HA概述
- 所谓
HA(High Availablity),即高可用(7 * 24小时不中断服务)。
- 实现高可用最关键的策略是消除单点故障。
HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
NameNode主要在以下两个方面影响HDFS集群
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启。NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用。
HDFS HA功能通过配置多个NameNodes(Active/Standby)实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
HDFS-HA核心问题
如何保证三台NameNode节点数据一致。
Fsimage:让一台nn生成数据,让其他机器nn同步。Edits:需要引进新的模块JournalNode来保证edtis的文件的数据一致性。
新的模块叫做Edits文件管理系统,状态为active的NN生成元数据,然后将数据传输到Edits文件管理系统,由Edits文件管理系统同步给其他服务器的NN。每个节点都会开启一个JournalNode服务,用于与Edits文件管理系统进行数据交互。

怎么让同时只有一台nn是active,其他所有是standby的。
2nn在HA架构中并不存在,定期合并fsimage和edtis的活谁来干。
由standby的nn来干。
如果nn真的发生了问题,怎么让其他的nn上位干活。
手动故障转移
自动故障转移
自动故障转移需要使用到,Zookeeper服务。
这个时候在个节点中都会开启一个ZKFC服务,ZKFC是用来监控NN是否存活,这样当active的NN节点死亡时,ZKFC就会使用Zookeeper服务去告知其他节点的ZKFC服务,当前active的NN已经死亡,使用抢占式原则去激活其他节点的NN来提供服务。
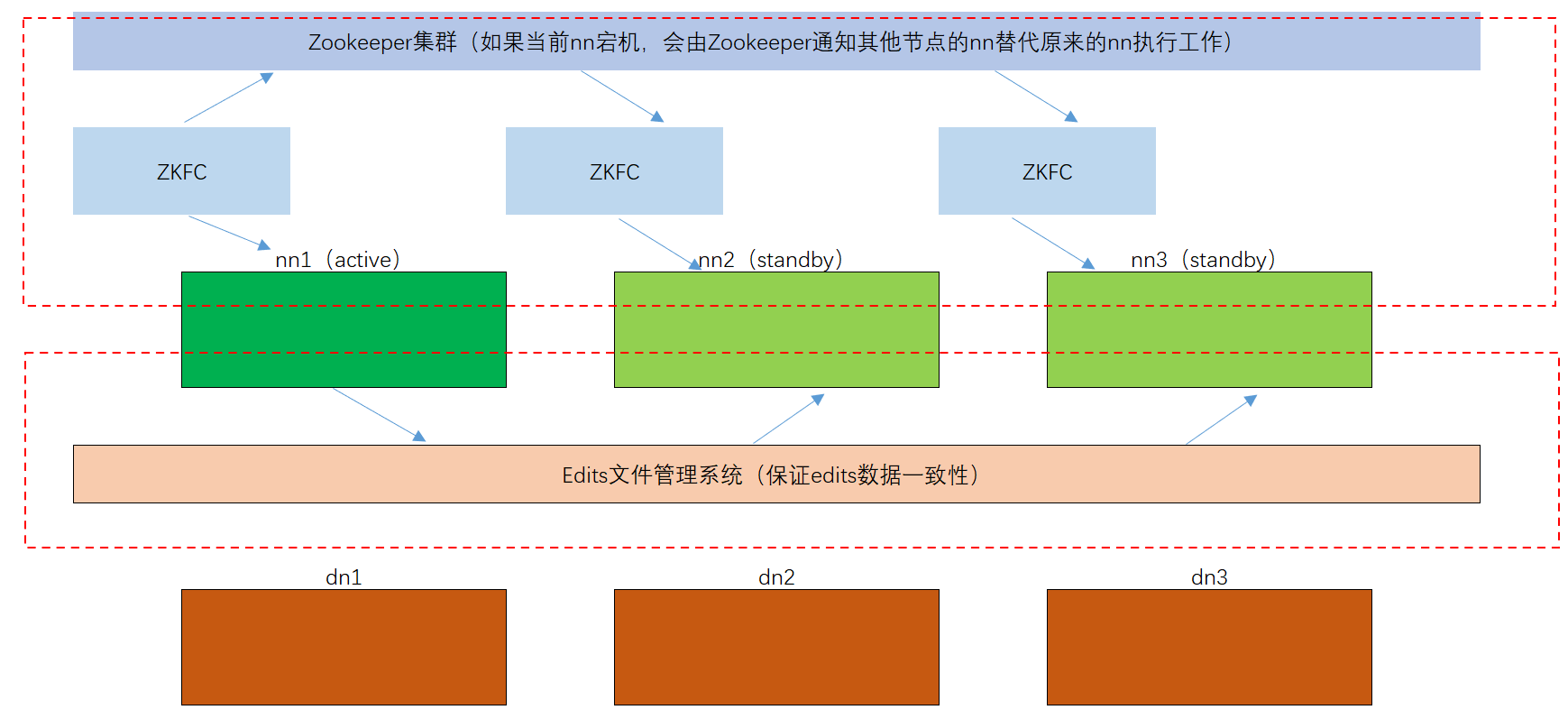
HDFS-HA手动模式
集群规划
| hadoop102 |
hadoop103 |
hadoop104 |
NameNode |
NameNode |
NameNode |
JournalNode |
JournalNode |
JournalNode |
DataNode |
DataNode |
DataNode |
集群配置
备份当前环境快照
注意,由于HA集群配置完毕后需要开启大量的服务,很可能导致我们虚拟机的内存不够,后续还需要学习其他框架(例如:HIVE、Kafka、Flume等等)。
所以,在这里仅学习如何去搭建HA,但是在后面学习其他框架时还是使用基本的Hadoop框架。所以在搭建HA之前,我们首先在虚拟机中把当前状态存储为一个快照,后续方便切换快照。
清理历史集群数据文件
这里我们之前写过hclean脚本直接调用即可。

清空完后重启所有节点。
配置core-site.xml
编辑core-site.xml
1
| vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
|
将配置文件修改为以下内容
1
2
3
4
5
6
7
8
9
10
11
12
13
| <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
</configuration>
|
配置hdfs-site.xml
编辑hdfs-site.xml
1
| vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
|
将配置文件修改为以下内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| <configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop102:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop103:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop104:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop102:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop103:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hadoop104:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/minglog/.ssh/id_rsa</value>
</property>
</configuration>
|
分发配置好的hadoop环境到其他节点
1
| xsync etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml
|
启动所有节点的journalnode服务
1
2
3
| hdfs --daemon start journalnode
ssh hadoop103 hdfs --daemon start journalnode
ssh hadoop104 hdfs --daemon start journalnode
|
在hadoop102节点上进行nn格式化并开启nn
1
2
| hdfs namenode -format
hdfs --daemon start namenode
|
在hadoop103和hadoop104节点上同步hadoop102上的元数据信息
1
2
| ssh hadoop103 hdfs namenode -bootstrapStandby
ssh hadoop104 hdfs namenode -bootstrapStandby
|
在web界面中打开HDFS界面内容
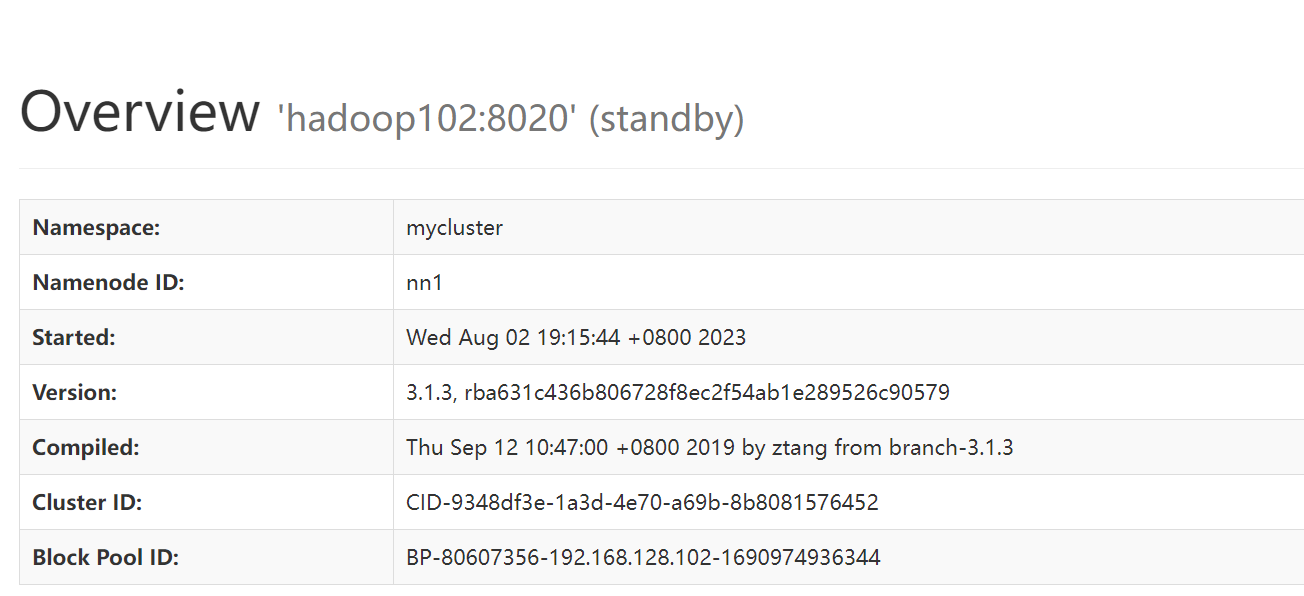
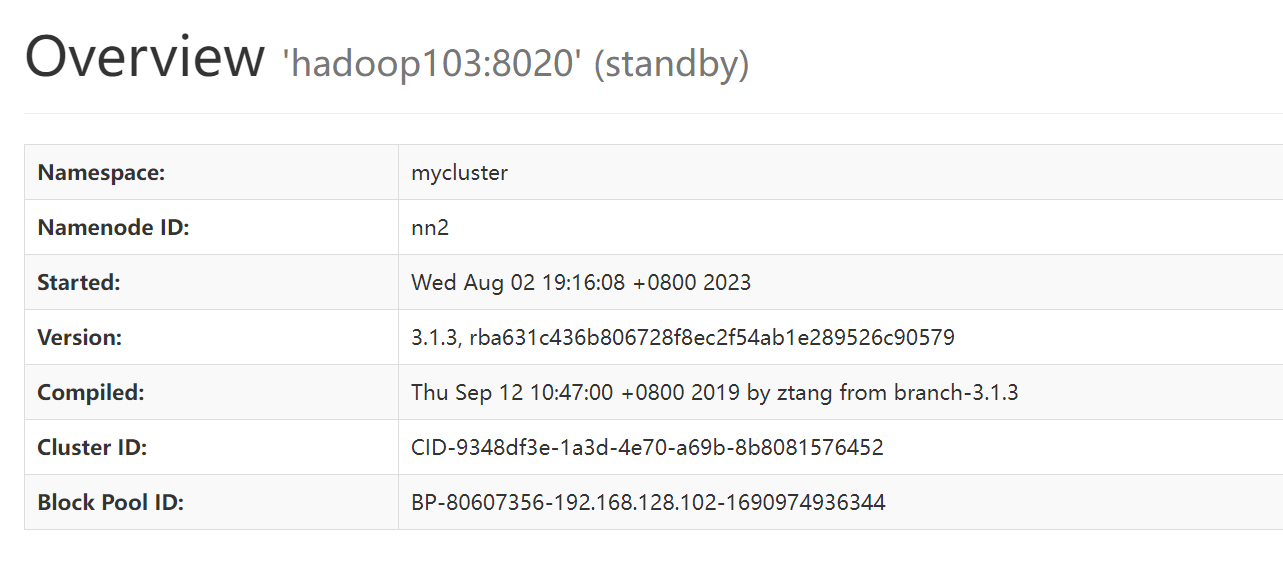
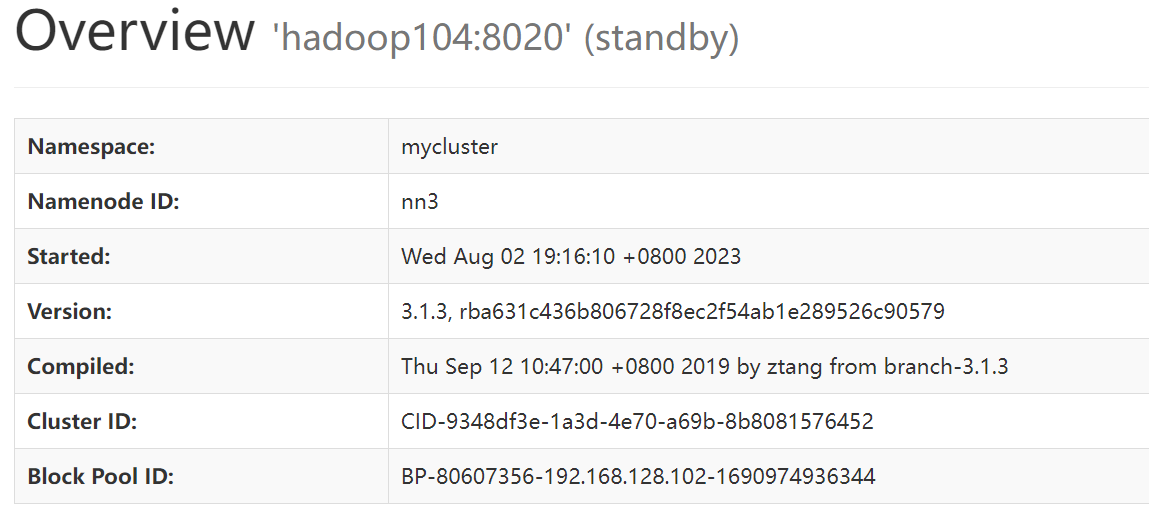
此时所有节点都可以打开9870端口查看对应的HDFS界面,可以看到所有节点的NN状态都是standby。
在所有节点上启动DataNode
1
2
3
| hdfs --daemon start datanode
ssh hadoop103 hdfs --daemon start datanode
ssh hadoop104 hdfs --daemon start datanode
|
查看当前所有节点的java进程
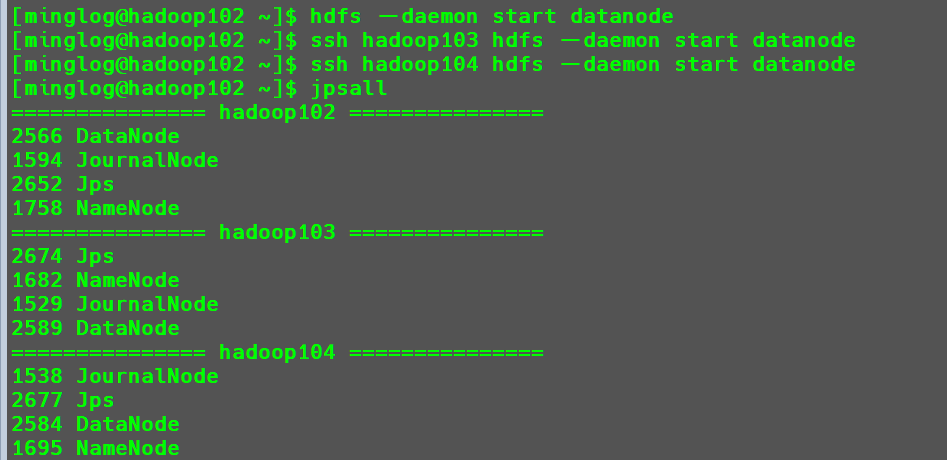
将hadoop102节点NN状态修改为active
1
| hdfs haadmin -transitionToActive nn1
|
查看状态
1
| hdfs haadmin -getServiceState nn1
|

在web界面中也可以看到状态为active
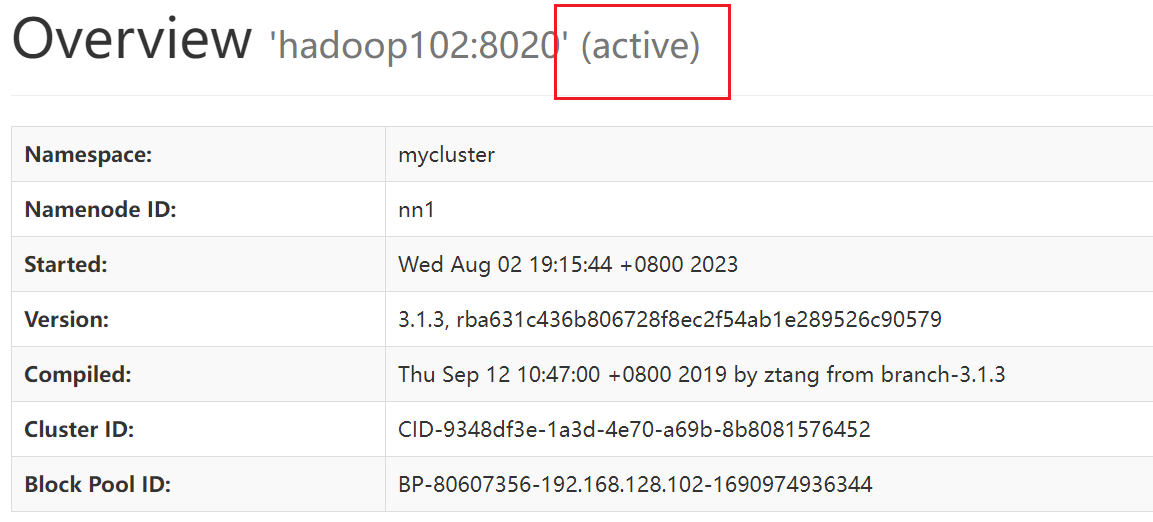
到这里我们就可以手动控制每一个节点的NN状态,如果当前NN节点出现故障死亡,可以手动启动其他节点的NN节点接替其NN工作。
但是手动切换还是十分繁琐,需要人工去监控当前NN节点是否死亡,如果死亡还需要手动切换,在这之间的时间就无法使用集群的服务了。这个问题是可以解决的,在hadoop中给我们提供了另外一种HA的配置方式,HDFS-HA自动模式。
HDFS-HA自动模式
自动故障转移为HDFS部署增加了两个新组件:ZooKeeper和ZKFailoverController(ZKFC)进程,如图所示。ZooKeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。
集群规划
| hadoop102 |
hadoop103 |
hadoop104 |
NameNode |
NameNode |
NameNode |
JournalNode |
JournalNode |
JournalNode |
DataNode |
DataNode |
DataNode |
Zookeeper |
Zookeeper |
Zookeeper |
ZKFC |
ZKFC |
ZKFC |
集群配置
在core-site.xml文件中增加以下内容
1
2
3
4
5
|
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>
|
在hdfs-site.xml中增加以下内容
1
2
3
4
5
|
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
|
修改后分发配置文件
1
| xsync core-site.xml hdfs-site.xml
|
关闭所有HDFS服务
启动Zookeeper集群
初始化HA在Zookeeper中状态
初始化完毕后在Zookeeper下就会生成一个hadoop-ha节点

启动HDFS服务
然后查看所有节点的java进程。

可以看到现在已经按照我们前面对集群的规划成功开启所有服务了。
这个时候进入到所有节点的HDFS的WEB界面。
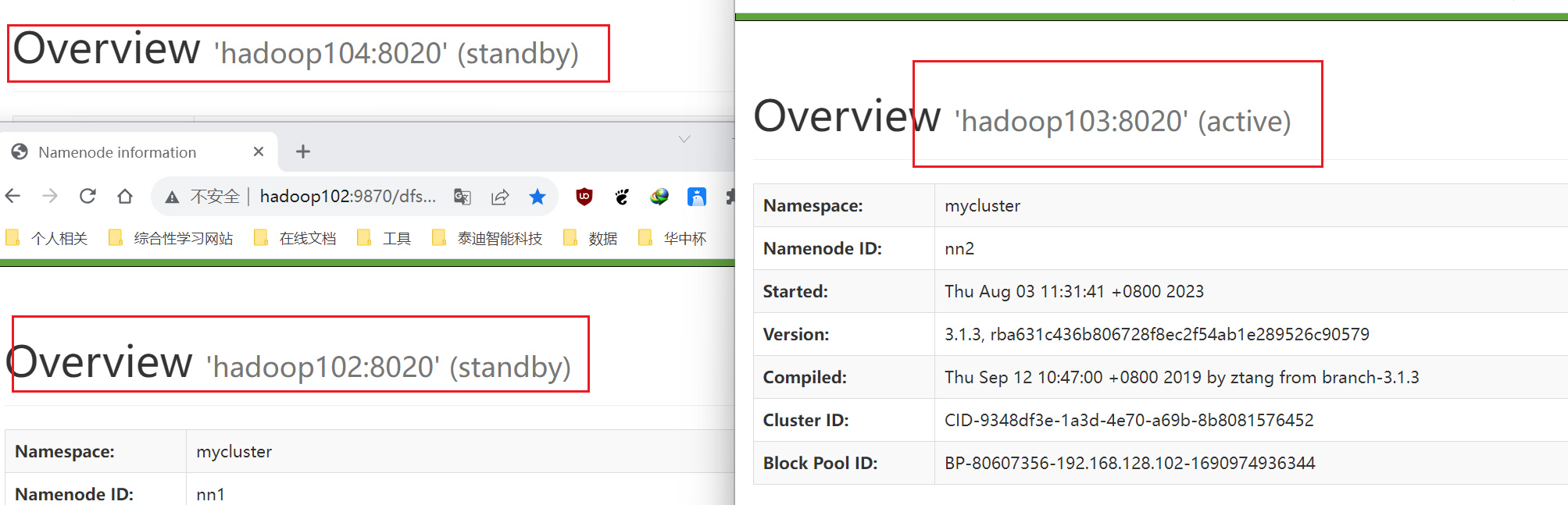
可以看到此时Hadoop103节点的NN状态为active,其他节点为standby。
为了验证其自动故障转移效果,这个时候我们手动关闭Hadoop103节点的NN。
1
| ssh hadoop103 hdfs --daemon stop namenode
|
这个时候重新打开所有节点的WEB界面。
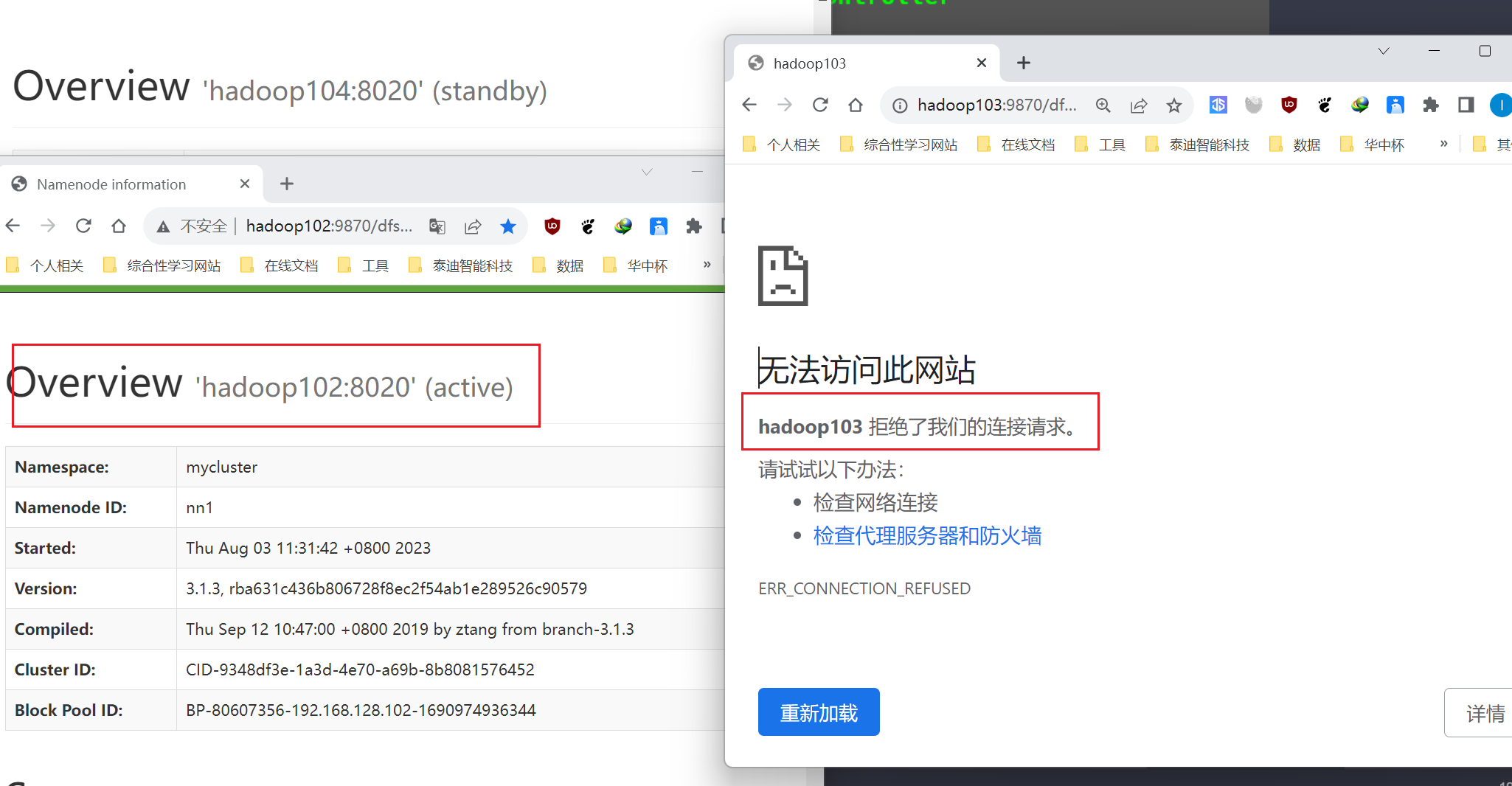
此时可以看到hadoop103节点的WEB界面已经无法进入了,说明其服务已经被关闭。并且此时hadoop102节点的NN状态自动修改成了active,接替hadoop103的NN继续为集群提供服务。
YARN-HA配置
前面我们已经把HDFS的高可用HA集群搭建完毕了,但是除了HDFS中的NN异常会导致集群服务异常之外,还有YARN中的RM(ResourceManager)异常,会导致集群无法调用计算资源执行任务。
这个时候我们就需要在多个节点中配置ResourceManager,使得集群容错性进一步增大。
基本原理
YARN-HA基本原理和HDFA-HA原理一样,都是使用一个中间节点ZKFC去监控RM的状态,一但RM状态出现问题,立即通知Zookeeper,然后由Zookeeper通知其他节点的ZKFC激活一个RM状态为active为集群提供服务。
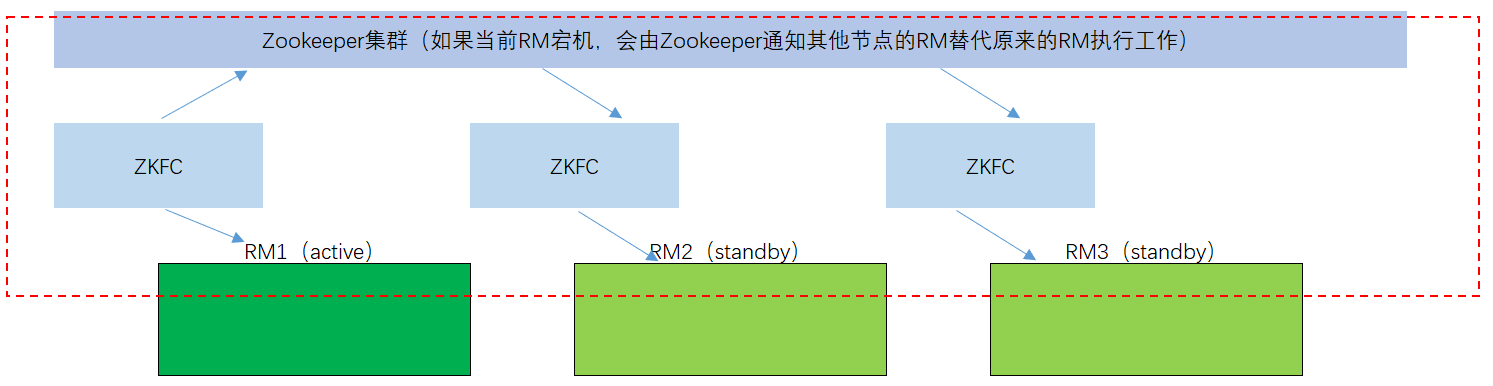
集群规划
| hadoop102 |
hadoop103 |
hadoop104 |
ResourceManager |
ResourceManager |
ResourceManager |
NodeManager |
NodeManager |
NodeManager |
Zookeeper |
Zookeeper |
Zookeeper |
具体配置
修改yarn-site.xml中的内容为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
| <configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop102</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop102:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop102:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop102:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop102:8031</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop103</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop103:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop103:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop103:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop103:8031</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>hadoop104</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>hadoop104:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm3</name>
<value>hadoop104:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm3</name>
<value>hadoop104:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm3</name>
<value>hadoop104:8031</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
|
分发配置
启动YARN
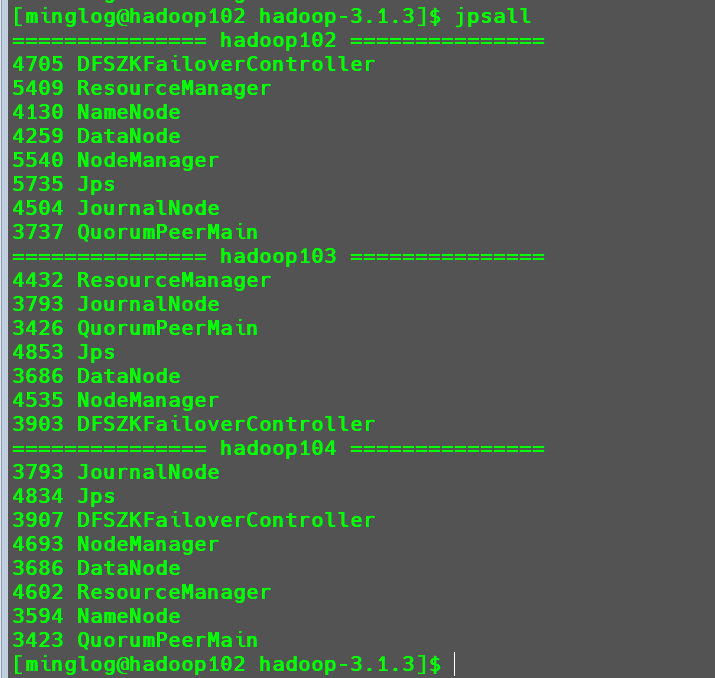
这个时候每个节点都有RM服务。查看每个节点的RM服务状态。
1
2
3
| yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
yarn rmadmin -getServiceState rm3
|

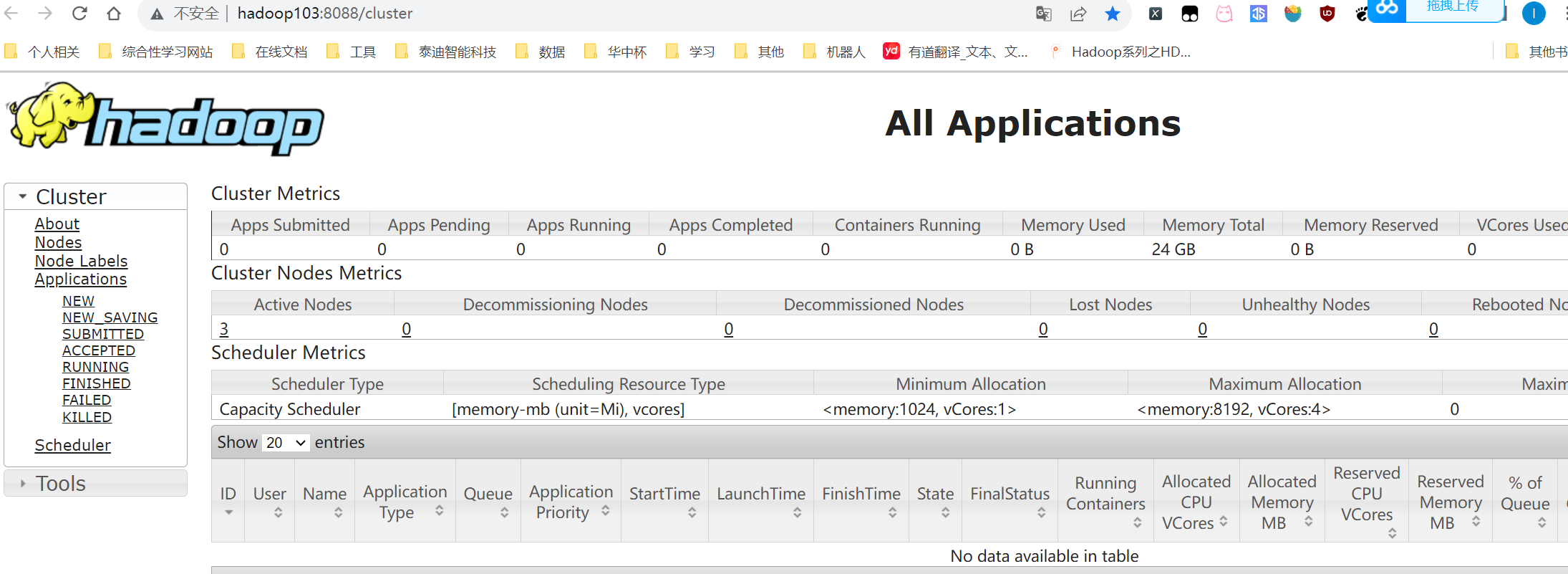
可以看到此时激活的RM为hadoop103中的RM服务,这个时候无论访问哪个节点的YARN的WEB界面,都只会返回hadoop103节点的YARN界面。
HA总结
现在我们已经将HDFS和YARN这两个服务的HA都配置完成了,这也是在生产环境中为了保证集群的高可用性能,需要做的一些配置。
最终集群规划如下所示:
| hadoop102 |
hadoop103 |
hadoop104 |
| NameNode |
NameNode |
NameNode |
| JournalNode |
JournalNode |
JournalNode |
| DataNode |
DataNode |
DataNode |
| Zookeeper |
Zookeeper |
Zookeeper |
| ZKFC |
ZKFC |
ZKFC |
| ResourceManager |
ResourceManager |
ResourceManager |
| NodeManager |
NodeManager |
NodeManager |
需要注意的是,尽管这种高可用集群有非常多的优点,但是每次集群启动的时候都需要这么多服务,这对于我们单机来说是做不到的,单机内存不足以支撑HA集群的运行,所以为了方便后续继续学习更多的框架,后续的集群我们还是使用原生的Hadoop来进行。所以这里我们将HA配置完成后可以对当前虚拟机打一个快照,然后将集群状态还原到开篇我们让大家打的快照Zookeeper。