M。
这个在Web界面中也可以看出来。
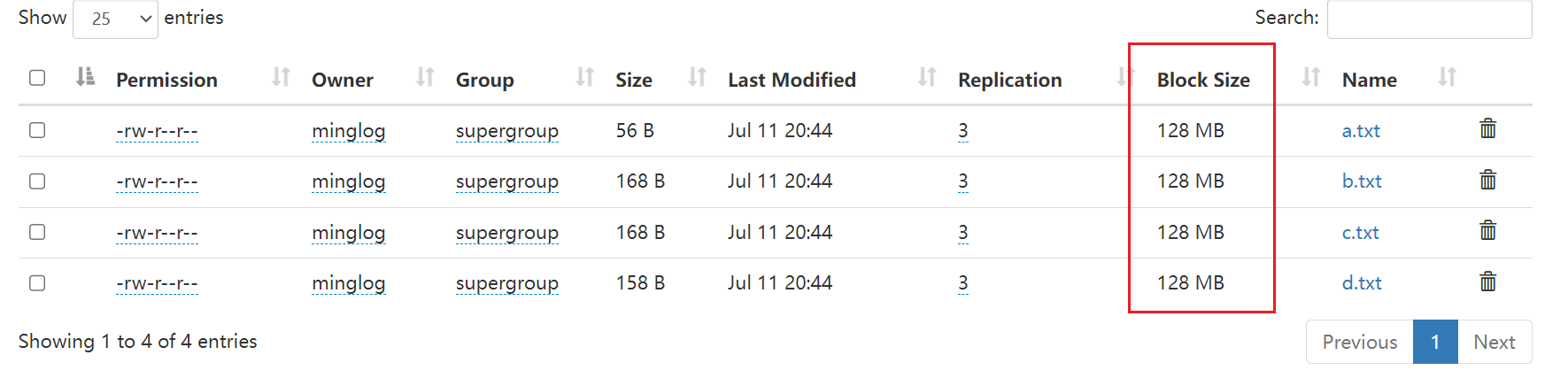
当文件大小小于128M时,存储为单个文件块,但是并不会占用整个块的128M的空间,这个128M相当于是一个上限的意思。
当文件大小超过128M时,会被切分为多个块。
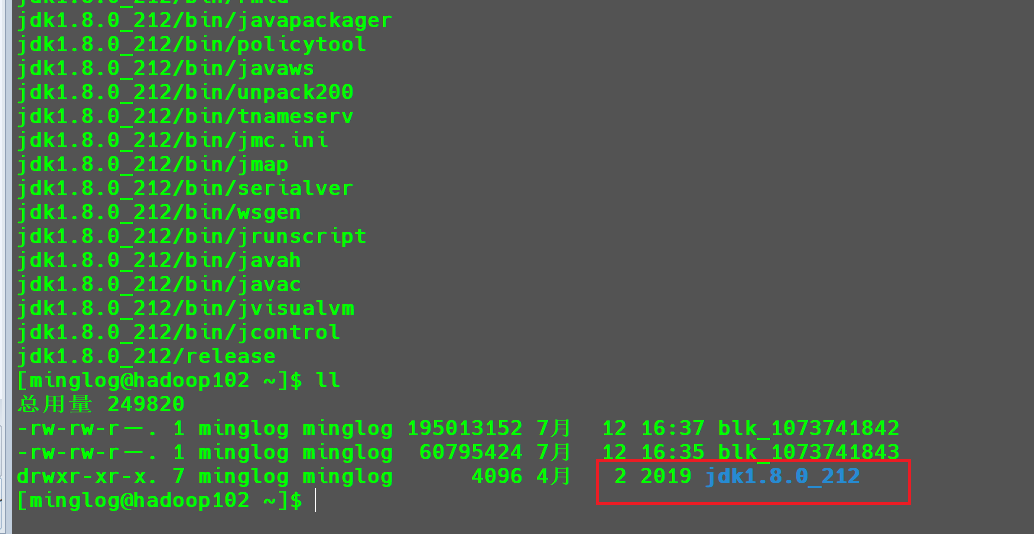
例如上传Java JDK的压缩包到HDFS中,可以看到它被切分为了2个Block,分别为Block0和Block1。
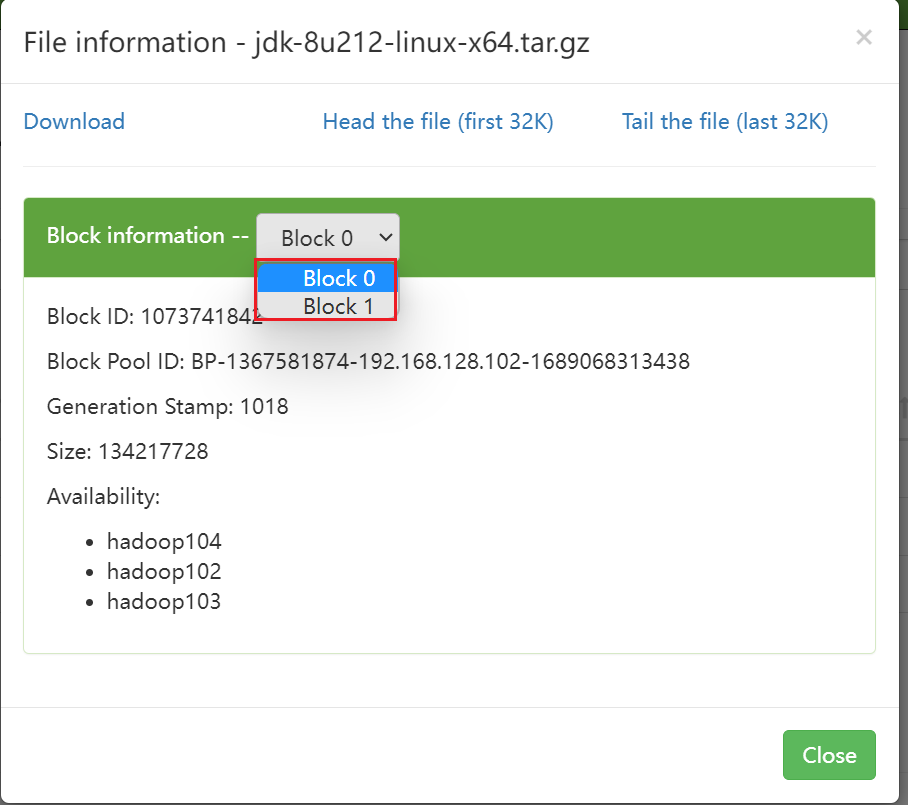
Web界面中的内容,在对应的机器中也可以直接找到。目录有点长,不同的机器可能具体内容稍有差别,大致的位置一致,请仔细检查。
1 | cd /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1367581874-192.168.128.102-1689068313438/current/finalized/subdir0/subdir0 |
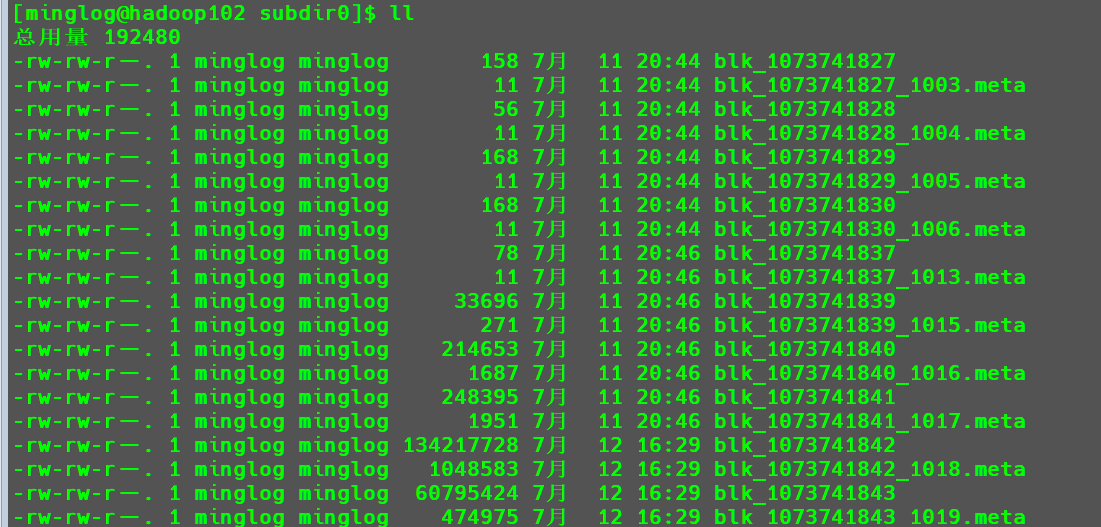
从Web界面中我们可以看出Java JDK的Block ID为1073741842和1073741843。
并且这些文件是有时间的作用的,将其拷贝到家目录。
1 | cp blk_1073741842 ~/ |

接下来,将blk_1073741843数据追加到blk_1073741842后面。
1 | cat blk_1073741843 >> blk_1073741842 |
然后使用以下命令解压blk_1073741842
1 | tar -zxvf blk_1073741842 |
可以看到在当前目录下成功解压
注意:
HDFS块的大小不能设置太小,也不能设置太大,有以下几个原因:总之,HDFS块的大小设置主要取决于磁盘传输速率,如果磁盘传输速率较快,可适当增加文件块的大小。
HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置。- 如果设置太大,从磁盘传输数据的时间会明显大于定位该块开始位置所需时间,导致程序在处理这块数据时,会非常慢。
HDFS的Shell操作
基本语法
hadoop fs 具体命令或者hdfs dfs 具体命令
命令大全
集群启动成功后,输入以下内容即可返回相关命令。
1 | hdfs dfs |
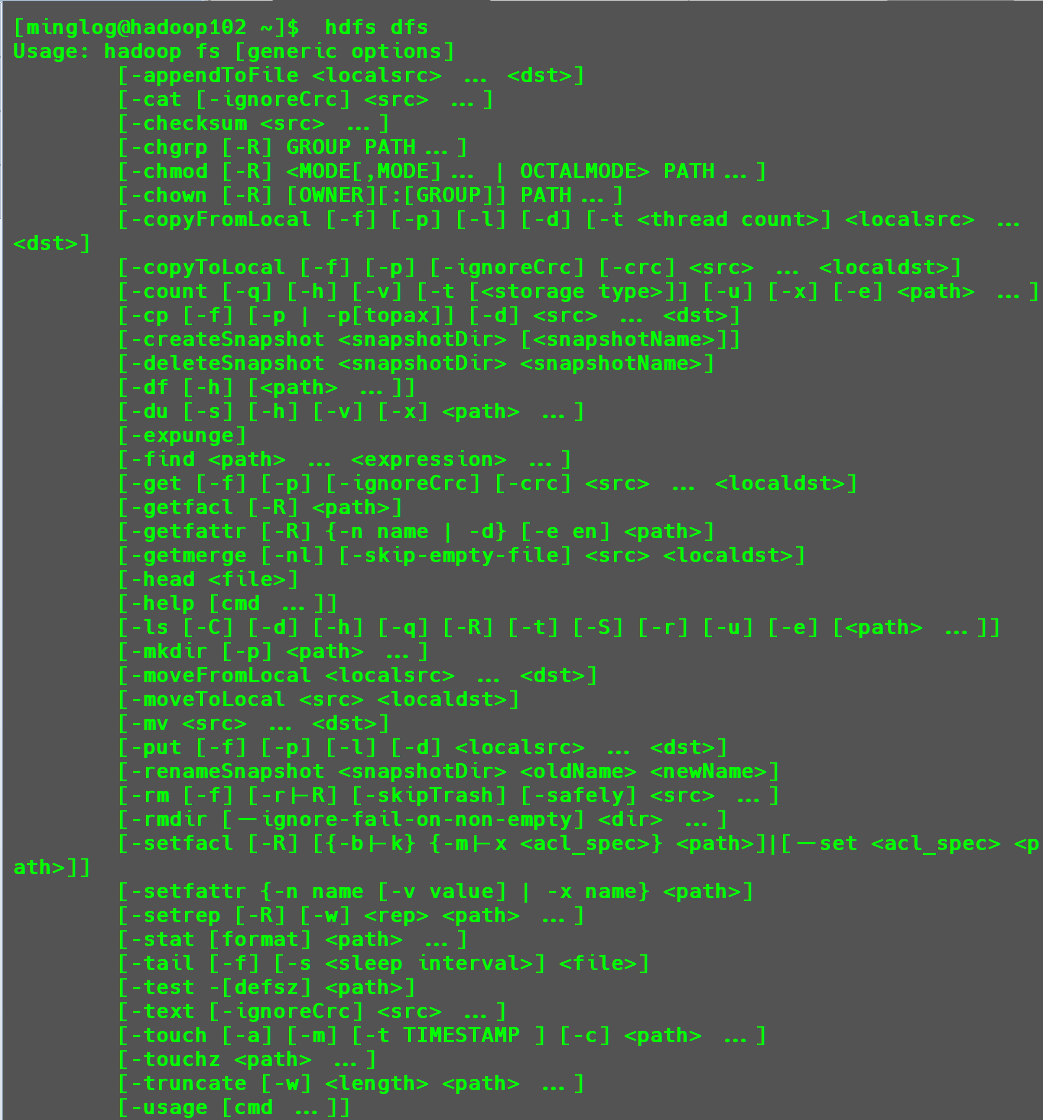
详细总结见此文章
常用命令实操
查看命令用法
hdfs dfs -help 命令
例如输入以下内容查看rm用法
1 | hdfs dfs -help rm |

将本地文件上传到HDFS
为了演示以下操作,首先将HDFS中/input目录下的文件全部删除。
1 | hdfs dfs -rm /input/* |

剪切
命令:
-moveFromLocal例如在本地创建一个
a.txt,内容为a。然后将其上传到
HDFS,命令如下:1
hdfs dfs -moveFromLocal a.txt /input

然后在
Web界面查看是否上传成功。
可见
HDFS中已上传成功,由于是剪切操作,所以本地的这个a.txt文件也会被删除。
拷贝
命令1:
-copyFromLocal命令2:
-put(用得更多)这两个命令用法一致,在此仅演示
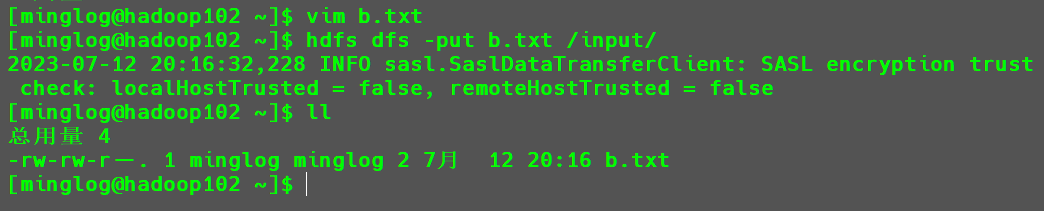
-put命令。首先在本地创建一个
b.txt文件,文件内容为b。接下来使用以下命令将其拷贝到
HDFS.1
hdfs dfs -put b.txt /input/
接下来在
Web界面查看是否拷贝成功。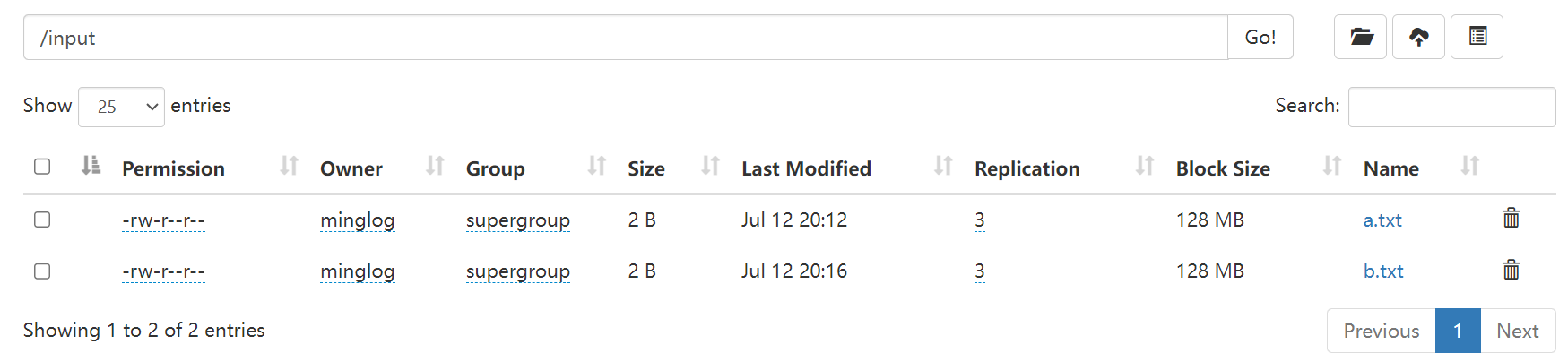
可见拷贝成功,并且本地的
b.txt文件也仍然存在。将一个文件中的内容,拷贝到另一个文件末尾。
命令:
-appendToFile例如将
b.txt中的内容,追加到/input/a.txt的末尾。追加前
/input/a.txt文件内容。1
hdfs dfs -cat /input/a.txt

接下来执行追加命令。
1
hdfs dfs -appendToFile b.txt /input/a.txt
然后再次查看
/input/a.txt文件内容。
追加成功。
将HDFS文件下载到本地
命令1:-copyToLocal
命令2:-get(用得更多)
这两个命令用法一样,在此仅演示-get命令。
例如将HDFS中input目录下的a.txt文件下载到本地家目录。
1 | hdfs dfs -get /input/a.txt ~/. |
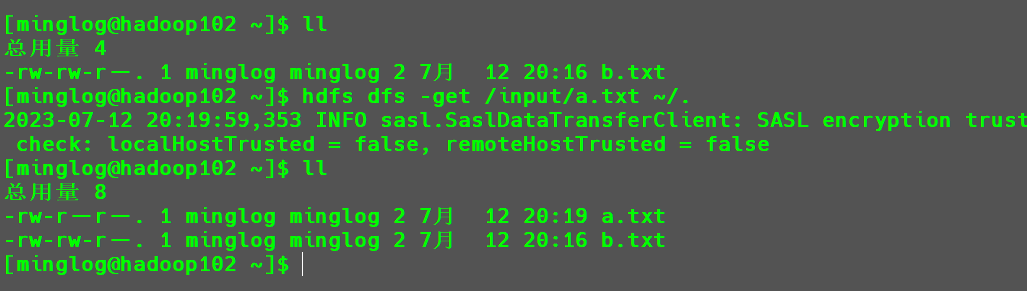
从结果可以看到,拷贝操作已成功。
其他命令
-ls:显示目录信息。1
hdfs dfs -ls /input

-cat:显示文件内容1
hdfs dfs -cat /input/a.txt
-chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限1
hdfs dfs -chmod 777 /input/a.txt

-mkdir:创建路径1
hdfs dfs -mkdir /output2

-cp:从HDFS的一个路径拷贝到HDFS的另一个路径。1
hdfs dfs -cp /input/a.txt /output2

-mv:在HDFS目录中移动文件1
hdfs dfs -mv /input/b.txt /output2
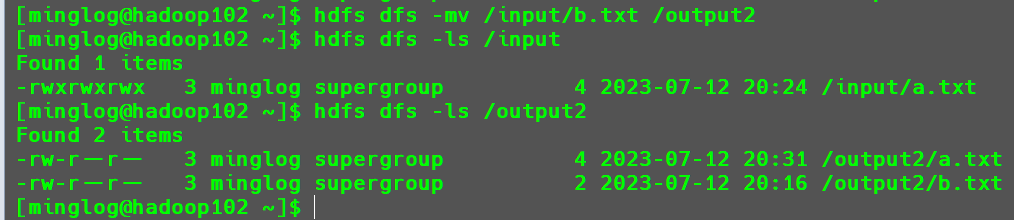
-rm:删除文件或文件夹1
hdfs dfs -rm /output2/a.txt

-rm -r:递归删除目录及目录里面内容1
hdfs dfs -rm -r /output2

-du:统计文件夹的大小信息为了演示效果,将
JDK上传至/input目录下。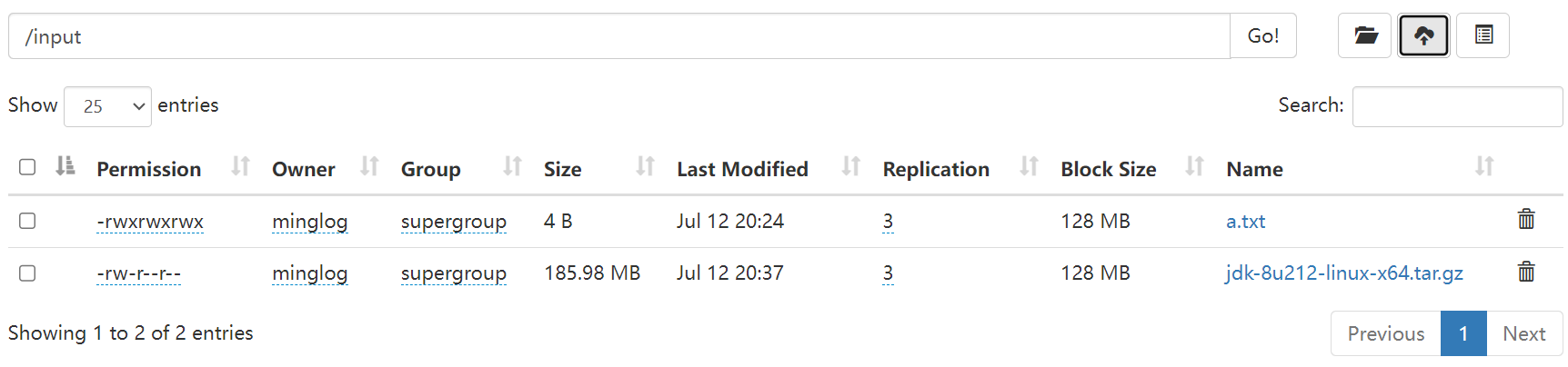
1
hdfs dfs -du /input

加下来添加
-s参数1
hdfs dfs -du -s /input

继续添加
-h参数1
hdfs dfs -du -s -h /input

-s:参数的作用为将所有的文件所占空间大小求和。-h:参数的作用为使用合适的单位输出。-setrep:设置HDFS中文件的副本数量。1
hdfs dfs -setrep 10 /input/a.txt
这个时候在
Web界面中查看a.txt的副本数量可以看到变成了10。
但是,由于当前节点数只有
3台,所以该设置虽然进行了修改数值,但是实际上的备份数是不能超过节点数的,故实际仍然只有3个副本。在Web界面中也可以看到副本数仍然是3个。只有节点数的增加到10台时,副本数才能达到10。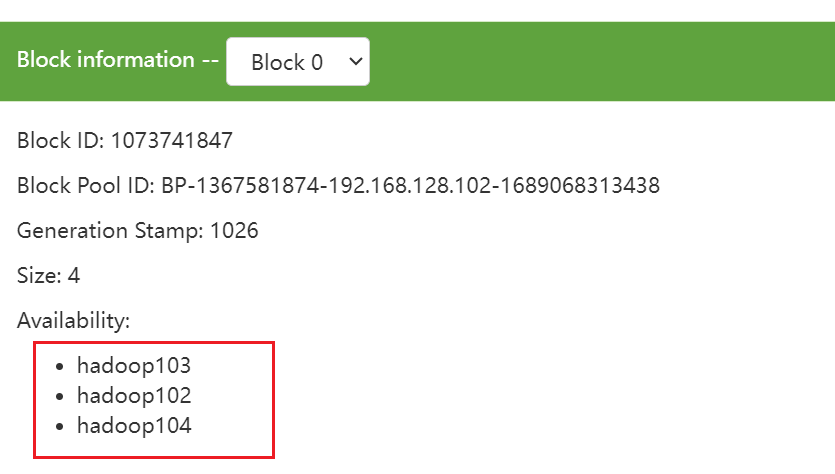
使用Java调用API操作HDFS
在前面的内容中我们都是通过操作服务器来执行相关的HDFS命令,但是考虑到安全问题,服务器并不是任何人都可以直接操作。其他用户要想使用HDFS一般是通过Java提供的API来进行访问。
配置客户机环境
首先下载并安装Hadoop在Windows系统下的环境依赖
下载完毕后,解压到一个没有中文和空格的目录下。
然后将该目录添加到环境变量中
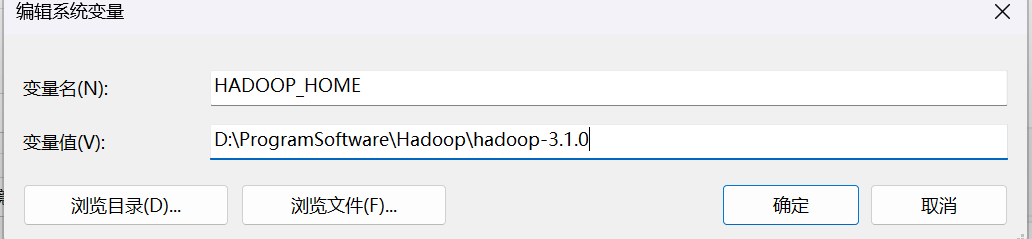
首先在系统变量中新建HADOOP_HOME变量如下图所示:
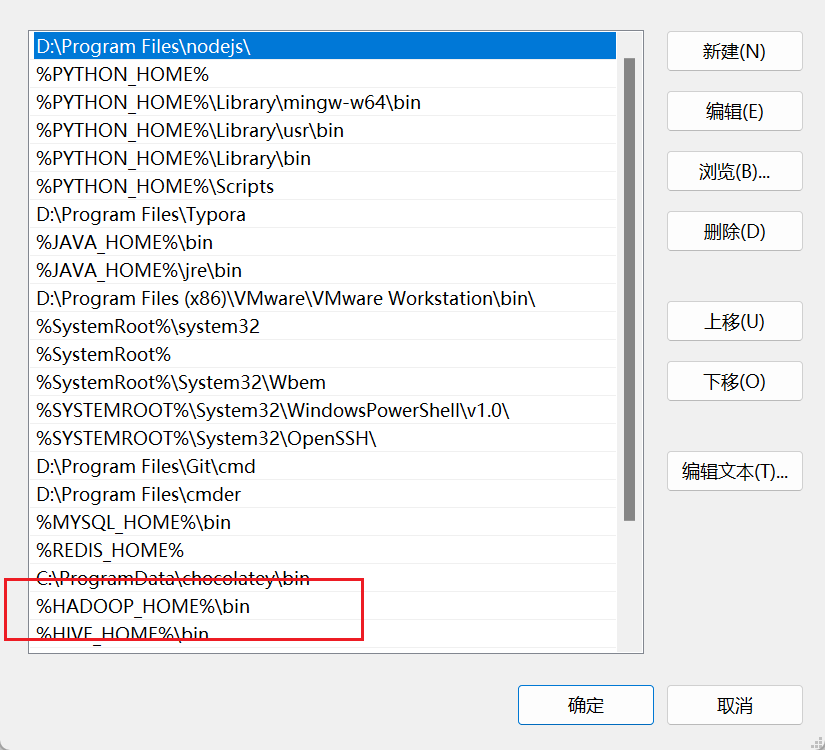
然后在系统变量中的Path变量中添加%HADOOP_HOME%\bin
配置完成后点击确定,然后在CMD中输入
1 | hadoop |
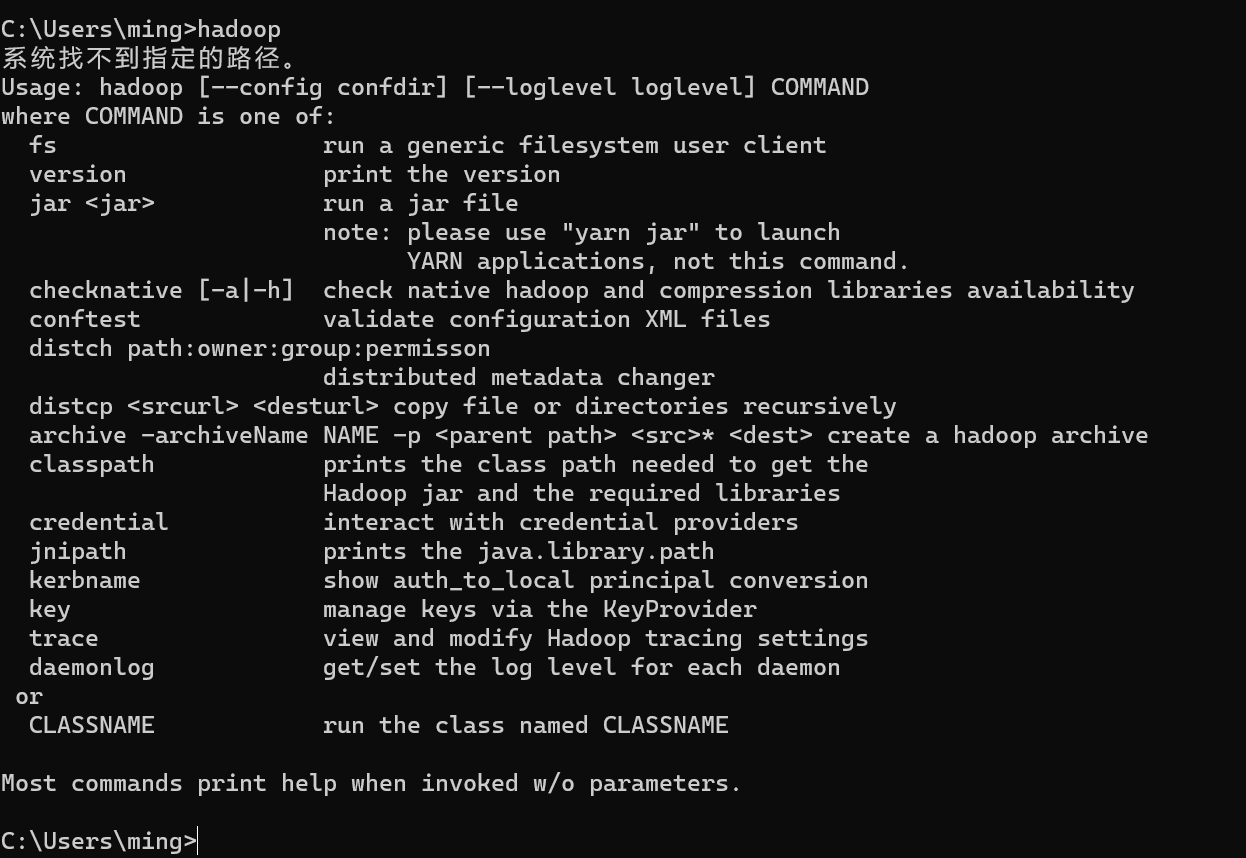
有返回图示内容说明配置成功。
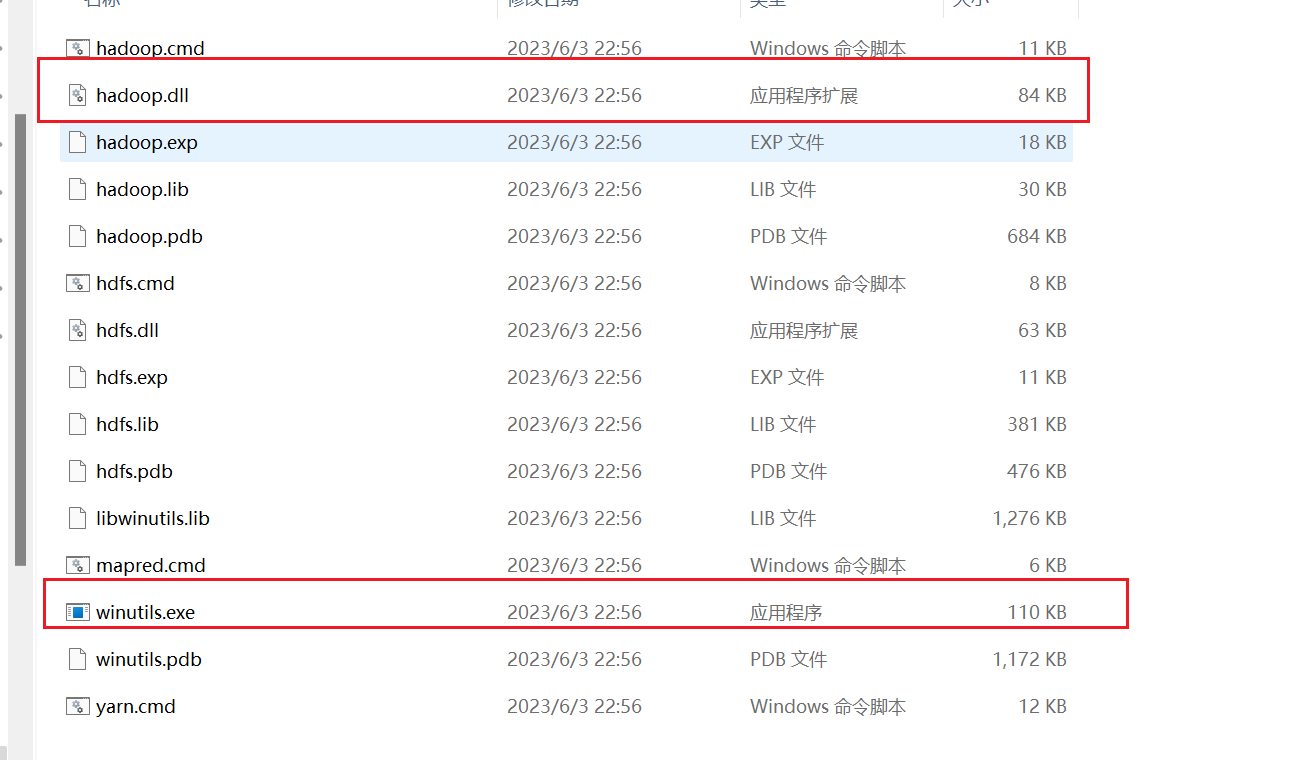
接下来为了保证环境能够顺利运行,将该目录下的bin目录中的hadoop.dll和winutils.exe拷贝到目录C:\Windows\System32下。
至此,Windows的HDFS环境搭建完成。
创建HDFS的Maven工程并配置依赖环境
在IDEA中创建一个Maven工程,工程名为HDFSMaven,创建完成后在该Maven工程的pom.xml配置文件中添加以下依赖项。
1 | <dependencies> |
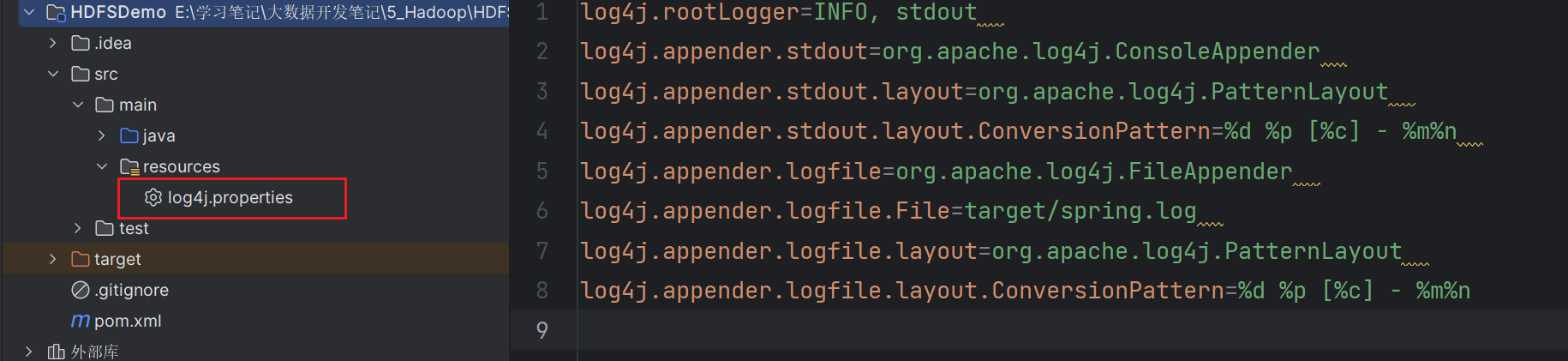
其中log4j依赖的作用是用来打印日志信息,想要其正常工作还需要在目录resources下新建一个log4j.properties配置文件,文件内容如下。
1 | log4j.rootLogger=INFO, stdout |
编写JAVA程序调用API操作HDFS
首先在main中的Java目录下创建一个包com.tipdm.hdfs,然后在该包下新建一个类HDFSDemo。
接下来在该类下编写代码操作HDFS。
单元测试方法Before和After
在junit中有两个单元测试方法Before和After,其作用如下:
Before:使用Before声明的类会在所有单元测试方法Test声明的类之前执行。After:与Before恰好相反,使用After声明的类,会在所有单元测试方法Test声明的类之后执行。
演示如下:
1 | package com.tipdm.hdfs; |
运行单元测试方法test

再运行单元测试方法test2
调用API操作HDFS进行上传和下载
调用API操作HDFS一共分为以下三个步骤:
- 创建
HDFS客户端对象 - 使用对象执行操作
- 关闭资源
其中第1步和第3步在所有的操作中都需要执行,故考虑将第1步中的代码方法Before声明的类中,将第3步中的代码放入After声明的类中。
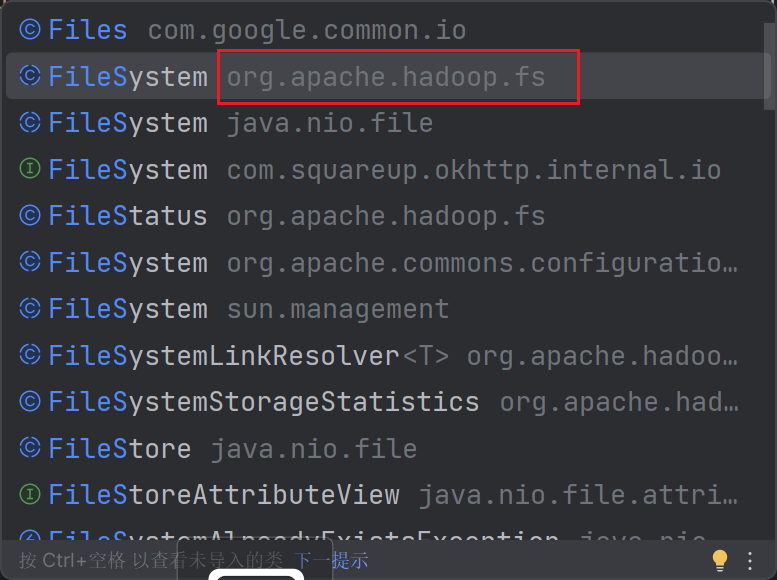
在Java中获取HDFS操作对象使用的方法是FileSystem中的get方法,注意一定要是hadoop中的FileSystem。
该get方法需要三个参数:
get(final URI uri, final Configuration conf, final String user)
uri:HDFS的地址(NameNode地址)conf:在conf中配置一些参数user:操作HDFS的用户名
同时为了使该方法能够被其他类调用,必须在外部声明。
1 | private FileSystem fs; |
关闭资源类如下所示:
1 | /* |
上传
上传使用的是FileSystem对象中的copyFromLocalFile方法,该方法用法如下所示:
copyFromLocalFile(boolean delSrc, boolean overwrite, Path src, Path dst)
delSrc:是否删除源文件(本地文件)overwrite:如果目标文件存在是否覆盖true:覆盖false:不覆盖(如果目标不存在直接报错)src:源文件路径(本地)dst:目标文件路径(HDFS)
1 | /* |
在此处,我将本地路径中的E:\\学习笔记\\大数据开发笔记\\5_Hadoop\\软件\\jdk-8u212-linux-x64.tar.gz的JDK上传到了HDFS下的/目录下。
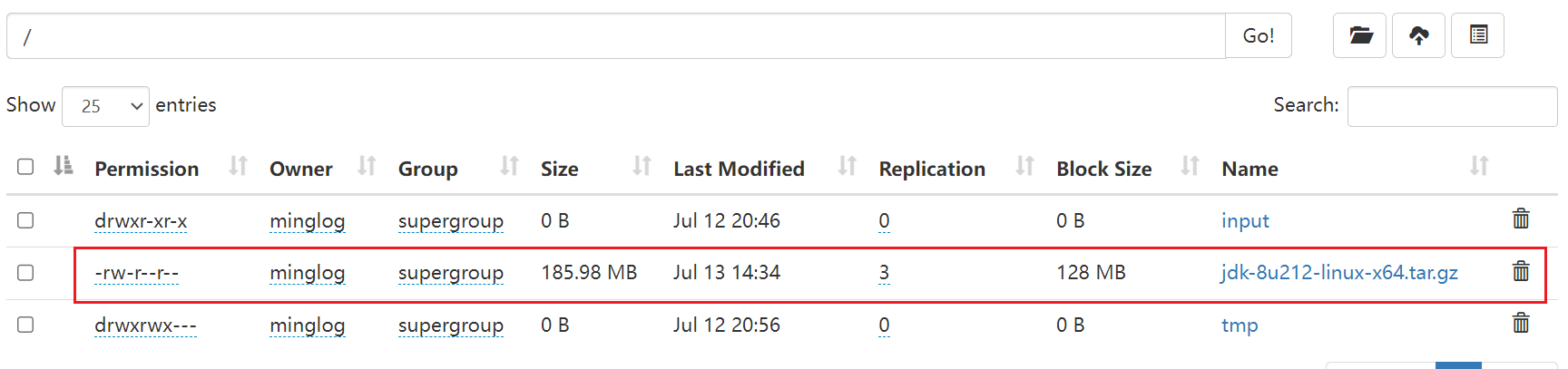
上传成功!
下载
下载使用的是FileSystem对象中的copyToLocalFile方法,该方法用法如下所示:
copyToLocalFile(boolean delSrc, Path src, Path dst, boolean useRawLocalFileSystem)
delSrc:是否删除源文件(HDFS)src:源文件路径(HDFS)dst:目标文件路径(本地文件)useRawLocalFileSystem:是否使用本地原始文件系统
1 | /* |
在此处,我将HDFS中的/jdk-8u212-linux-x64.tar.gz的JDK下载到了本地桌面。
下载成功!
第二种创建HDFS客户端对象的方法
1 | package com.tipdm.hdfs; |
直接执行上述代码会出现以下报错:
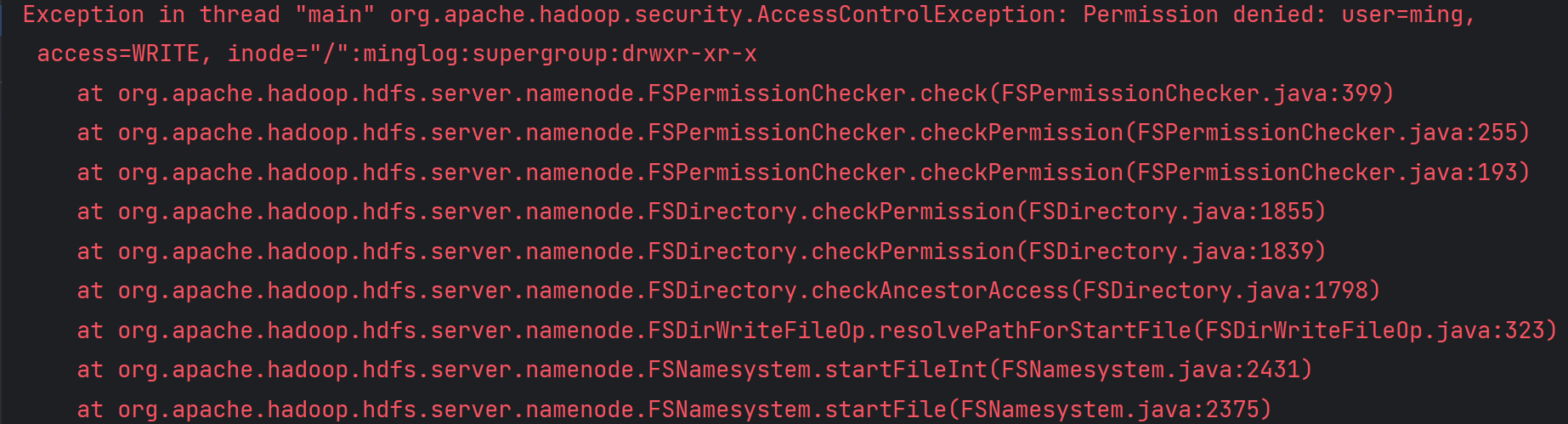
该报错的大致意思是用户ming没有权限写入。出现这个问题的原因是,在使用API访问HDFS时,默认是使用电脑的用户名去访问HDFS,由于HDFS中/目录的权限是drwxr-xr-x,其他人是没有写入权限的,所以导致报错。
解决该问题有两种办法:
- 修改目录权限。这种方法虽然可以解决问题,但是降低系统的安全性,只要知道访问地址,任何人都可以写入。
- 修改上传的用户名。这个方法显然比上面的方法更安全可靠。
在此,仅演示第二种方法的使用。
在IDEA上右键Main方法左边的运行按钮,点击修改运行配置。
点击修改选项
选择添加VM 选项
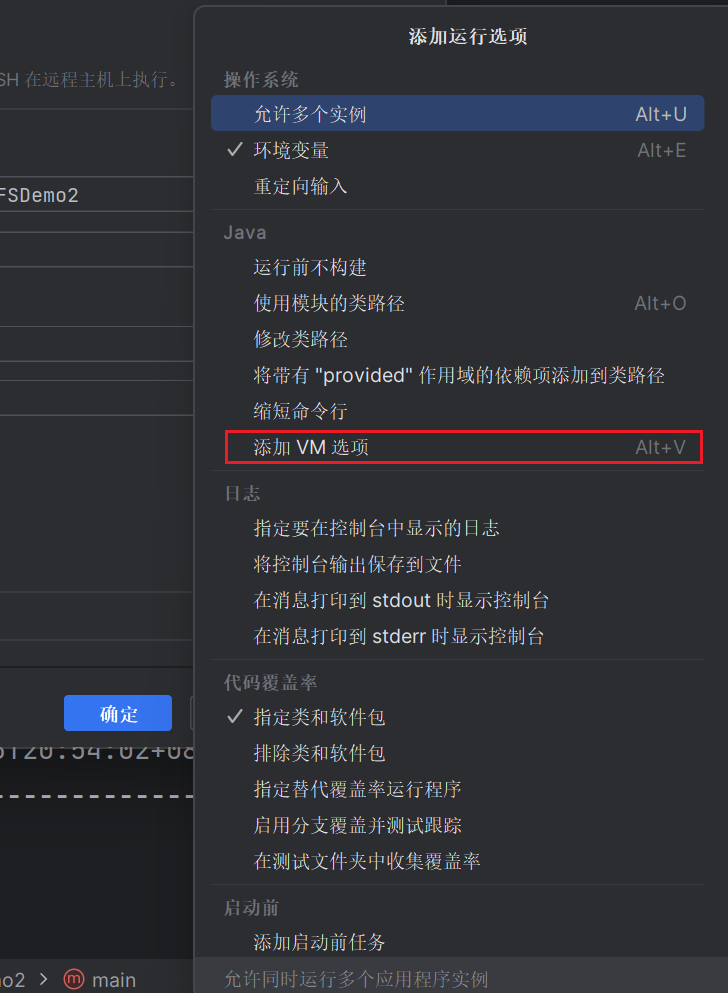
然后再对应位置输入以下内容,指定Hadoop操作用户名:
1 | -DHADOOP_USER_NAME=minglog |
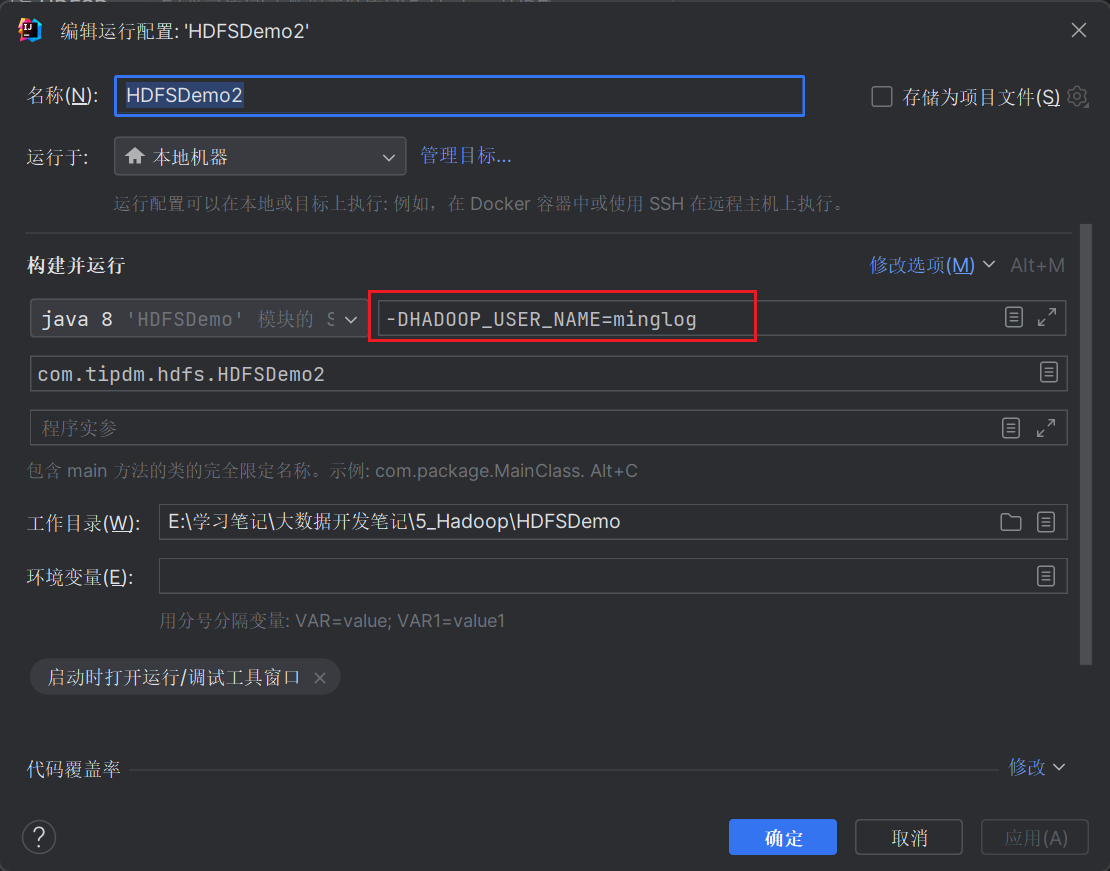
然后再次运行代码。
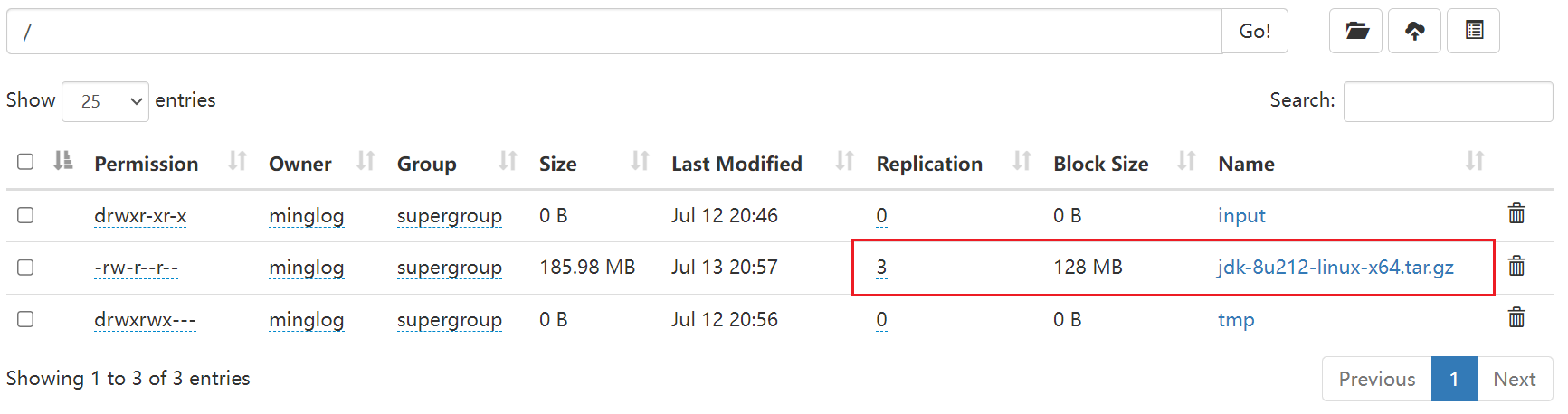
运行成功,在Web页面中也可以看到上传的文件。
参数运行的优先级
为了演示效果,首先在HDFS中创建一个新目录/input2。
1 | hdfs dfs -mkdir /input2 |
按照前面的内容,可以编写以下代码将a.txt文件上传到HDFS。
1 | package com.tipdm.hdfs; |
上传成功。

并且可以看到副本数默认为3。
那么有没有办法可以修改呢?
答案是有的,有2种方法可以修改该参数:
使用
Configuration传递参数。修改后的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27package com.tipdm.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
import java.net.URISyntaxException;
public class HDFSDemo3 {
public static void main(String[] args) throws Exception {
// 1. 创建客户端连接对象
URI uri = new URI("hdfs://hadoop102:8020");
Configuration conf = new Configuration();
conf.set("dfs.replication", "2");
String user = "minglog";
FileSystem fs = FileSystem.get(uri, conf, user);
// 2. 上传
Path inputpath = new Path("E:\\学习笔记\\大数据开发笔记\\5_Hadoop\\软件\\上传的WordCount文件\\a.txt");
Path outputpath = new Path("/input2/");
fs.copyFromLocalFile(false, true, inputpath, outputpath);
// 3. 关闭资源
fs.close();
}
}该代码将上传的
a.txt副本数修改为2。
修改成功。
使用
hdfs-site.xml配置文件。将上一步修改的代码注释掉,然后使用
hdfs-site.xml配置文件修改参数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27package com.tipdm.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
import java.net.URISyntaxException;
public class HDFSDemo3 {
public static void main(String[] args) throws Exception {
// 1. 创建客户端连接对象
URI uri = new URI("hdfs://hadoop102:8020");
Configuration conf = new Configuration();
// conf.set("dfs.replication", "2");
String user = "minglog";
FileSystem fs = FileSystem.get(uri, conf, user);
// 2. 上传
Path inputpath = new Path("E:\\学习笔记\\大数据开发笔记\\5_Hadoop\\软件\\上传的WordCount文件\\a.txt");
Path outputpath = new Path("/input2/");
fs.copyFromLocalFile(false, true, inputpath, outputpath);
// 3. 关闭资源
fs.close();
}
}在
main下的resources文件夹下新建一个hdfs-site.xml文件,然后填入以下内容,将副本数修改为6。1
2
3
4
5
6
7
8
9
<configuration>
<property>
<name>dfs.replication</name>
<value>6</value>
</property>
</configuration>从
Web界面可以看到副本数修改成功。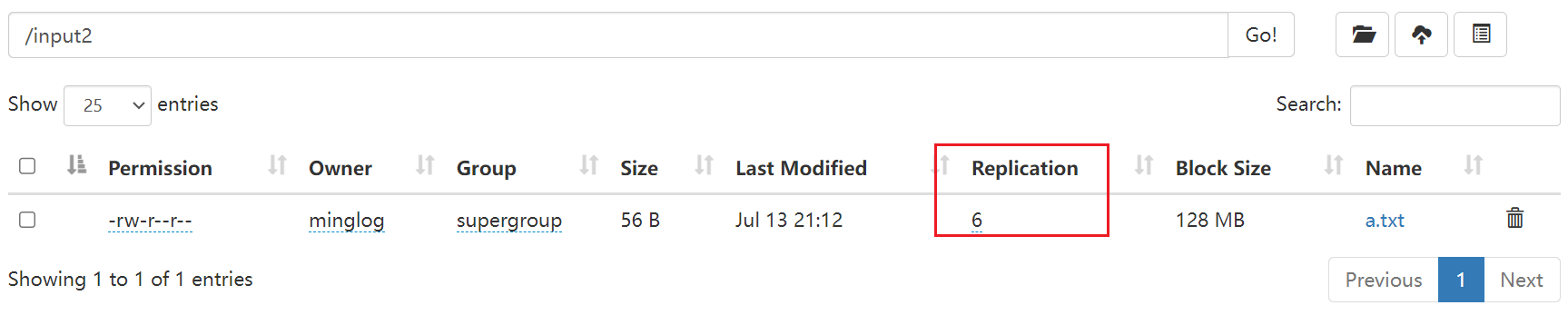
以上两种方法都可对HDFS的参数进行修改,那么如果在都配置相同参数的情况下,哪个优先级更高呢?
想要研究这个问题,可以同时将上述两个内容都配置好,运行代码,看实际生效的是哪一个即可。
再次取消Configuration参数设置的注释,同时保留hdfs-site.xml配置文件,运行代码。
1 | package com.tipdm.hdfs; |
从Web界面的结果可以知道,在代码Configuration中的参数设置优先级高于hdfs-site.xml配置文件中的参数设置。

参数设置优先级总结:
代码
Configuration中的参数设置 >hdfs-site.xml配置文件中的参数设置 > 服务器的默认配置