Zookeeper入门
概述
Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。官网链接
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
特点
Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。- 集群中只要有半数以上节点存活,
Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。 - 全局数据一致:每个
Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。 - 更新请求顺序执行,来自同一个
Client的更新请求按其发送顺序依次执行。 - 数据更新原子性,一次数据更新要么成功,要么失败。
- 实时性,在一定时间范围内,
Client能读到最新数据。
数据结构
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
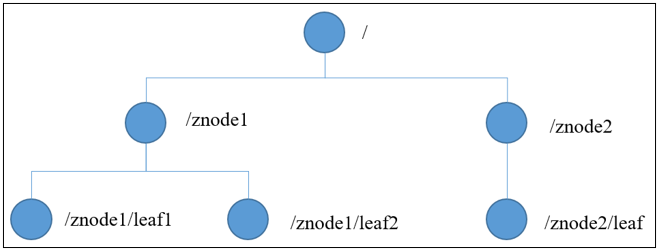
应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
统一命令服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。
例如:IP不容易记住,而域名容易记住。
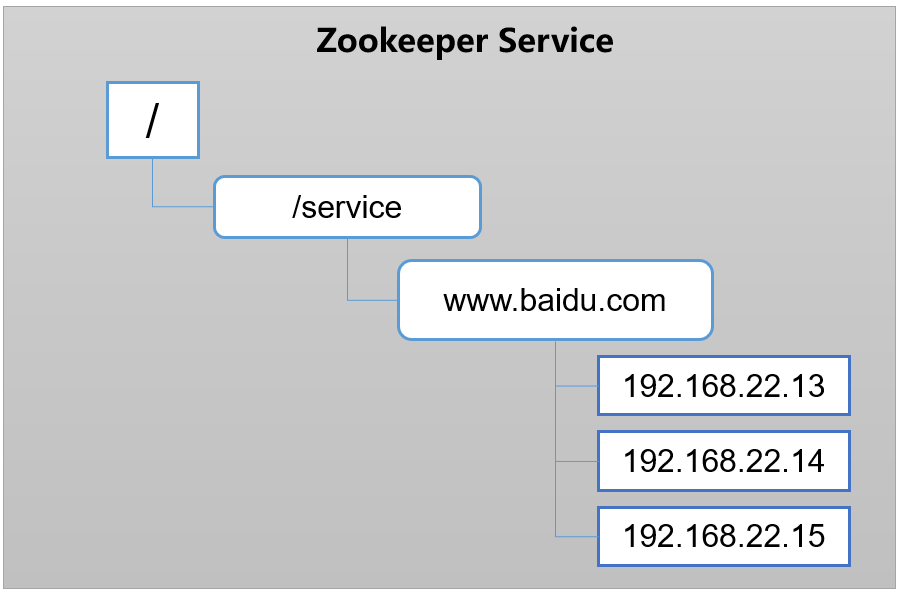
如图所示,不同地域的客户端访问的百度页面应该是就近的服务器。
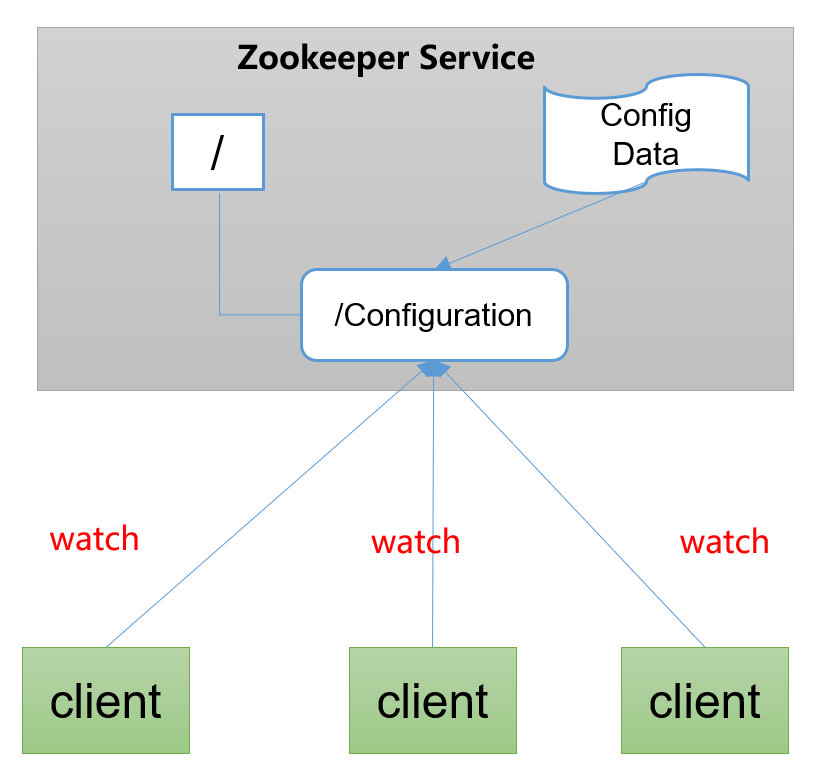
统一配置管理
- 分布式环境下,配置文件同步非常常见。
- 一般要求一个集群中,所有节点的配置信息是一致的,比如 Kafka 集群。
- 对配置文件修改后,希望能够快速同步到各个节点上。
- 配置管理可交由
ZooKeeper实现。- 可将配置信息写入
ZooKeeper上的一个Znode。 - 各个客户端服务器监听这个
Znode。 - 一旦
Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
- 可将配置信息写入
统一集群管理
- 分布式环境中,实时掌握每个节点的状态是必要的。
- 可根据节点实时状态做出一些调整。
ZooKeeper可以实现实时监控节点状态变化- 可将节点信息写入
ZooKeeper上的一个ZNode。 - 监听这个
ZNode可获取它的实时状态变化。
- 可将节点信息写入
服务器节点动态上下线
客户端能够实时洞察到服务器上下线的变化。
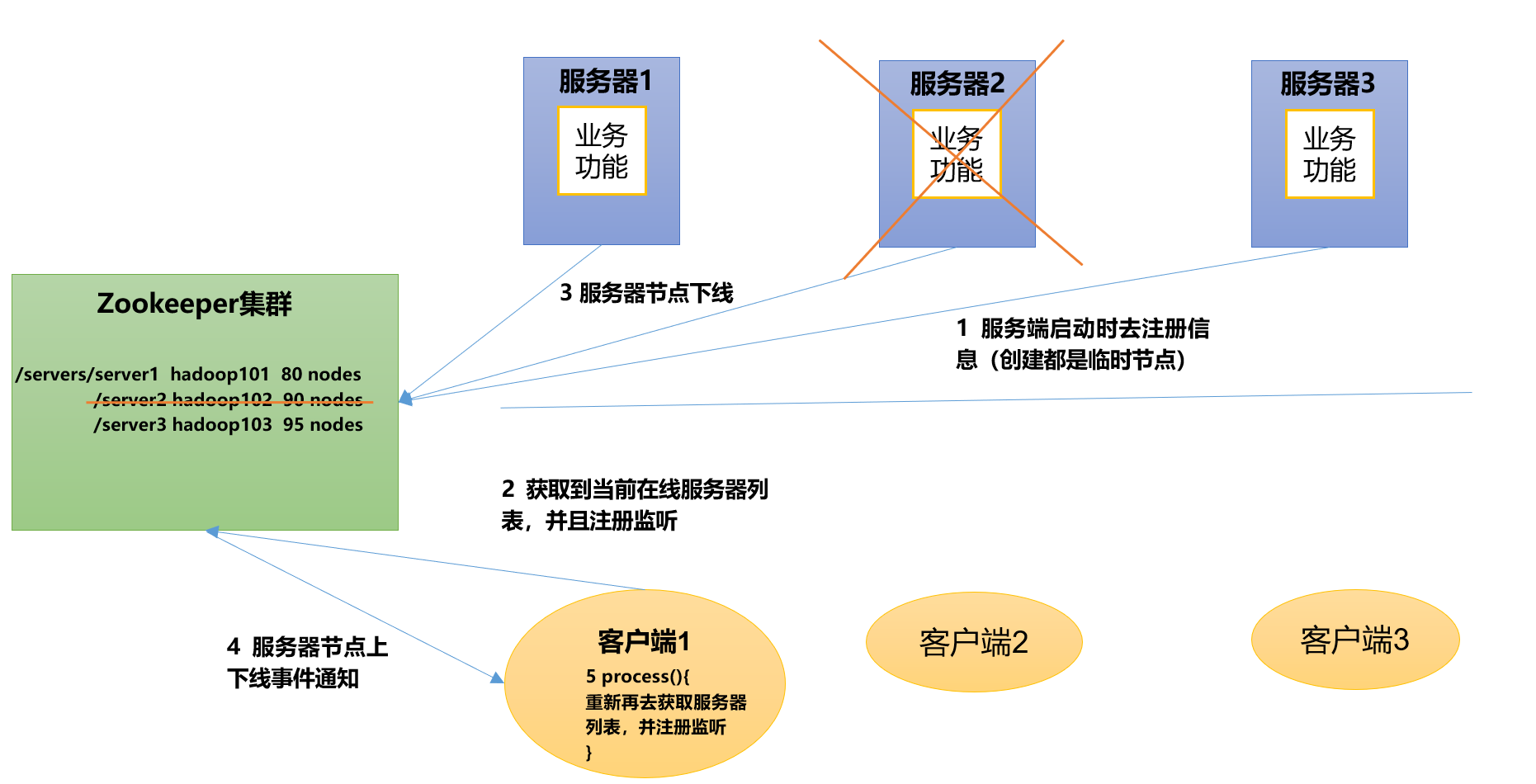
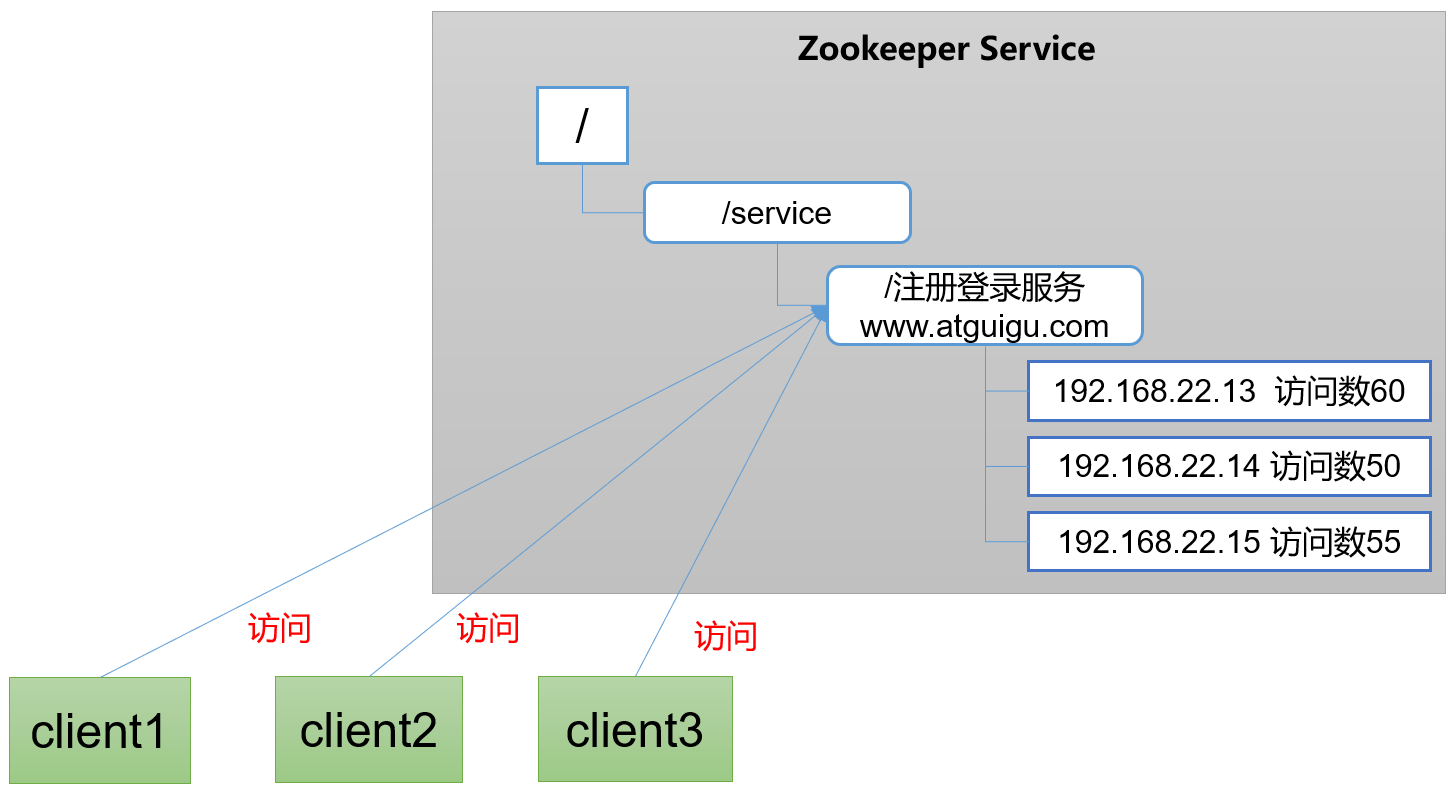
软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求
下载地址
官网下载
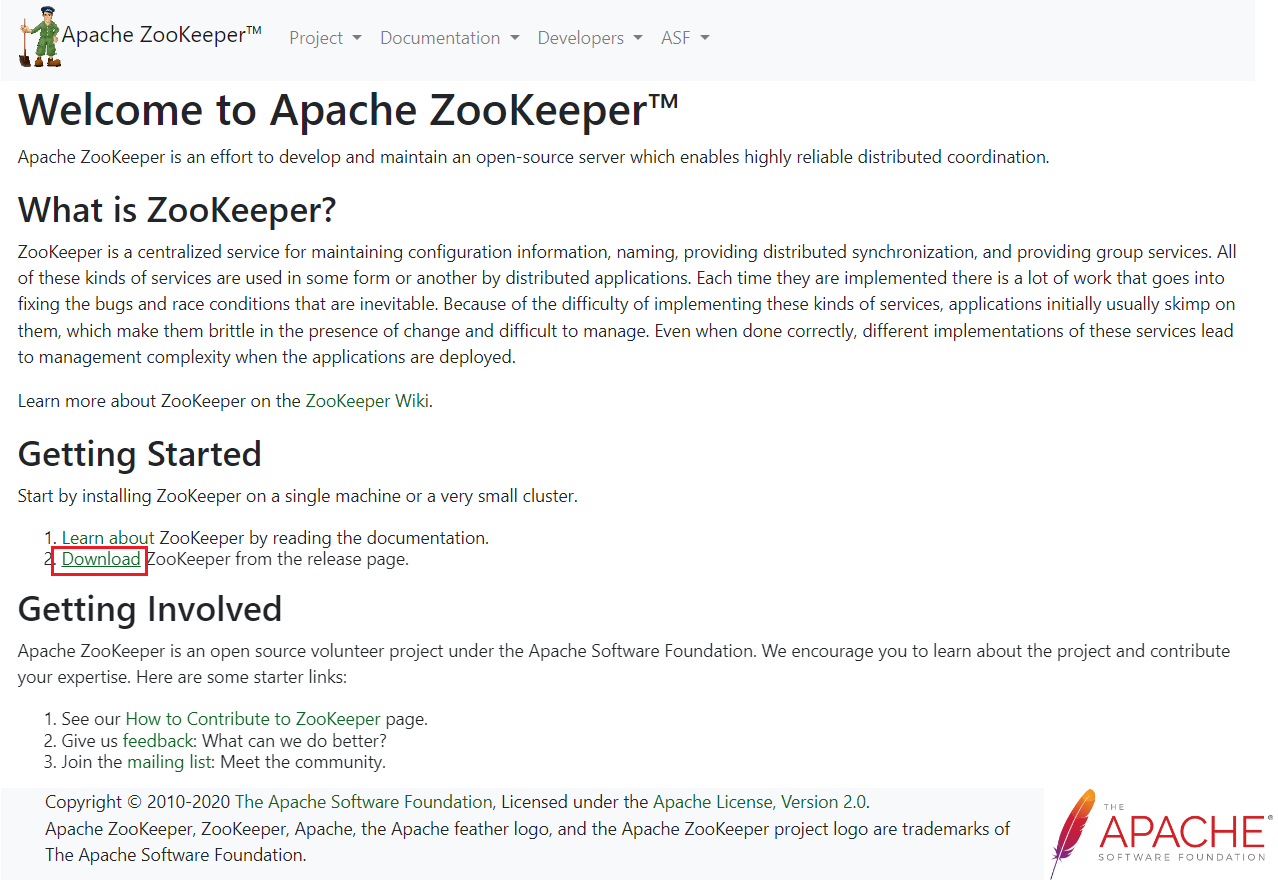
进入官网:官网链接
点击Download进入下载页面
在这个页面中公布了官方发布的最新的Zookeeper版本。
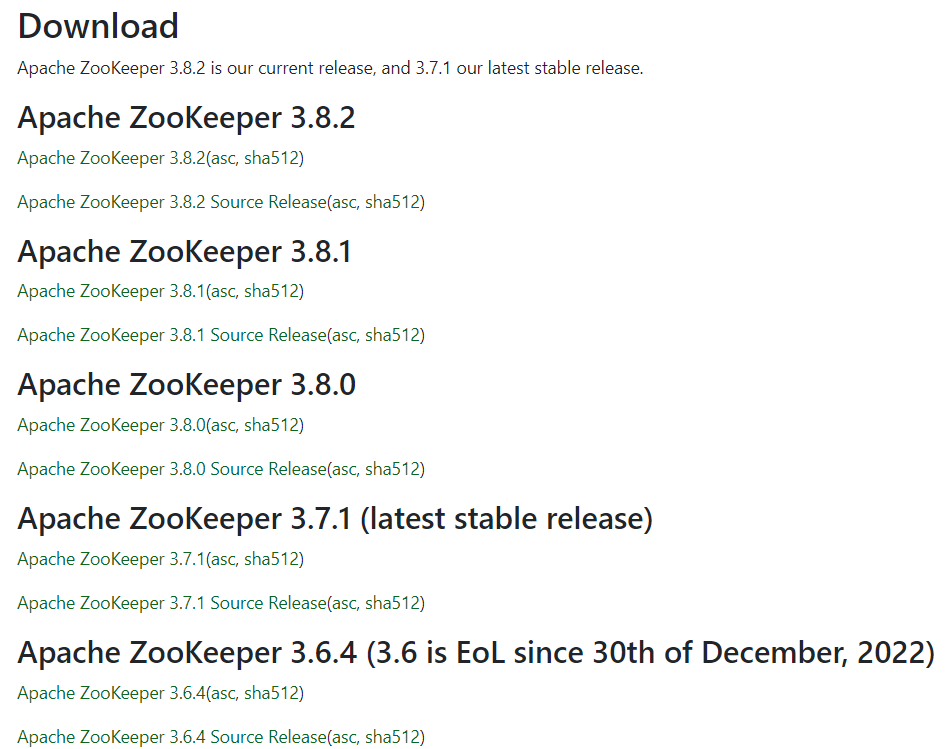
由于后续的其他框架也会去使用Zookeeper服务,所以为了能够适配各个框架的使用,Zookeeper版本还不能随便选取,在这里我们使用的版本是3.5.7版本。需要点击图示位置查看所有历史版本。
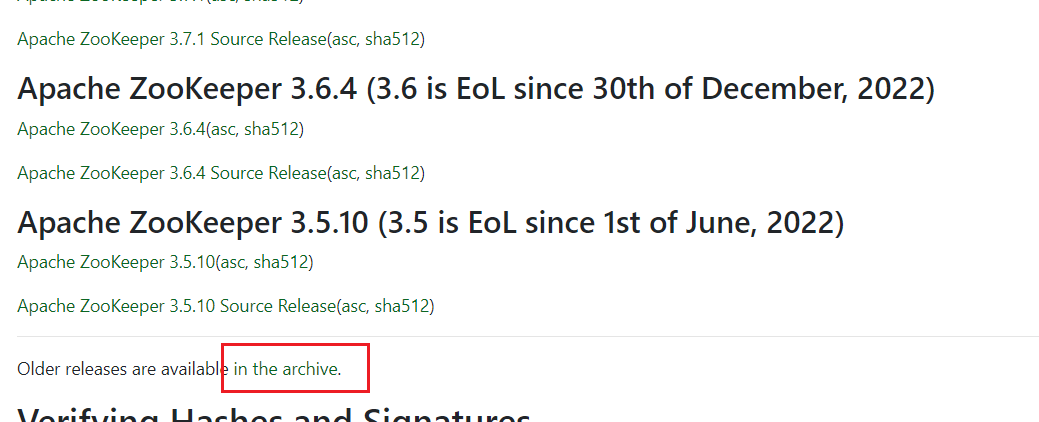
找到Zookeeper-3.5.7。
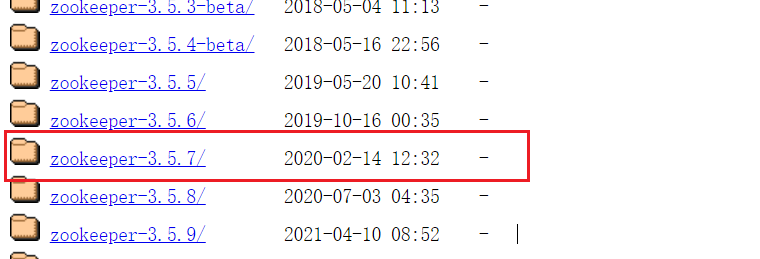
点击apache-zookeeper-3.5.7-bin.tar.gz进行下载。
网盘下载
点击此处获取网盘文件。
Zookeeper安装
本地模式安装
安装前要求提前安装JDK。
- 安装
Zookeeper服务
将下载的apache-zookeeper-3.5.7-bin.tar.gz上传到hadoop102节点,然后解压到/opt/module/目录。
1 | tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/ |
重命名zookeeper文件夹为zookeeper-3.5.7。
1 | mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7 |
进入Zookeeper目录,然后复制Zookeeper配置文件conf/zoo_sample.sfg为conf/zoo.cfg
1 | cd /opt/module/zookeeper-3.5.7 |
编辑配置文件conf/zoo.cfg。
1 | vim conf/zoo.cfg |
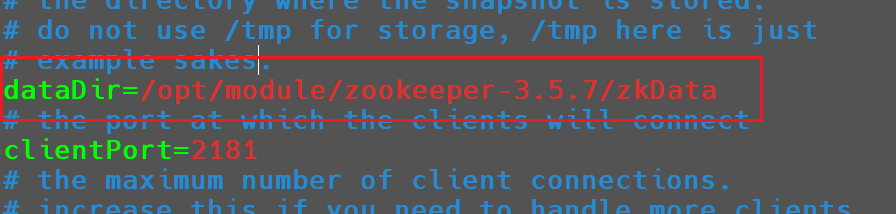
修改如下内容
1 | dataDir=/opt/module/zookeeper-3.5.7/zkData |
接下来在Zookeeper根目录下创建zkData目录,用于存储数据。
1 | mkdir /opt/module/zookeeper-3.5.7/zkData |
为了更方便使用Zookeeper命令,我们需要为Zookeeper设置环境变量。
编辑/etc/profile.d/my_env.sh文件
1 | sudo vim /etc/profile.d/my_env.sh |
注意:这里需要使用管理员权限运行命令。
添加以下内容
1 | #ZOOKEEPER_Home |
添加完毕后重新连接SSH即可刷新环境变量。
- 启动
Zookeeper服务
这个时候输入以下内容,即可开启Zookeeper服务。
1 | zkServer.sh start |

使用JPS即可查看当前Java进程。

使用以下命令可以查看Zookeeper服务状态。
1 | zkServer.sh status |

可以看到此时Mode为standalone单机模式。
- 客户端启动。
1 | zkCli.sh |
输入ls /即可查看根节点下的子节点。

更多命令后续会详细讲解。
- 退出客户端
1 | quit |

- 退出
Zookeeper服务
1 | zkServer.sh stop |

集群安装
在进行集群安装时,是在单机模式已经安装好的情况下进行进一步配置修改。
- 配置服务器编号
首先,清空zkData目录。
1 | cd /opt/module/zookeeper-3.5.7/zkData |
然后创建myid文件
1 | vim myid |
并在文件中填入一个2。

这里的数值表示的是对
Zookeeper中每个节点的一个编号,后续其他节点的Zookeeper不能重复。我的配置如下所示:
hadoop102:2
hadoop103:3
hadoop104:4
然后在zoo.cfg配置文件中添加以下内容
1 | vim /opt/module/zookeeper-3.5.7/conf/zoo.cfg |
1 | #######################cluster########################## |
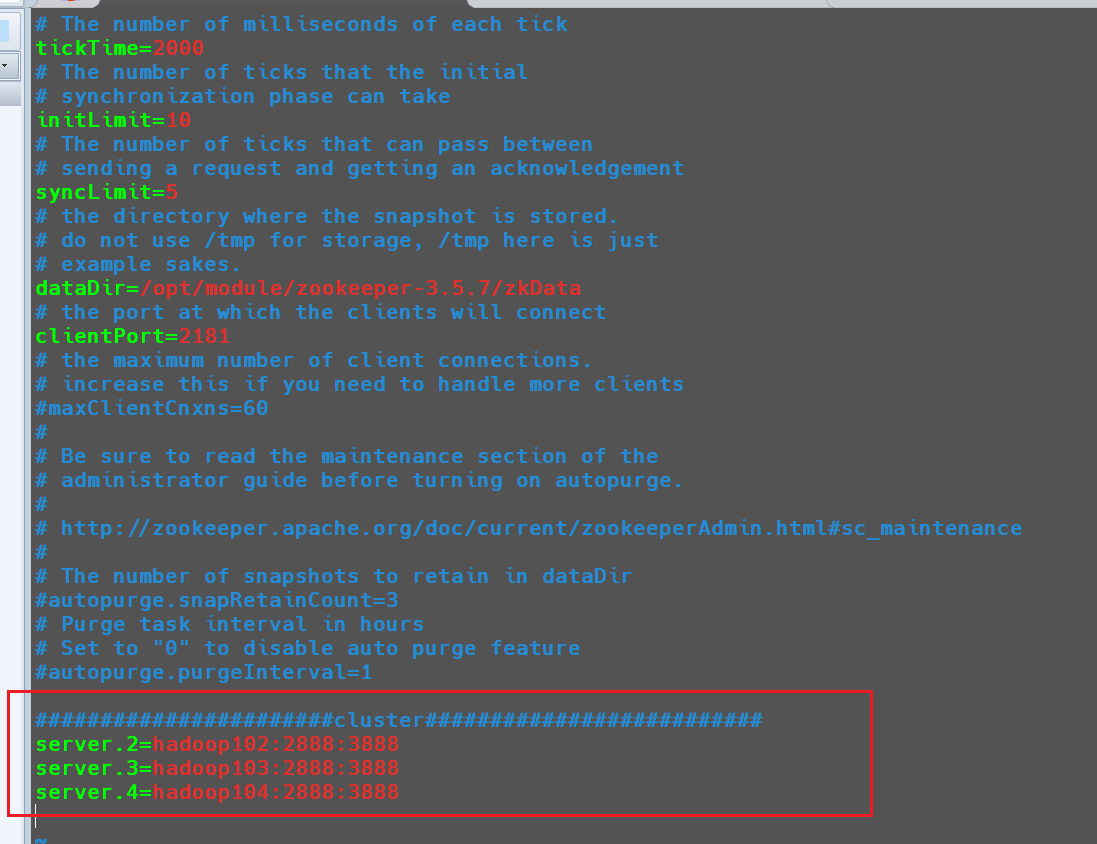
配置参数的意义如下所示:
server.(myid)=(服务器地址):(Zookeeper中Follower与Leader的通信端口):(Leader选举端口)
到此,Zookeeper一台节点配置完成,然后将Zookeeper分发到其他节点。
1 | xsync /opt/module/zookeeper-3.5.7 |
然后去hadoop103和hadoop104节点,添加Zookeeper环境变量和myid值。
- 在
hadoop102节点中同步Zookeeper环境变量
1 | scp /etc/profile.d/my_env.sh root@hadoop103:/etc/profile.d/ |
- 在
hadoop103-104节点中修改myid值
hadoop103:3
hadoop104:4
启动集群
在hadoop102-104中分别启动集群。
1 | zkServer.sh start |
启动后分别查看状态。
1 | zkServer.sh status |



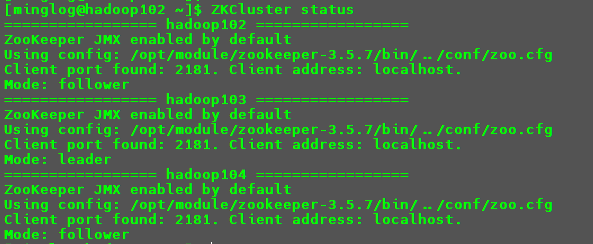
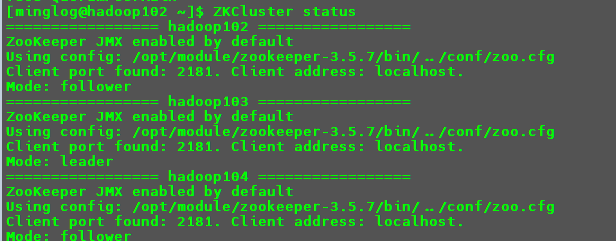
可以看到集群已经启动成功,其中hadoop102和hadoop104节点是follower,hadoop103节点是leader。
选举机制
要想搞清楚Zookeeper的选举原理,首先要搞清楚节点开启后就会发起选举请求,但是集群是不是就真的开始重新选举Leader呢?
其实并不是,首先集群会去检查当前集群中是否有Leader如果没有就会重新发起选举;如果有就会告知发起选取请求的节点当前Leader的信息。
第一次启动集群
比如现在有5个节点,node1-node5

首先node1节点启动,节点状态为LOOKING,node1发起选举请求。此时node1会给自己投一票。

但是当前节点票数不足半数,无法开启集群。
继续,启动node2,节点状态为LOOKING,node2发起选举请求。此时node2会首先投自己一票。

然后,node1和node2之间会交换信息,这个时候node1发现node2的myid比自己投的节点大(此时为node1本身),这个时候node1会修改自己的投票结果,改变为投给node2。

此时,node2节点票数为2,还是不足半数,无法开启集群。
继续,启动node3,节点状态为LOOKING,node3发送选举请求。此时node3会首先投自己一票

然后,node1、node2和node3之间也会互相交换信息,此时node1发现node3的myid值比自己投的节点(node2)要大,所以将票修改投给node3;node2也发现node3的myid值比自己投的节点(此时为node2本身),所以将票转投给node3。

此时node3节点的票数为3超过半数,故node3当选为Leader。此时修改node1和node2的状态为FOLLOWING,修改node3的状态为LEADING。

这个时候再去启动node4和node5节点,由于此时集群中已经有了Leader,所以他们启动之后就将票投给node3,然后将状态被修改为FOLLOWING。

综上所述,
Leader的选取与服务器的顺序是有关的,这一点可以自己在集群中验证。必须现在先启动
hadoop102,然后在启动hadoop103,此时Leader是hadoop103。这个前面已经演示过。
然后,把
Zookeeper集群关闭之后,先启动hadoop102,然后再启动hadoop104,此时Leader就会被修改为hadoop104。

非第一次启动集群
非第一次启动时,表示集群是已经承担过一些任务。
此时,有这样几个编号需要搞清楚。
SID:服务器ID。用来唯一标识一台Zookeeper集群中的机器,每台机器不能重复和myid值一致。ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和Zookeeper服务器对于客户端更新请求的处理逻辑有关。Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加。
那么什么时候集群会重新选举新的Leader呢?有两种情况:
- 服务器初始化启动。
- 服务器运行期间无法和
Leader保持连接。
而当一台机器进入Leader选举流程时,当前集群也可能处于以下两种状态:
集群中本来就存在
Leader这个时候机器试图去选举
Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可。集群中不存在
Leader假设
ZooKeeper由5台服务器组成分别为node1-5,SID分别为1-5,并且此时SID为3的服务器是Leader。如图所示。
如果
3和5服务器出现故障,此时需要开始进行Leader选举。假如:5台服务器的
ZXID分别为8、8、8、7、7,5台服务器的EPOCH分别为5、6、6、4、4
此时在剩余的服务器中由于
node2节点的EPOCH值最大,所以node2当选为Leader假如:5台服务器的
ZXID分别为9、8、8、7、7,5台服务器的EPOCH分别为6、6、6、4、4
此时由于
node1和node2的EPOCH值相同,接下来就需要去比较ZXID值,由于node1的ZXID值更大,所以node1当选为Leader。假如:5台服务器的
ZXID分别为8、8、8、7、7,5台服务器的EPOCH分别为6、6、6、4、4
此时由于
node1和node2的EPOCH值和ZXID值均相同,这个时候就需要去比较SID值,node2的SID值更大,所以node2当选为Leader。
群起脚本编写
前面我们在开启集群中的Zookeeper服务时,必须进入到每一台节点中去开启,每次停止也是需要去每一台节点下去执行命令,这样十分繁琐。
解决这个问题也很简单,跟前面Hadoop中启动一样,自己手动编写一个脚本用于控制所有节点的Zookeeper服务。
脚本名为ZKCluter,内容如下所示:
1 | # !/bin/bash |
然后赋予脚本执行权限
1 | chmod u+x ZKCluster |
为了能够全局使用,还需要将ZKCluster放入以下目录/opt/module/zookeeper-3.5.7/bin。
1 | mv ZKCluster /opt/module/zookeeper-3.5.7/bin |
由于我们在搭建
Zookeeper集群时已经为bin目录配置过环境变量,所以可以在任意位置使用该目录下的脚本。
集群启动
1
ZKCluster start
查看所有节点状态
1
ZKCluster status
关闭
Zookeeper集群服务。1
ZKCluster stop
使用以下命令,也可以判断是否关闭成功,查看所有节点的
java进程。1
jpsall
客户端命令行操作
开启客户端
首先启动Zookeeper集群。
1 | ZKCluster start |
1 | ZKCluster status |
连接节点本机的Zookeeper服务
1 | zkCli.sh |
连接其他节点的Zookeeper服务
输入help可以查看相关命令帮助。
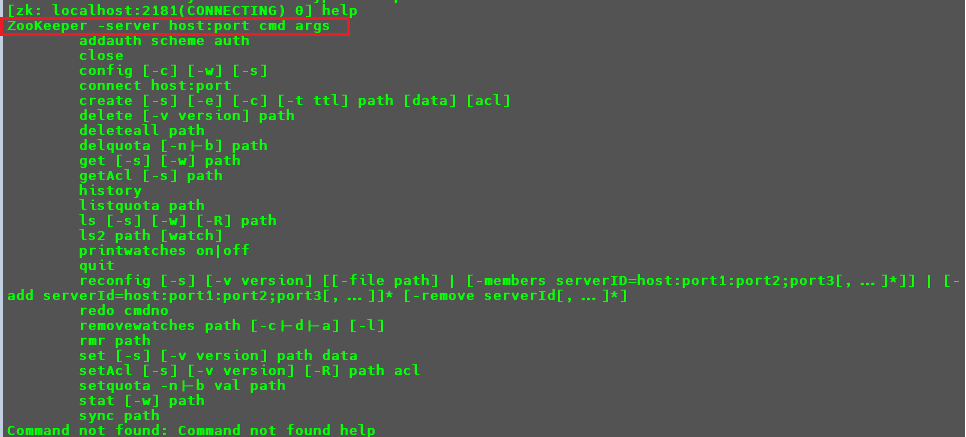
从第一行可以看出Zookeeper可以使用-server参数去连接其他节点的Zookeeper服务。
例如连接hadoop103的Zookeeper服务。
1 | # 退出当前zookeeper服务 |
相关命令
命令行语法
| 命令基本语法 | 功能描述 |
|---|---|
help |
显示所有操作命令 |
ls path |
使用ls命令来查看当前znode的子节点 [可监听] -w 监听子节点变化-s 附加次级信息 |
create |
普通创建 -s含有序列 -e临时(重启或者超时消失) |
get path |
获得节点的值 [可监听]-w 监听节点内容变化 -s 附加次级信息 |
set |
设置节点的具体值 |
stat |
查看节点状态 |
delete |
删除节点 |
deleteall |
递归删除节点 |
命令演示
创建节点
1
2# 在根节点下创建lol节点
create /lol
1
2# 在lol节点下创建mangseng
create /lol/mangseng
1
2# 在lol节点下创建gailun带序列的节点
create -s /lol/gailun
此时会自动的给
gailun节点增加一个序列0000000001,并且后续每次创建一个新的带序列的节点会在该序列的基础上继续+1。1
2# 创建临时节点(退出会话后消失)
create -e /lol/houzi
重启
Zookeeper会话后临时节点消失
给节点设置值与获取节点的值
1
2
3
4# 给mangseng节点设置值xiazi
set /lol/mangseng xiazi
# 获取该节点
get /lol/mangseng
-w参数作用是用来监听某个节点的值是否发生变化,如果发生变化后会做出相应反馈。(注意:仅监听一次,ls命令中的-w参数同理)1
get -w /lol/mangseng/xiazi

删除节点
1
2# 删除节点/lol/gailun0000000001
delete /lol/gailun0000000001
递归删除节点
1
2# 递归删除节点/lol
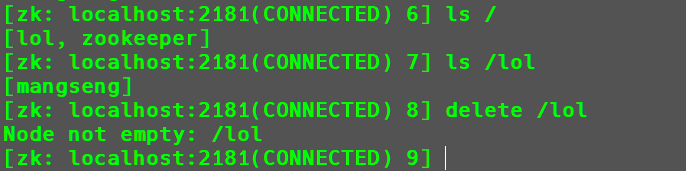
deleteall /lol
使用delete只能删除空节点,如果该节点下还包含子节点是无法删除的,这个时候就需要使用递归删除。
查看节点状态
1
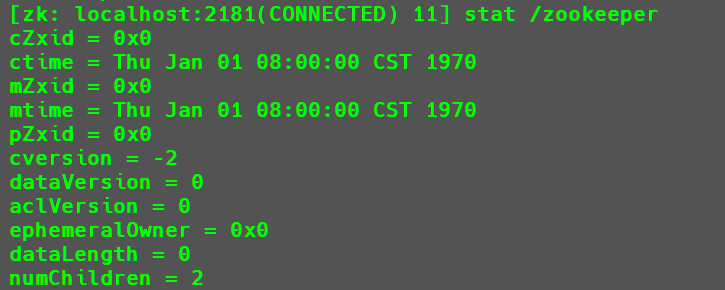
stat /zookeeper
写数据流程
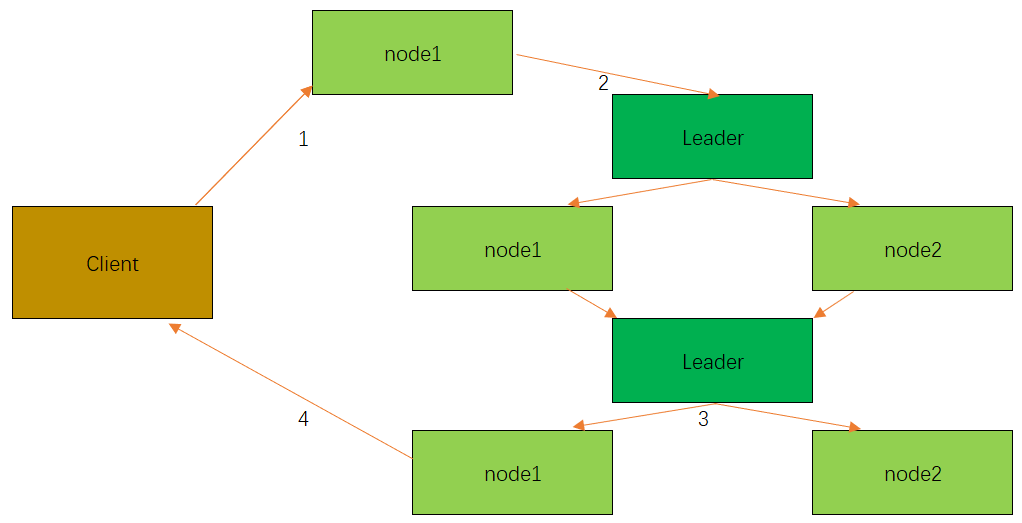
Zookeeper写数据流程分为以下四个步骤:
Client向ZooKeeper的node1上写数据,发送一个写请求。- 如果
node1不是Leader,那么node1会把接受到的请求进一步转发给Leader,因为每个ZooKeeper的node里面必有一个是Leader。这个Leader会将写请求广播给各个node,比如node1和node2,各个node会将该写请求加入待写队列,并向Leader发送成功信息。 - 当
Leader收到半数以上node的成功信息,说明该写操作可以执行。Leader会向各个node发送提交信息,各个node收到信息后会落实队列里的写请求,此时写成功。 node1会进一步通知Client数据写成功了,这时就认为整个写操作成功。