什么是YARN
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
YARN基础架构
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。
ResourceManager
ResourceManager是YARN集群的核心组件,负责整体资源的分配和管理。
主要作用如下:
- 处理客户端请求。
- 监控
NodeManager。 - 启动或监控
ApplicationMaster。 - 资源的分配与调度。
NodeManager
NodeManager是每个集群节点上运行的代理程序。
主要作用如下:
- 管理单个节点上的资源。
- 处理来自
ResourceManager的命令。 - 处理来自
ApplicationMaster的命令。
ApplicationMaster
用户提交job到集群中时,会ResourceManager会生成一个ApplicationMaster,其是应用程序的主要协调员。
主要作用如下:
- 为应用程序申请资源并分配给内部的任务。
- 任务的监控与容错。
Container
Container是YARN中资源的抽象表示。它是一组计算资源(如CPU、内存)的集合,用于执行应用程序中的任务。容器由NodeManager管理,并在节点上启动和运行应用程序的特定实例。
YARN的工作机制
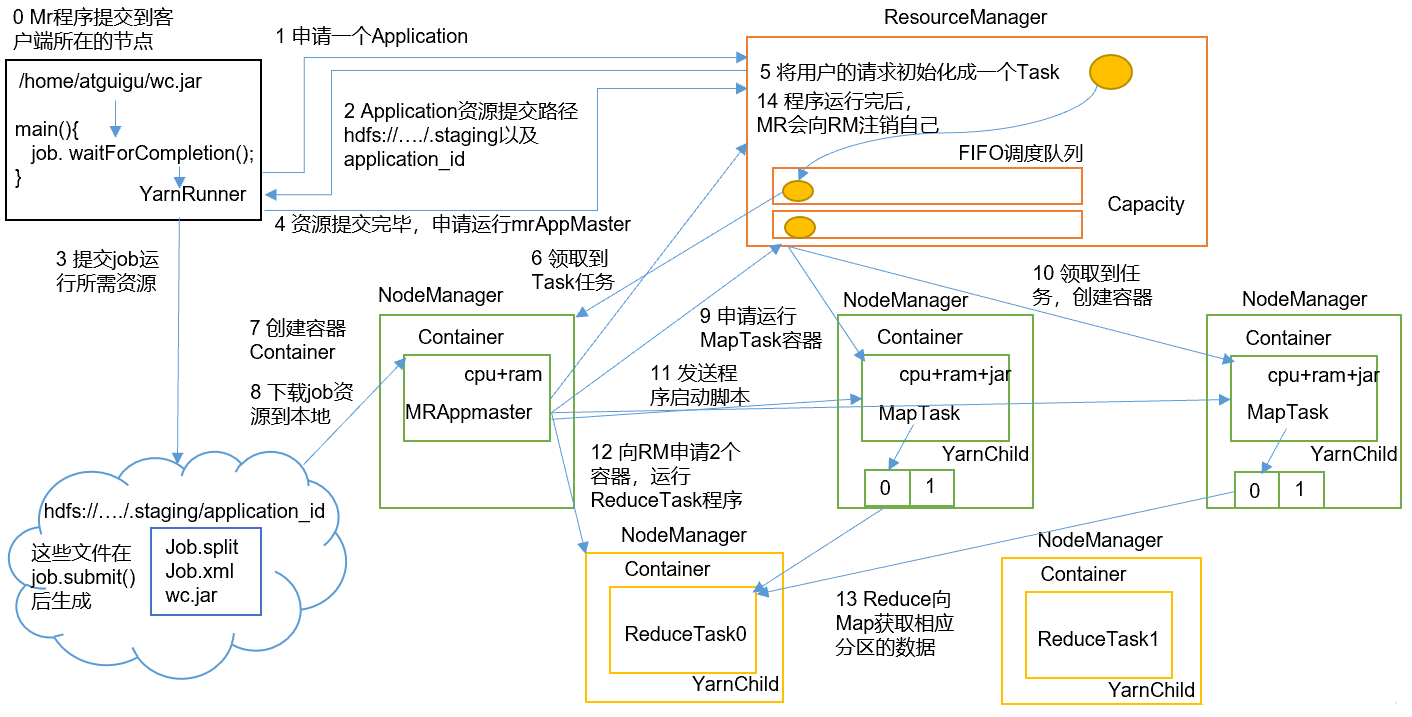
MR程序提交到客户端所在的节点。YarnRunner向ResourceManager申请一个Application。RM将该应用程序的资源路径返回给YarnRunner。- 该程序将运行所需资源提交到
HDFS上。 - 程序资源提交完毕后,申请运行
mrAppMaster。 RM将用户的请求初始化成一个Task。- 其中一个
NodeManager领取到Task任务。 - 该
NodeManager创建容器Container,并产生MRAppmaster。 Container从HDFS上拷贝资源到本地。MRAppmaster向RM申请运行MapTask资源。RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。ReduceTask向MapTask获取相应分区的数据。- 程序运行完毕后,
MR会向RM申请注销自己。
YARN调度器和调度算法
目前,Hadoop作业调度器主要有三种:
FIFO- 容量(
Capacity Scheduler) - 公平(
Fair Scheduler)
Apache Hadoop3.1.3默认的资源调度器是Capacity Scheduler。
CDH框架默认调度器是Fair Scheduler。
具体设置详见:yarn-default.xml文件。

1 | <property> |
先进先出调度器(FIFO)
FIFO调度器(First In First Out):单队列,根据提交作业的先后顺序,先来先服务。
优点:简单易懂。
缺点:不支持多队列,生产环境很少使用。
容量调度器(Capacity Scheduler)
Capacity Scheduler是Yahoo开发的多用户调度器。它可以设置多个队列,不同的队列设定不同的资源占比,同一个队列中还可以设置不同用户的资源使用占比和上限。
其优点如下所示:
- 多队列:每个队列可配置一定的资源量,每个队列采用FIFO调度策略。
- 容量保证:管理员可为每个队列设置资源最低保证和资源使用上限。
- 灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
- 多租户:支持多用户共享集群和多应用程序同时运行。为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
公平调度器(Fair Scheduler)
Fair Schedulere是Facebook开发的多用户调度器。同队列所有任务共享资源,在时间尺度上获得公平的资源。
与容量调度器相同点:
- 多队列:支持多队列多作业。
- 容量保证:管理员可为每个队列设置资源最低保证和资源使用上限。
- 灵活性:如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。
- 多租户:支持多用户共享集群和多应用程序同时运行;为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定。
与容量调度器不同点:
- 核心调度策略不同:容量调度器优先选择资源利用率低的队列;公平调度器优先选择对资源的缺额比例大的。
- 每个队列可以单独设置资源分配方式:容量调度器
FIFO、DRF;公平调度器FIFO、FAIR、DRF。
YARN案例实操
YARN生产环境核心参数配置案例
需求:从1T数据中,统计每个单词出现的次数。
硬件资源:3台服务器,每台配置4G内存,4核CPU,4线程。
增加yarn-site.xml配置参数
为了演示效果,首先我们把修改前的YARN中硬件参数截图如下所示:

增加yarn-site.xml配置参数如下:
1 | <!-- 选择调度器,默认容量 --> |
然后分发配置:
1 | xsync yarn-site.xml |
然后重启集群
1 | myhadoop stop |

再次查看YARN的配置信息。

这个时候可以看到以下变化:
- 最大内存变成了
12GB。 - 最大
VCORE变成了12。 - 最大资源使用量变成了
2G+2Core。
容量调度器多队列提交案例
- 在生产环境怎么创建队列?
- 调度器默认就1个default队列,不能满足生产要求。
- 按照框架:hive /spark/ flink 每个框架的任务放入指定的队列(企业用的不是特别多)。
- 按照业务模块:登录注册、购物车、下单、业务部门1、业务部门2。创建多队列的好处?
- 创建多队列的好处?
- 因为担心员工不小心,写递归死循环代码,把所有资源全部耗尽。
- 实现任务的降级使用,特殊时期保证重要的任务队列资源充足。(例如:淘宝在
双11和618)
业务部门1(重要) => 业务部门2(比较重要) => 下单(一般) => 购物车(一般) => 登录注册(次要)。
配置多队列的容量调度器
需求:default队列占总内存的40%,最大资源容量占总资源60%;hive队列占总内存的60%,最大资源容量占总资源80%。
点击YARN的web界面中的Scheduler,查看当前队列情况。

此时,只有一个默认队列default。
在
capacity-scheduler.xml中配置如下:修改内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20<!-- 指定多队列,增加hive队列 -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,hive</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<!-- 降低default队列资源额定容量为40%,默认100% -->
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>40</value>
</property>
<!-- 降低default队列资源最大容量为60%,默认100% -->
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>60</value>
</property>增加内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57<!-- 指定hive队列的资源额定容量 -->
<property>
<name>yarn.scheduler.capacity.root.hive.capacity</name>
<value>60</value>
</property>
<!-- 用户最多可以使用队列多少资源,1表示所有 -->
<property>
<name>yarn.scheduler.capacity.root.hive.user-limit-factor</name>
<value>1</value>
</property>
<!-- 指定hive队列的资源最大容量 -->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-capacity</name>
<value>80</value>
</property>
<!-- 启动hive队列 -->
<property>
<name>yarn.scheduler.capacity.root.hive.state</name>
<value>RUNNING</value>
</property>
<!-- 哪些用户有权向队列提交作业 -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name>
<value>*</value>
</property>
<!-- 哪些用户有权操作队列,管理员权限(查看/杀死) -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name>
<value>*</value>
</property>
<!-- 哪些用户有权配置提交任务优先级 -->
<property>
<name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name>
<value>*</value>
</property>
<!-- 任务的超时时间设置:yarn application -appId appId -updateLifetime Timeout
参考资料:https://blog.cloudera.com/enforcing-application-lifetime-slas-yarn/ -->
<!-- 如果application指定了超时时间,则提交到该队列的application能够指定的最大超时时间不能超过该值。
-->
<property>
<name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name>
<value>-1</value>
</property>
<!-- 如果application没指定超时时间,则用default-application-lifetime作为默认值 -->
<property>
<name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name>
<value>-1</value>
</property>分发配置
1
xsync capacity-scheduler.xml
在
hadoop103节点,重启YARN,或执行以下命令刷新队列。1
yarn rmadmin -refreshQueues
这个时候再次刷新
YARN的WEB界面。
可以看到此时就有了两个队列
hive和default。
向hive队列提交任务
向指定队列提交任务有两种方式:
打包
jar然后上传到节点执行,使用以下方法指定提交的队列。1
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -D mapreduce.job.queuename=hive /input /output
这里使用的是
Hadoop中的官方案例进行实现。
开始运行后,再次回到
YARN的WEB界面可以看到,现在已经开始使用hive队列的资源执行任务了。在本地中
Driver类中,设置conf中的参数。1
2// 设置如下内容
conf.set("mapreduce.job.queuename","hive");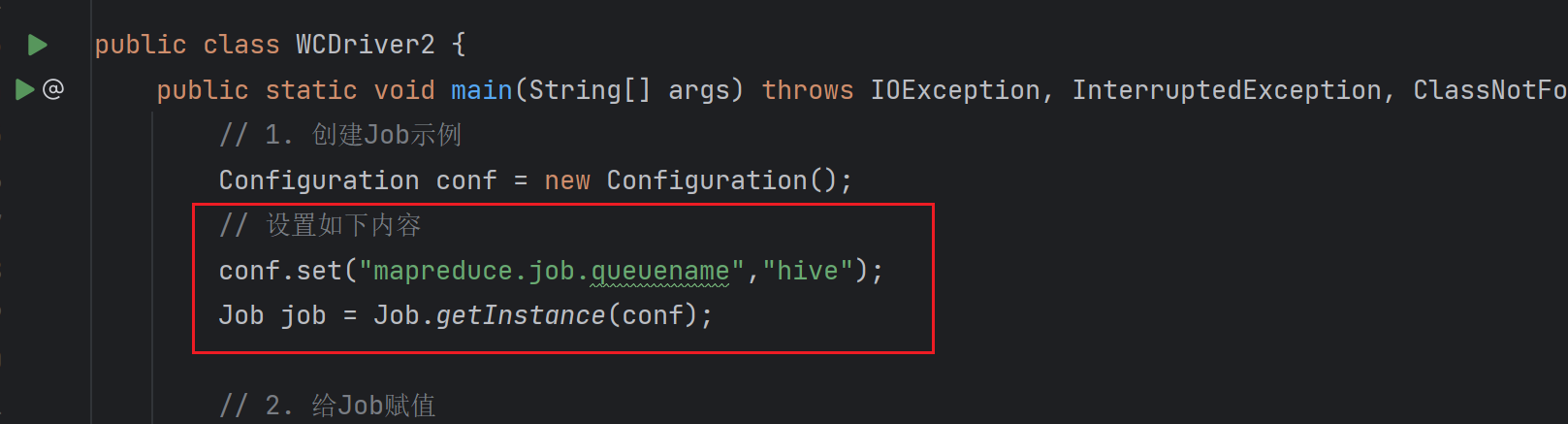
设置完后点击
package进行打包。1
hadoop jar /input /output
上传到集群后,执行以下代码在
hadoop中运行jar包。由于此时在打包jar包时就已经指定了提交的队列为hive。1
hadoop jar MRDemo-1.0-SNAPSHOT.jar com.tipdm.mr.wordcount.WCDriver2 /input /output2
开始执行任务后,同样可以在
hive这个队列中提交任务。
同时向集群中提交两个任务
这个时候将上述两个任务同时在集群中提交,一个指定的队列为默认队列default,一个指定的队列为hive队列。
首先将集群中的输入文件夹全部删除,然后在hadoop102和hadoop103中分别执行以下代码。
1 | hadoop jar MRDemo-1.0-SNAPSHOT.jar com.tipdm.mr.wordcount.WCDriver2 /input /output2 |
1 | hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output |
这个时候再次查看YARN中的结果,可以看到defalut和hive这两个队列均有任务在执行。

演示资源借调
为了演示这个效果,从前面的运行结果可以看到,WCCount这个任务的资源占用是高于10%的,现在我们再次修改capacity-scheduler.xml配置文件,将hive队列中的默认资源占用设置为10%,defalut为90%。
修改内容如下所示:
1 | <!-- 降低default队列资源额定容量为90%,默认100% --> |
然后分发任务:
1 | xsync capacity-scheduler.xml |
重启ResourceManager
1 | yarn --daemon stop resourcemanager |

然后再次提交任务
1 | hadoop jar MRDemo-1.0-SNAPSHOT.jar com.tipdm.mr.wordcount.WCDriver2 /input /output22 |
这个时候虽然任务也是可以进行的,但是此时在YARN的WEB界面显示的是橙色的进度条,表示超出设定的容量,开始向其他空闲队列借调资源执行任务。
