Hive数据类型
在Hive种数据类型分为两种:
- 基本数据类型
- 集合数据类型
基本数据类型
| Hive数据类型 | Java数据类型 | 长度 | 例子 |
|---|---|---|---|
TINYINT |
byte |
1byte有符号整数 |
20 |
SMALINT |
short |
2byte有符号整数 |
20 |
| INT | int |
4byte有符号整数 |
20 |
| BIGINT | long |
8byte有符号整数 |
20 |
BOOLEAN |
boolean |
布尔类型,true或者false |
TRUE FALSE |
FLOAT |
float |
单精度浮点数 | 3.14159 |
| DOUBLE | double |
双精度浮点数 | 3.14159 |
| STRING | string |
字符系列。可以指定字符集。 可以使用单引号或者双引号。 |
Hello world! |
TIMESTAMP |
时间类型 | ||
BINARY |
字节数组 |
对于
Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
STRUCT |
和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如:如果某个列的数据类型是 STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 |
struct()例如: struct<street:string, city:string> |
MAP |
MAP是一组键-值对元组集合,使用数组表示法可以访问数据。 例如: 如果某个列的数据类型是MAP,其中键->值对是first->John和last->Doe,那么可以通过字段名[last]获取最后一个元素 |
map() 例如: map<string, int> |
ARRAY |
数组是一组具有相同类型和名称的变量的集合。 这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。 例如: 数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 |
Array()例如:array<string> |
Hive有三种复杂数据类型ARRAY、MAP和STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
案例实操
如何使用Hive去访问JSON格式数据。
例如以下JSON数据:
1 | { |
这里我们不在Hive中直接导入JSON数据,而是将上述数据改写为如下格式,并存储为文件personInfo,存放在目录/opt/module/hive-3.1.2/datas下(目录不存在则手动创建):
1 | zhangsan,lisi_wangwu,xiao zhangsan:8_xiaoxiao zhangsan:10,hongshan_wuhan |
注意:
MAP,STRUCT和ARRAY里的元素间关系都可以用同一个字符表示,这里用_。
首先进入到Hive客户端,然后执行以下代码创建表。
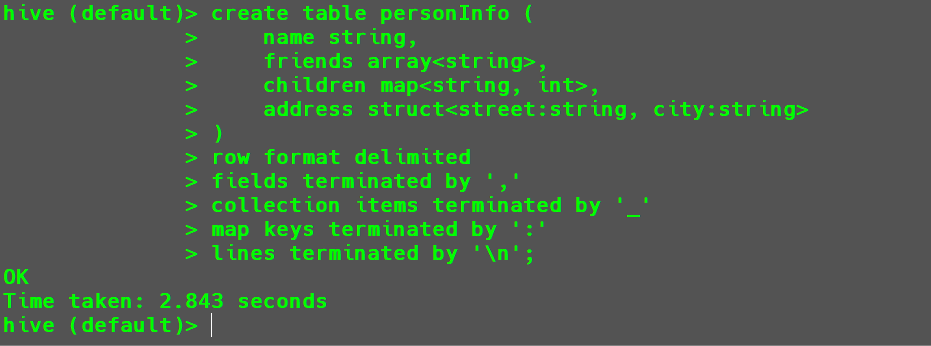
1 | hive(default)>create table personInfo ( |
下方声明代码意义如下所示:
row format delimited:指定数据文件中行格式的分隔符
fields terminated by ',':指定字段之间用’,’进行分割
collection items terminated by '_':指定集合类型的元素之间用’_’进行分割
map keys terminated by ':':指定map类型中key和value用’:’进行分割
lines terminated by '\n';:指定行之间的分隔符为’\n’
然后将数据文件上传到HDFS,在目录/user/hive下创建文件夹datas,然后将文件上传到datas目录。
1 | hdfs dfs -put personInfo /user/hive/warehouse/personinfo |
接下来执行以下代码对其进行查询操作。
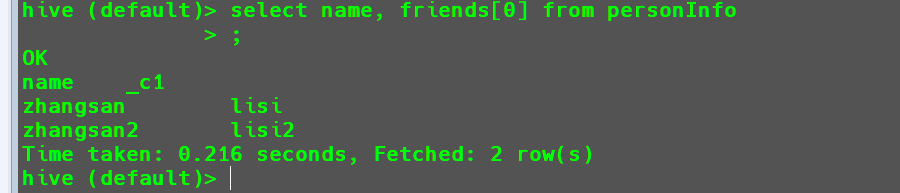
查询所有数据的姓名以及第一个朋友姓名。
1
select name, friends[0] from personInfo;
查询所有人对应的街道名称
1
select name, address.street from personInfo;

查询孩子
xiao zhangsan的年龄。1
select children['xiao zhangsan'] from personInfo;

可以看到
children xiao zhangsan对应的年龄为8岁,并且由于第二条数据中没有xiao zhangsan这个孩子,所以其返回的结果为NULL。这里要注意,没有字段的时候会返回
NULL。
类型转换
Hive的基本数据类型是可以进行隐式转换的,类似于Java的类型转换例如:某表达式使用
INT类型,TINYINT会自动转换为INT类型,但是
Hive不会进行反向转化。例如,某表达式使用TINYINT类型,INT不会自动转换为TINYINT类型,它会返回错误,除非使用CAST操作。隐式类型转换规则如下:
- 任何整数类型都可以隐式地转换为一个范围更广的类型,如
INT可以转换成BIGINT。 - 所有整数类型、
FLOAT和STRING类型都可以隐式地转换成DOUBLE。 TINYINT、SMALLINT、INT都可以转换为FLOAT。BOOLEAN类型不可以转换为任何其它的类型。
- 任何整数类型都可以隐式地转换为一个范围更广的类型,如
可以使用
CAST操作显示进行数据类型转换例如:
CAST('1' AS INT)将把字符串'1'转换成整数1;
如果强制类型转换失败,如执行CAST('X' AS INT),表达式返回空值NULL。
演示如下:
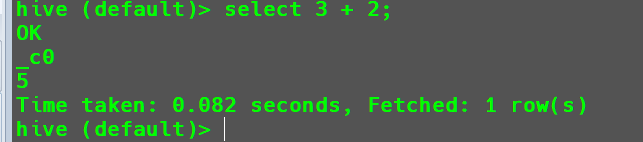
在
Hive中执行数值运算操作。1
select 3 + 2;
在
Hive中执行3 + '2'。1
select 3 + '2';
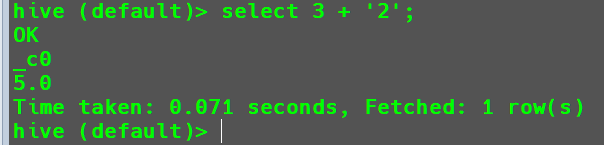
在此返回的结果是
5.0,原因是因为3和'2'的数据类型不一致,会触发隐式类型转化,将3转化为Double类型的3.0,也将'2'转化为Double类型的2.0,然后再将其相加得到结果5.0。在
Hive中执行3 + '2',并希望得到整数结果。1
select 3 + cast('2' as int);
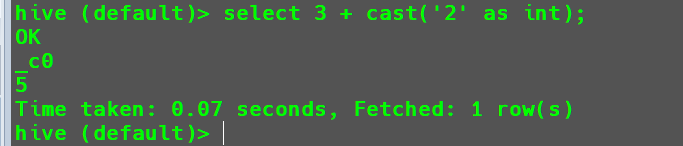
DDL数据定义
数据定义语言(Data Definition Language,DDL)是SQL语言集中负责数据结构定义与数据库对象定义的语言,由CREATE、ALTER与DROP三个语法所组成,现在被纳入SQL指令中作为其中一个子集。
数据库操作
数据库的创建
创建数据库的基本语法
1 | CREATE DATABASE [IF NOT EXISTS] database_name |
创建一个数据库,数据库在HDFS上的默认存储路径是/user/hive/warehouse/*.db。
1 | create database people; |

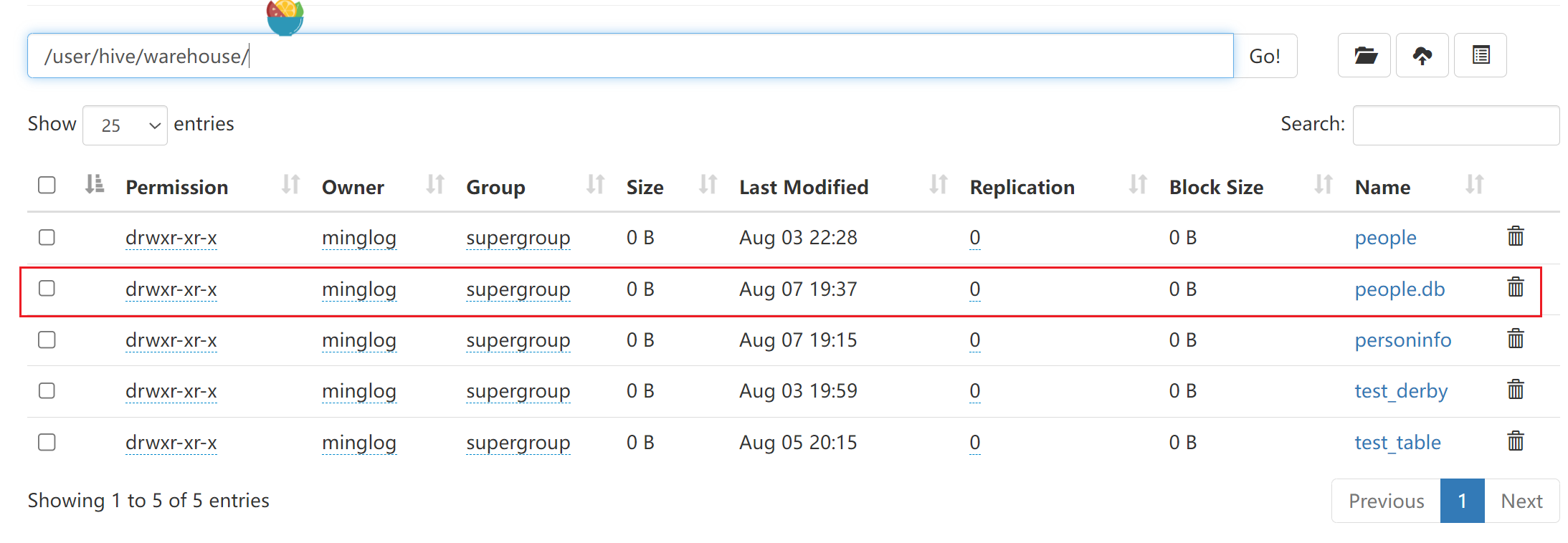
有的时候当我们的数据库较多,无法去辨认当前新建数据库的名称是否存在,而创建重复的数据库会发生报错。

为了避免重复创建数据库导致报错,可以在创建数据库的时候加上if not exists参数。
1 | create database if not exists people; |

这个时候就不会报错了。
创建数据库指定数据库在
HDFS中保存的位置,例如在根目录下创建数据库。1
create database bigdata2 location '/bigdata.db';
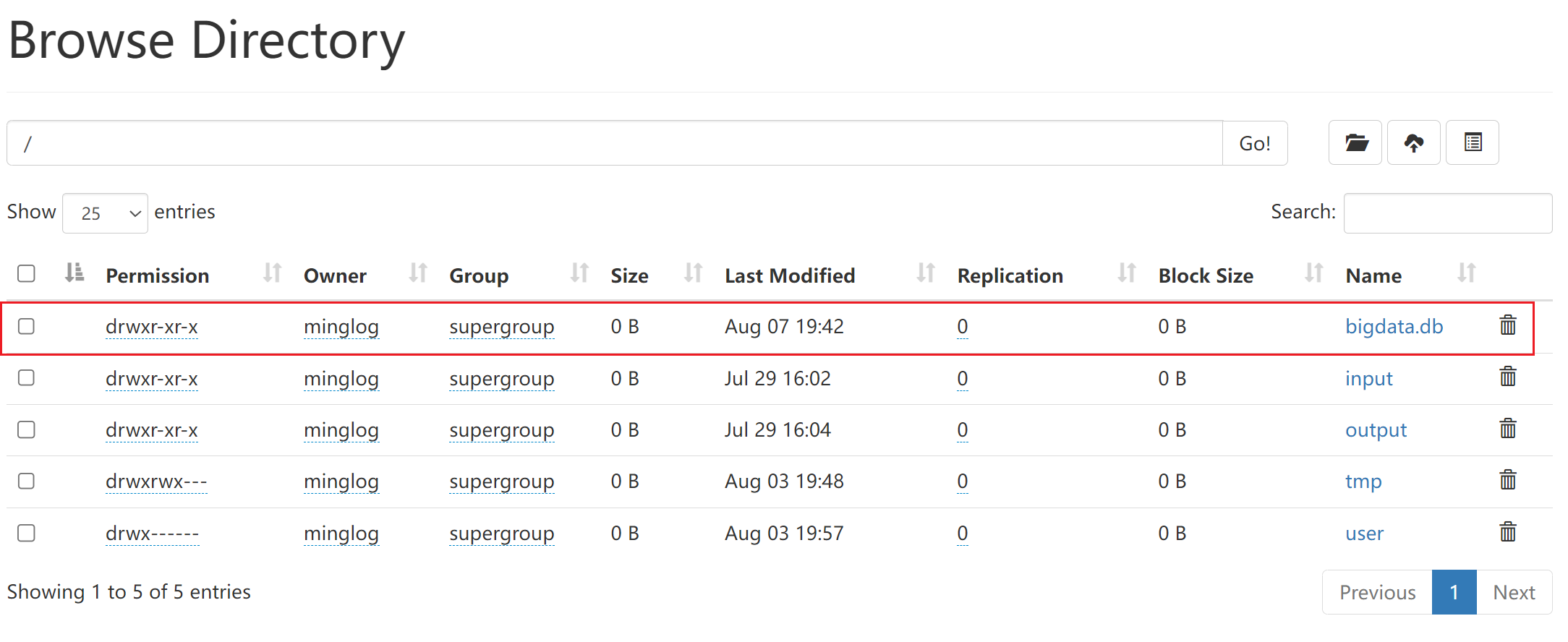
然后在该数据库下去创建表。
1
create table bigdata.student(id int, name string);

然后回到
HDFS页面下去查看bigdata.db文件夹内容。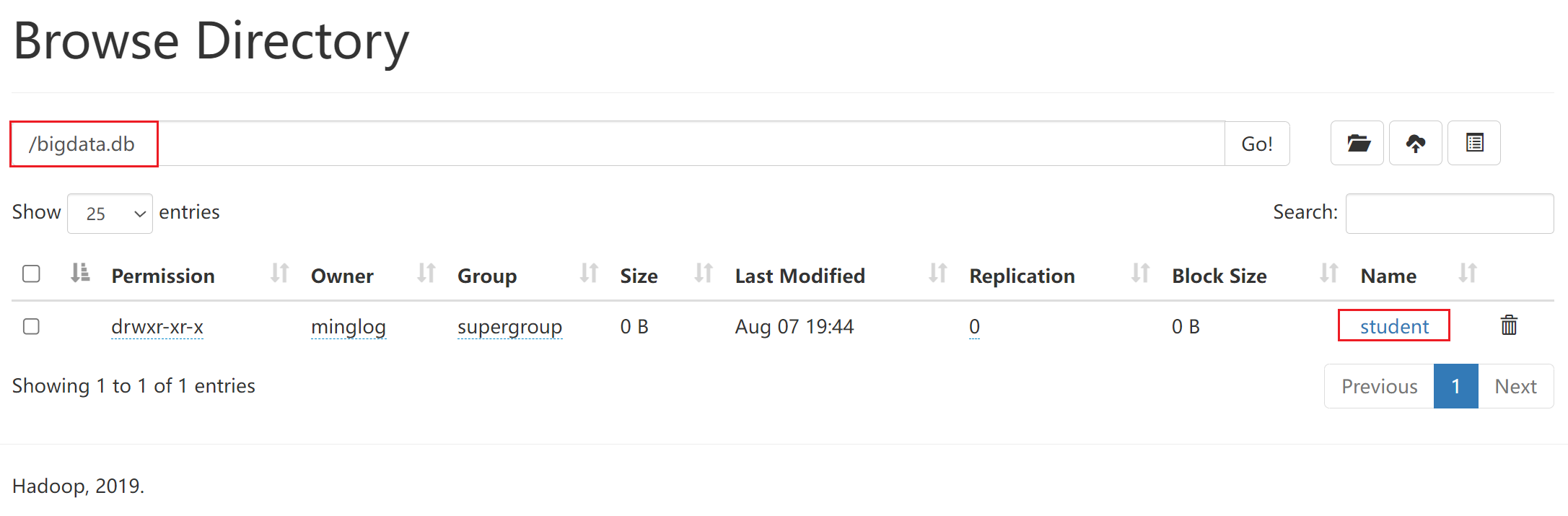
此时在该文件夹下就可以查看到了我们创建的数据表。
数据库的查询
显示当前所有数据库
查询所有数据库
1 | show databases; |
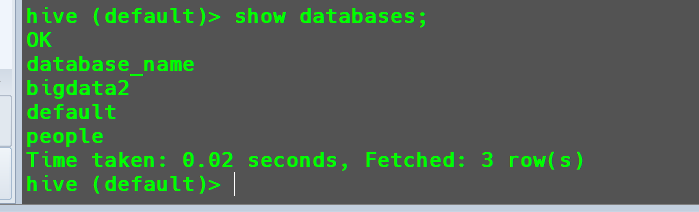
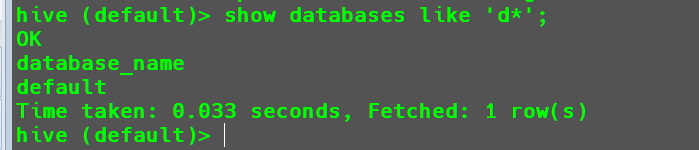
当数据库较多时,还可以在查询的过程中添加筛选。
例如找出d开头的数据库。
1 | show databases like 'd*'; |
查看数据库详情
显示数据库信息。
1 | desc database bigdata2; |

默认情况下是不显示
parameters参数值的内容的。想要显示内容需要添加extended参数。
这里也没有显示
parameters内容,原因是因为我们在创建数据库时没有指定参数。创建数据库
bigdata3,并设置其createtime属性。
查看
bigdata3详细内容。


切换当前数据库
1 | use bigdata3; |

查询当前表
1 | show tables; |
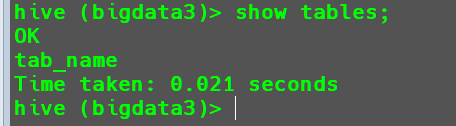
此时可以看到切换数据库后,查询不到表了,因为我们在bigdata3这个数据库中没有创建表。
数据库的修改
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。数据库其他的元数据信息都是不可以修改的,包括数据库名和数据库所在的目录位置。
1 | alter database bigdata2 set dbproperties('createtime'='20230807'); |
查询bigdata2的描述信息。
1 | desc database extended bigdata2; |

数据库的删除
删除空数据库
1 | drop database bigdata3; |
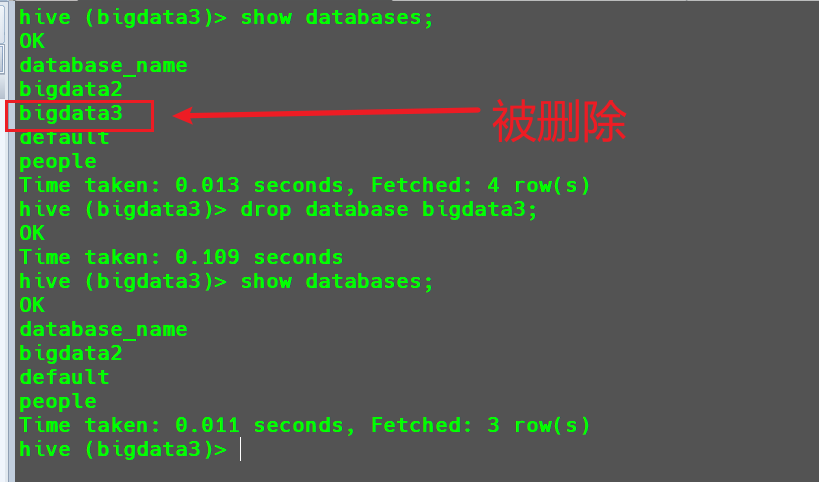
当要删除的数据库不存在时,使用上述命令进行直接删除会报错。
1
drop database bigdata3;

为了保证不报错,也可以使用以下方法对其进行判断,当前数据库存在时执行删除命令,不存在什么也不做。
1
drop database if exists bigdata3;
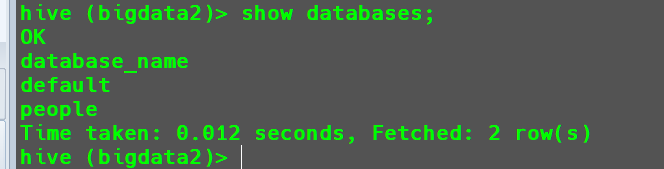
当删除的数据库非空时,使用直接删除操作也会报错。
1
drop database bigdata2;

这个时候要想强制删除,需要在末尾加上
cascade参数。1
drop database bigdata2 cascade;

数据表操作
创建表
基本语法如下:
1 | CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name |
字段解释说明
| 参数命令 | 参数意义 | |
|---|---|---|
CREATE TABLE |
创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常 | |
EXTERNAL |
1) 关键字可以让用户创建一个外部表 在建表的同时可以指定一个指向实际数据的路径(LOCATION) 2) 在删除表的时候 内部表的元数据和数据会被一起删除, 外部表只删除元数据,不删除数据。 |
|
COMMENT |
为表和列添加注释。 | |
PARTITIONED BY |
创建分区表 | |
CLUSTERED BY |
创建分桶表 | |
SORTED BY |
不常用,对桶中的一个或多个列另外排序 | |
ROW FROMAT |
ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char][MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)] |
Fields 指定字段之间的分隔符 Collection 用于指定集合中元素间的分隔符 Map 用于指定map集合中键值对间的分隔符 Lines 用于指定每行记录间的分隔符 SerDe是 Serialize/Deserialize的简称 用户在建表时可以自定义SerDe或使用自带的SerDe 若未指定Row Format,则用自带的 SerDe |
STORE AS |
指定存储文件类型 常用的文件存储类型: SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件) 如:store as textfile、store as sequencefile |
|
LOCATION |
指定表在HDFS上的存储位置 | |
AS |
后跟查询语句,根据查询语句结果创建表 | |
LIKE |
允许用户复制现有的表结构,但是不复制数据 |
管理表(内部表)
- 默认创建的表都是所谓的管理表,有时也被称为内部表。
- 管理表,
Hive会控制着元数据和真实数据的生命周期。 Hive默认会将这些表的数据存储在hive.metastore.warehouse.dir定义目录的子目录下。- 当我们删除一个管理表时,
Hive也会删除这个表中数据。 - 管理表不适合和其他工具共享数据。
案例实操:
首先在文件夹/opt/module/hive-3.1.2/datas下创建文件student.txt,然后在该文件中输入以下内容:
1 | 1001 ss1 |
接下来在Hive下创建内部表students。
1 | -- 创建表 |
然后将数据加载到students中
1 | -- 加载数据 |
查询加载的数据
1 | -- 查询数据导入结果 |
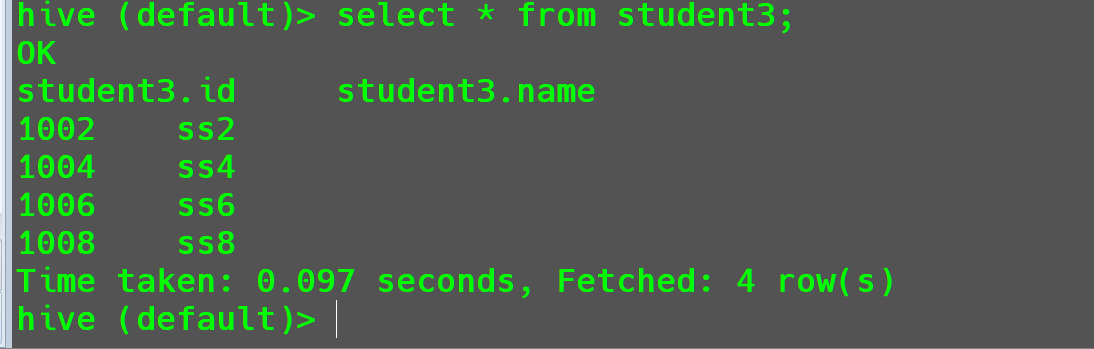
AS参数的使用创建一个表
student3,表中的内容是students中id为偶数的行。1
create table if not exists student3 as select * from students where id % 2 = 0;
这个时候就需要走
MR实现上述操作。
查看结果
LIKE参数的使用创建一个和
students结构一样的表student4。1
2-- 创建一个和`students`结构一样的表`student4`。
create table if not exists student4 like students;此时,只创建结构就不需要走
MR。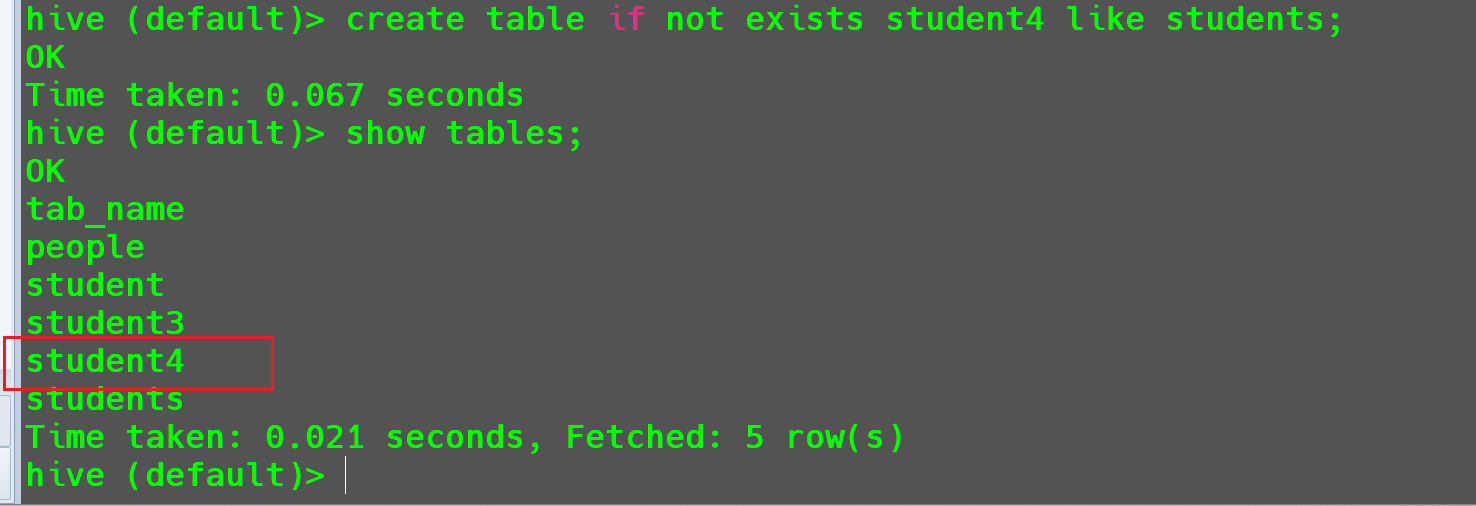
接下来演示删除内部表后,结构和数据都会被删除,以student3表为例。
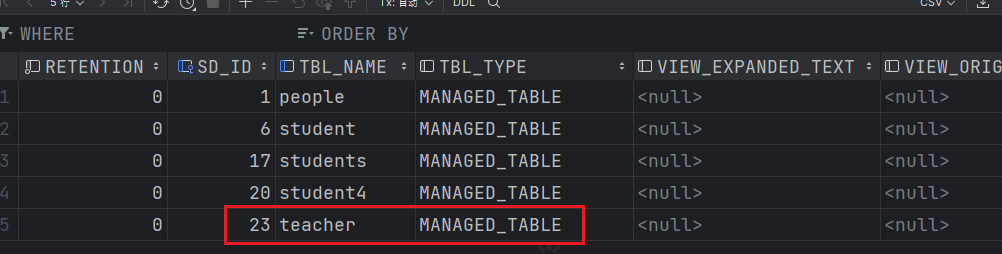
首先在hadoop102的mysql中Hive数据库下的TBLS查看student3的元数据信息。
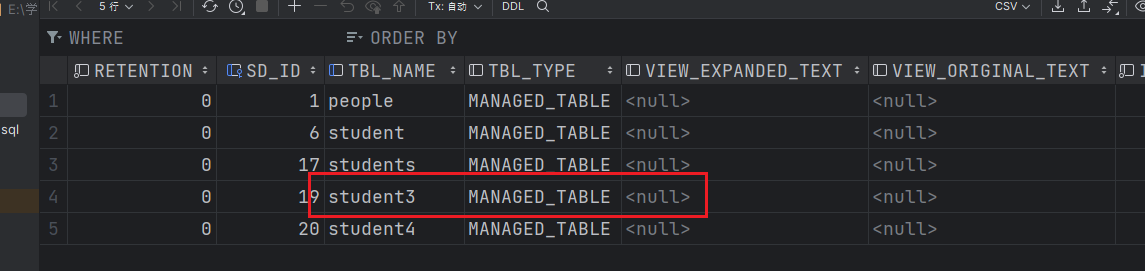
元数据存在。
然后在HDFS中查看student3表的真实数据。
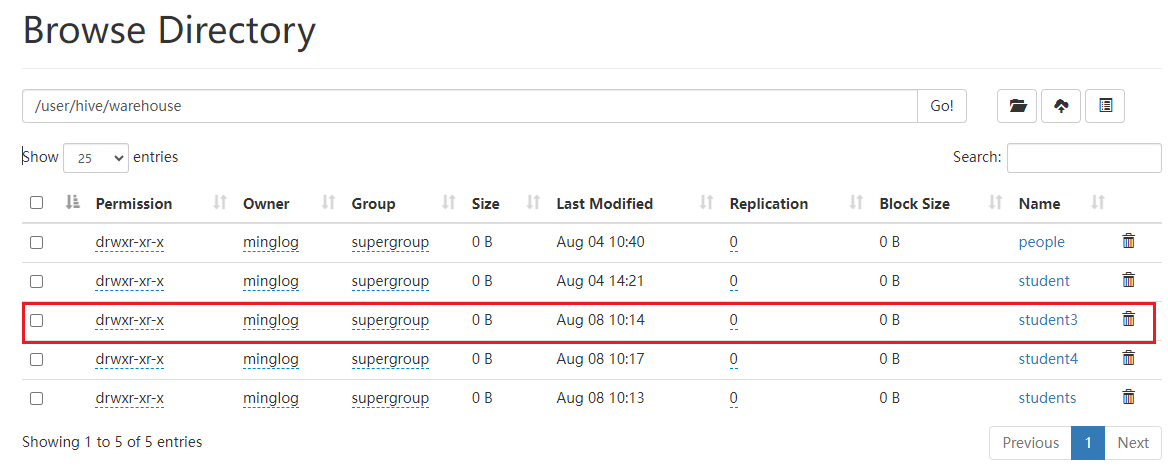
真实数据同样存在。
接下来,执行以下命令删除student3表。
1 | drop table student3; |
这个时候再次查看Hive的元数据表TBLS。
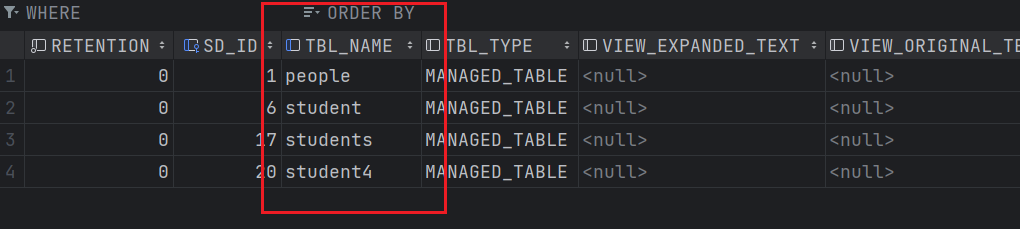
此时student3表的元数据已经被删除。
接下来回到HDFS中查看真实数据。
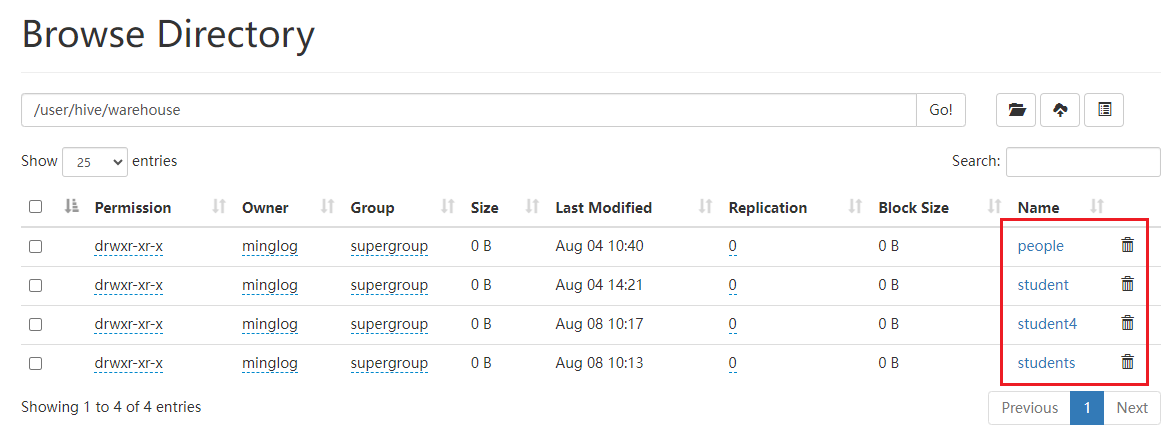
真实数据同样被删除。
内部表在删除的时候会将元数据和真实数据全部删除,导致它不适用于存储一些多个业务共享的数据,因为一旦一个业务中把数据删除了,另外一个业务也会因为无法获取数据而导致瘫痪,这种情况一般改为使用外部表。
外部表
外部表在Hive看来并非认为其完全拥有这份数据,所以删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
案例演示:
首先在/opt/module/hive-3.1.2/datas下创建teacher.txt,文件内容如下所示:
1 | 1001 teacher1 |
然后在Hive中创建teacher表:
1 | create external table if not exists teacher( |
然后将数据导入teacher表。
1 | load data local inpath '/opt/module/hive-3.1.2/datas/teacher.txt' into table teacher; |
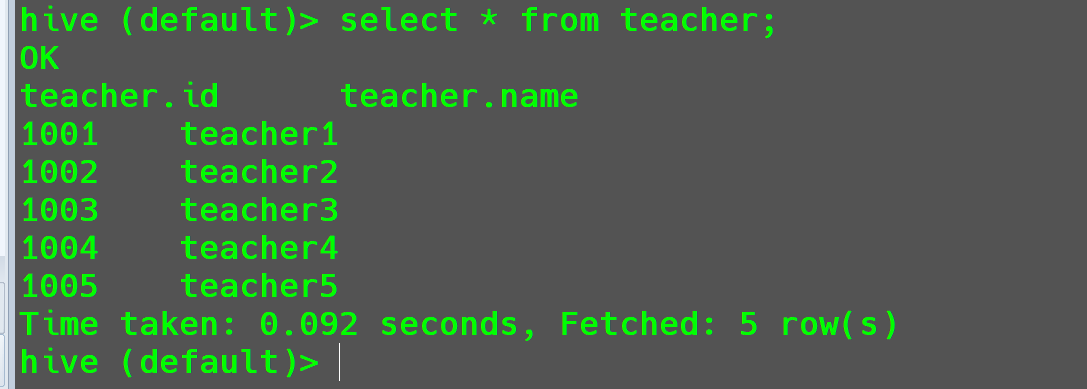
查看导入结果:
1 | select * from teacher; |
接下来演示删除外部表。
首先查看teacher的元数据信息。
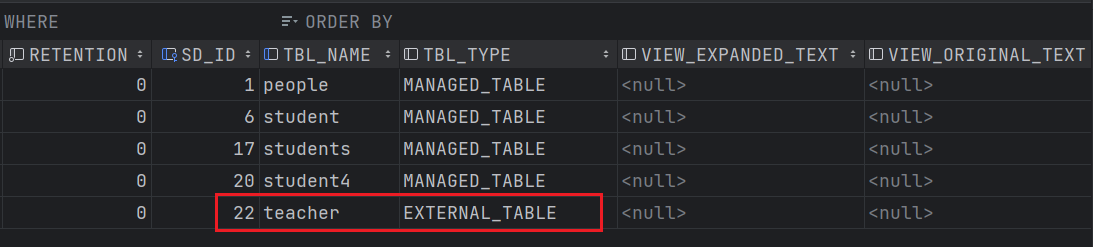
可以看到teacher表对应的TBL_TYPE也被修改为了EXTERNAL_TABLE。
这个信息使用以下命令也可以查看:
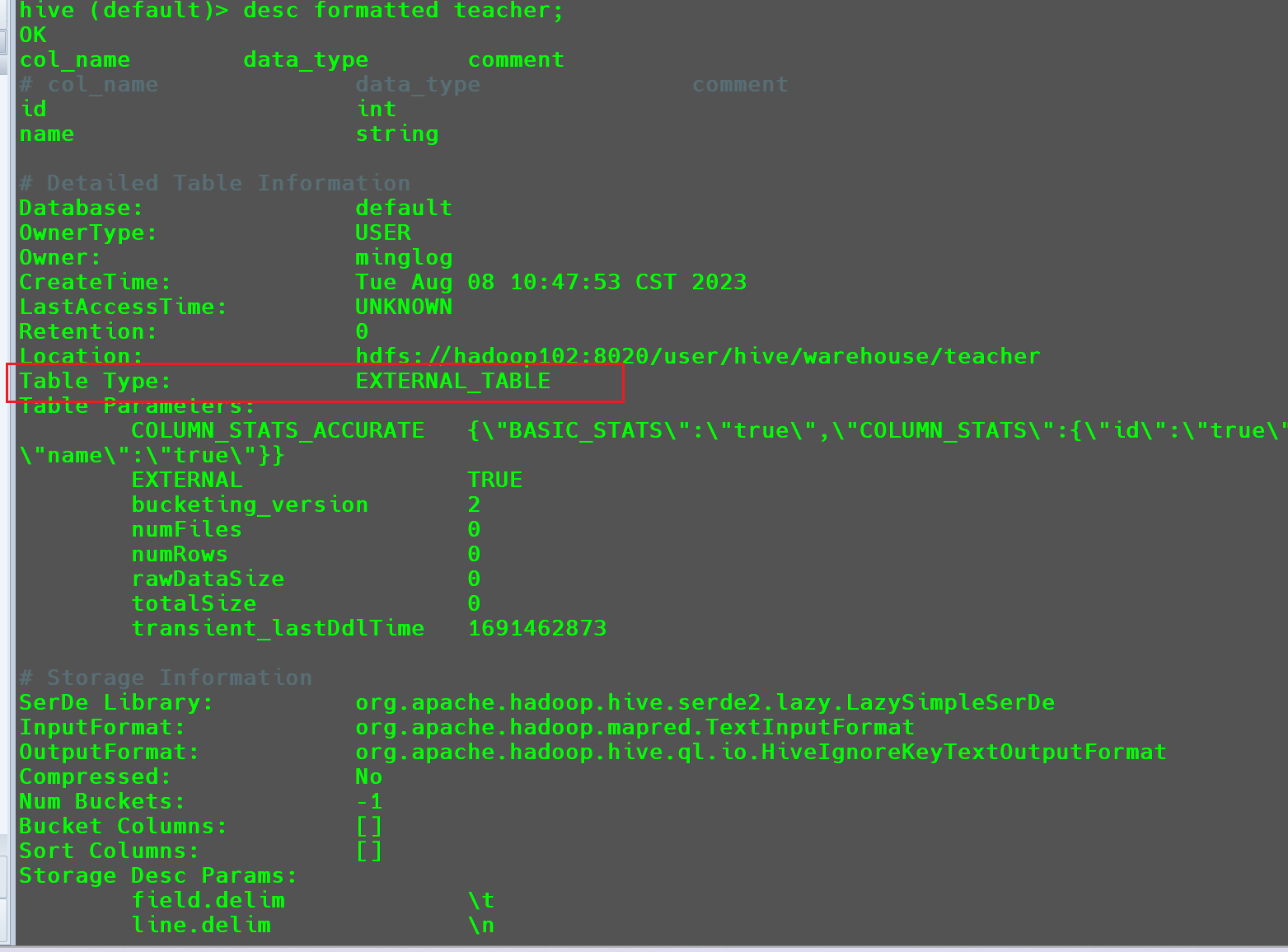
然后查看在HDFS下的真实数据。
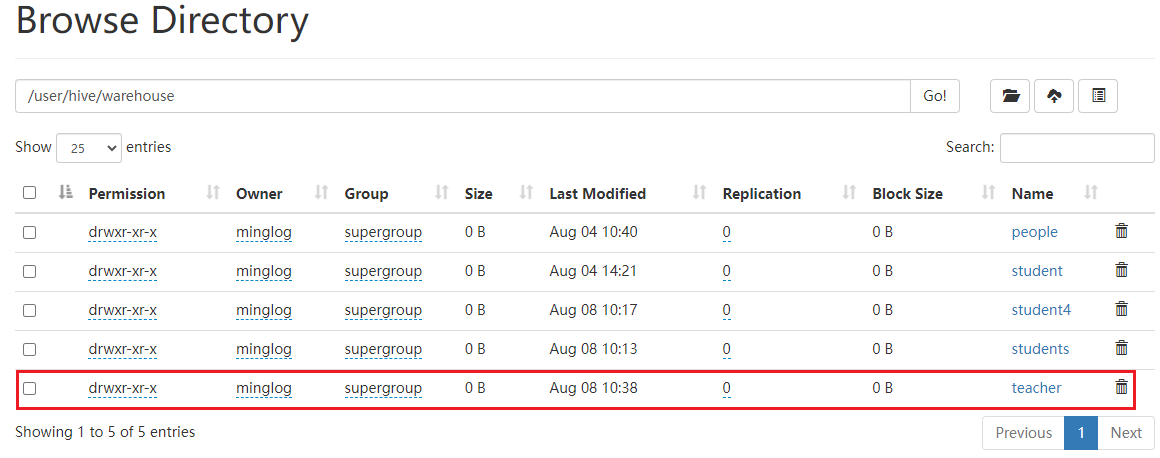
真实数据存在。
接下来删除外部表。
1 | drop table teacher; |
此时再次查看元数据。
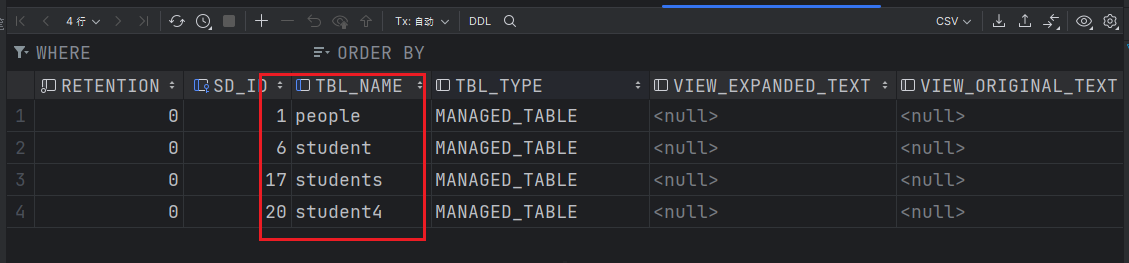
发现teacher表的元数据信息已被删除。
并且使用show tables;也无法查看到teacher表。
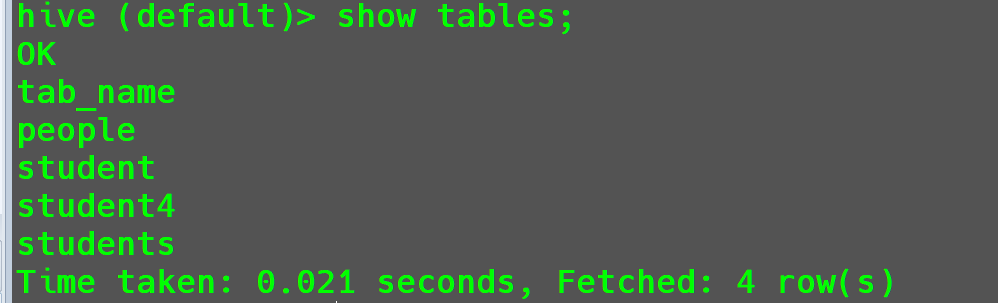
然后,查看HDFS上的真实数据。
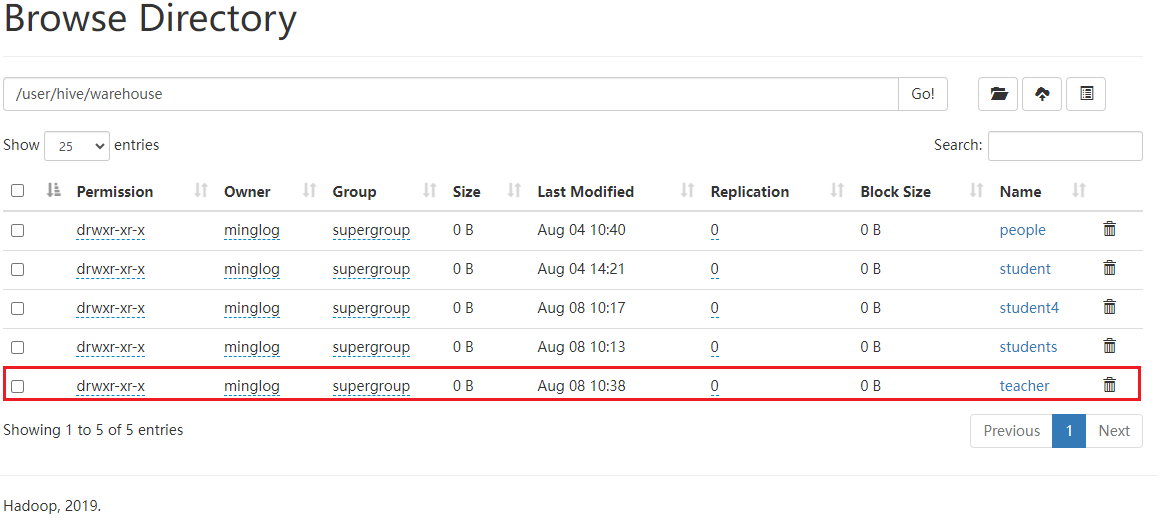
真实数据仍然存在。
由于真实数据没有被删除,所以外部表被删除后数据是可以恢复的,直接重新创建teacher表即可。
1 | create external table if not exists teacher( |
再次查看teacher表数据信息。
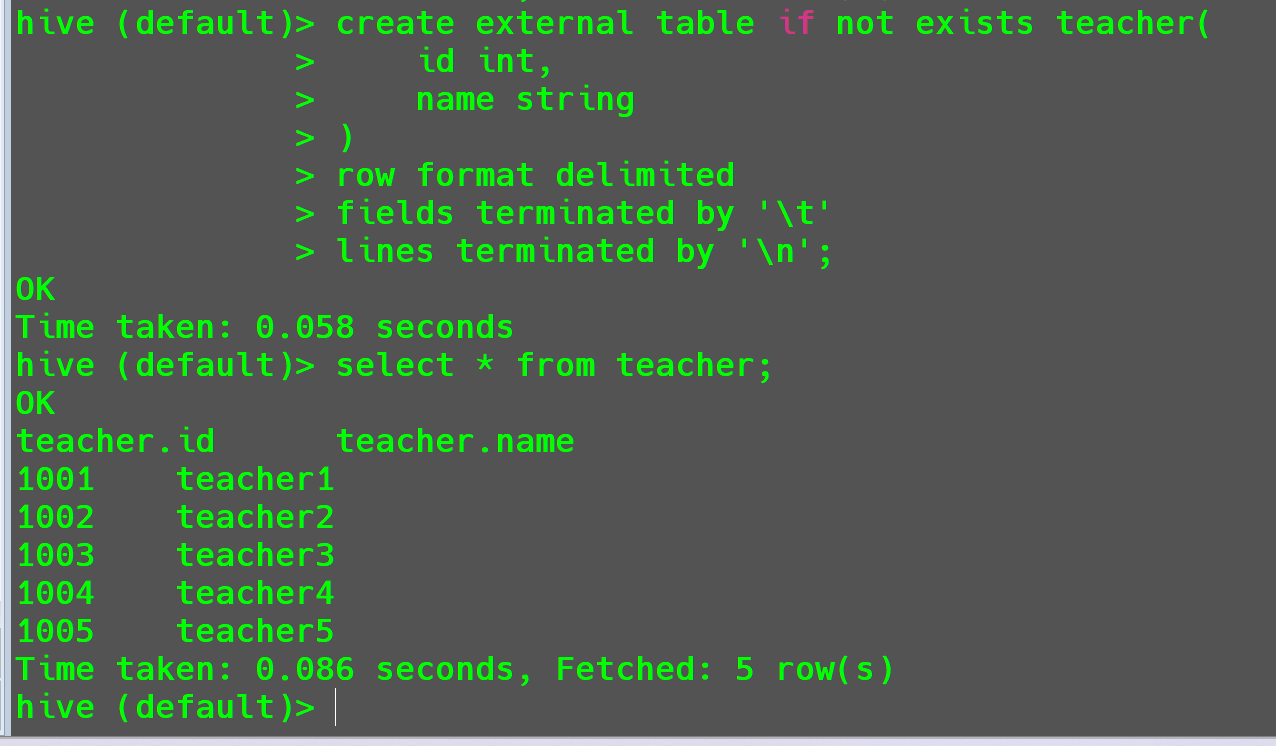
数据仍然存在。
这种机制其实就是
Hive在创建表时,发现需要创建表的文件夹在HDFS中已经存在了,此时就是直接将数据导入到表格中。依据这种机制,我们就有了一种可以直接在创建表时将数据导入到
Hive中的方法,直接使用参数LOCATION去指定数据存储在HDFS中的位置。例如,我们将
teacher.txt上传到HDFS的/school/teacher目录下(不存在则手动创建)。
然后使用以下命令在创建
teacher2表时就直接指定数据存储位置,将数据直接导入到Hive。
2
3
4
5
6
7
8
9
id int,
name string
)
row format delimited
fields terminated by '\t'
lines terminated by '\n'
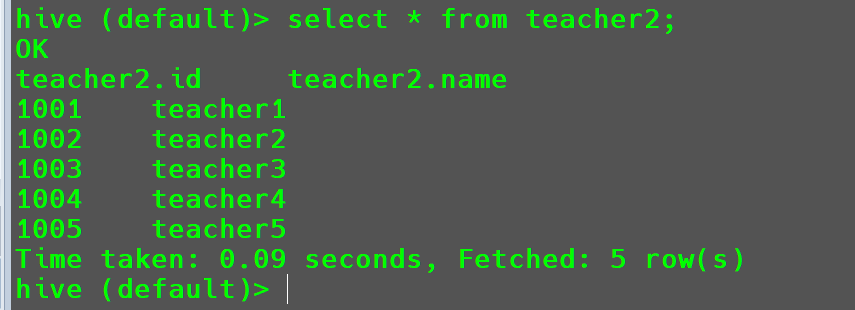
location '/school/teacher';然后查询
teacher2数据
此时数据就可以直接导入进来了。
管理表与外部表的相互转化
将teracher表修改为管理表。
1 | alter table teacher set tblproperties('EXTERNAL'='FALSE'); |
修改成功。
修改表
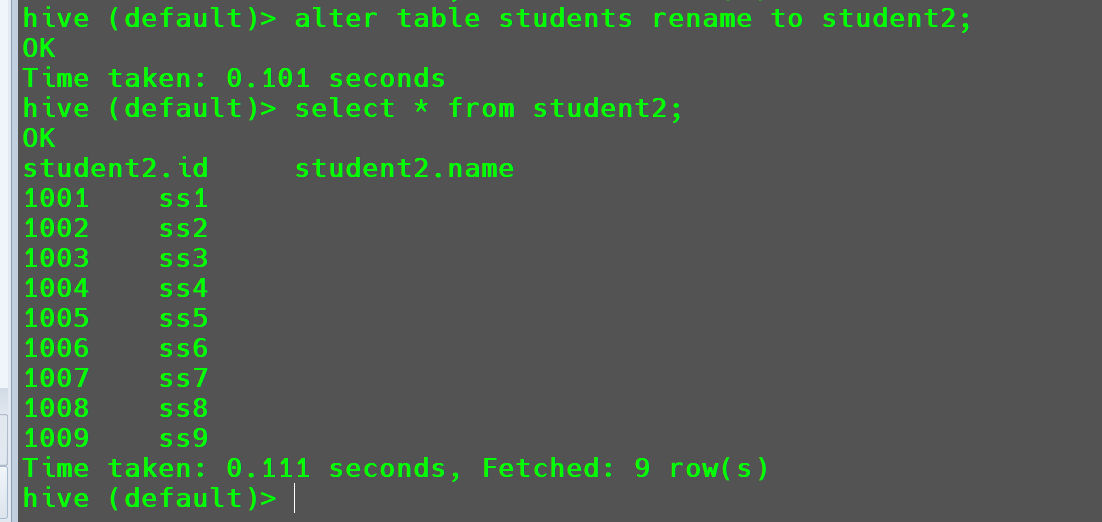
重命名表
将students表重命名为student2。
1 | alter table students rename to student2; |
增加、修改和替换列信息
修改列
将
student2中id列修改为stu_id数据类型为int。1
alter table student2 change id stu_id int;
查看
student2表的字段信息1
desc student2;
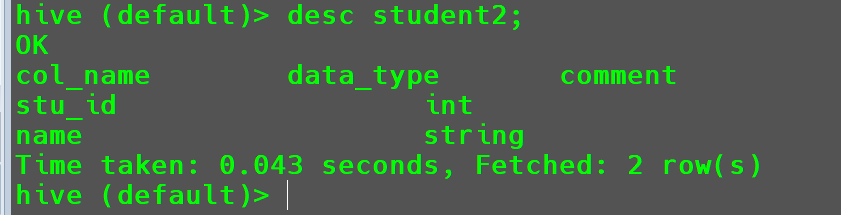
修改成功。
在修改字段的数据类型时,要注意也要遵循类型转换的基本原则。
例如:可以将
int转化为string,但是无法将string转化为int。1
alter table student2 change stu_id stu_id string;
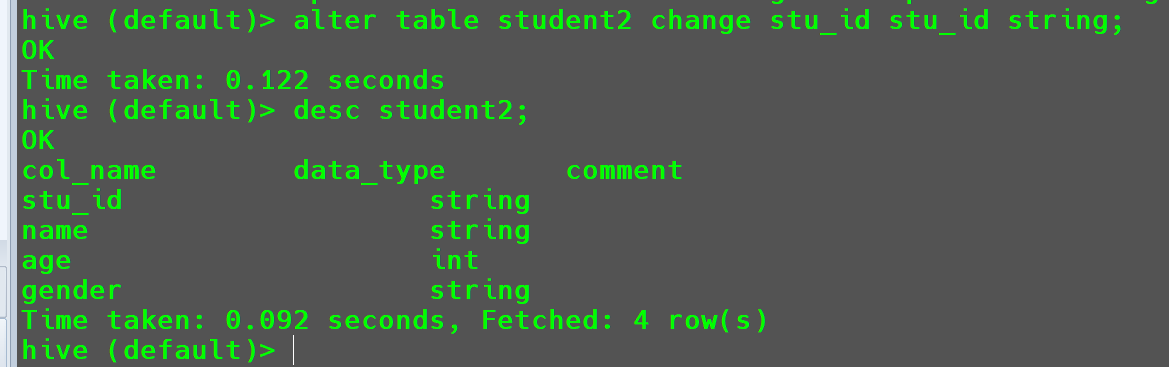
这样转换没有问题,但是要想再将
stu_id转换回int,这个时候就会报错。1
alter table student2 change stu_id stu_id int;

增加列
给
student2增加两列age int,gender string。1
alter table student2 add columns(age int, gender string);
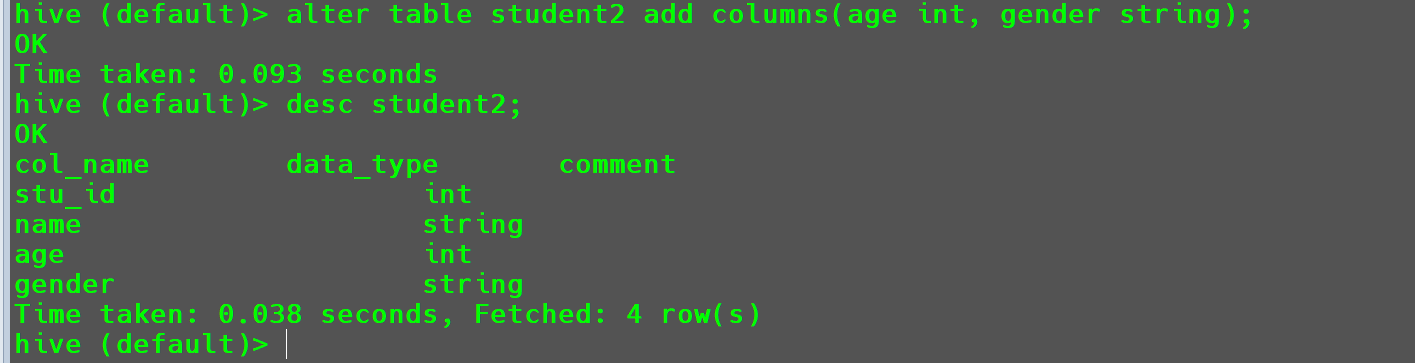
创建成功。
替换列
1
alter table student2 replace columns(id string, name string);
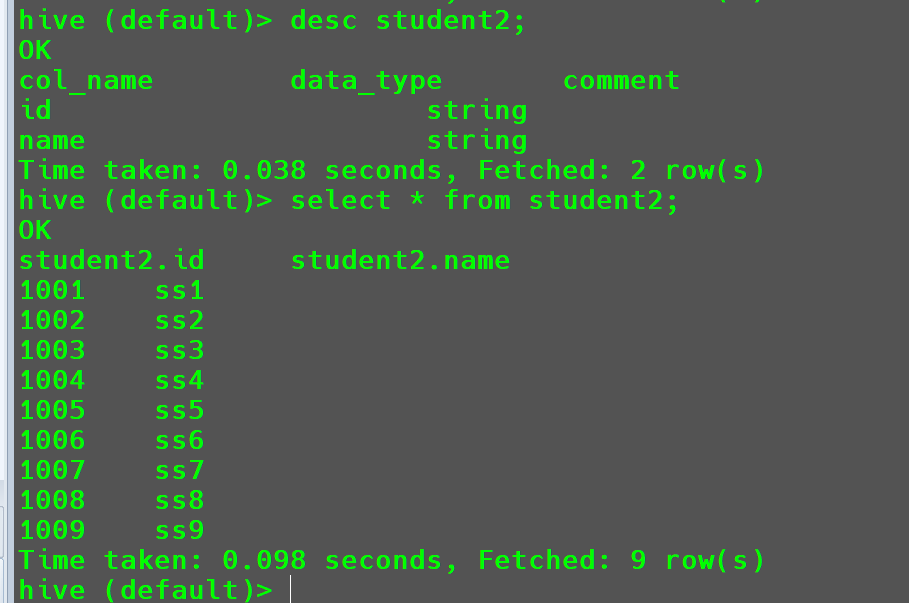
此时同样要遵循类型转换的基本原则。
使用以下语句就会报错。
1
alter table student2 replace columns(id int, name string);

但是我们可以将其转化为更大的数据类型
Double1
alter table student2 replace columns(id double, name string);
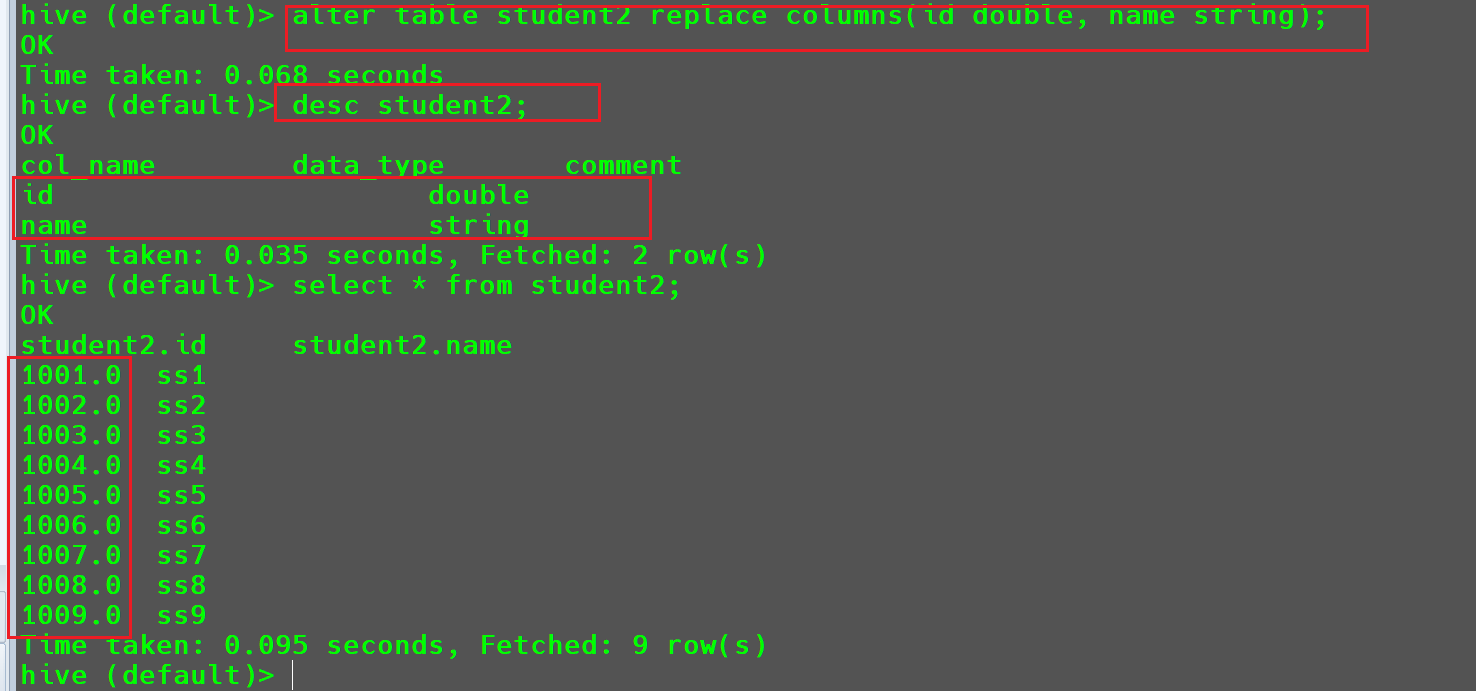
但是此时
id列就会被自动转化为double类型的浮点数。
删除表
删除表student4
1 | drop table student4; |
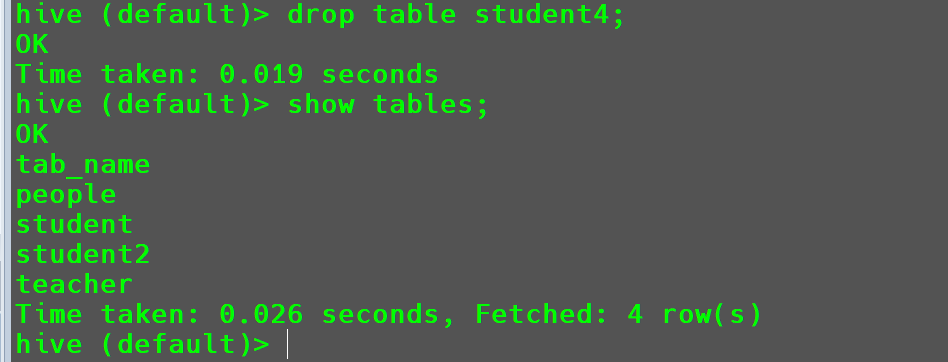
清空表
1 | truncate table teacher; |

注意:清空表会将
Hive的实际数据删除,所以只能作用在管理表下,外部表是没有权限去删除实际数据的。
DML数据操作
数据导入
向表中装载数据(load)
1 | load data [local] inpath '数据的path' [overwrite] into table table_name [partition (partcol1=val1,…)]; |
| 参数 | 参数意义 |
|---|---|
Load data |
加载数据 |
Local |
表示从本地加载数据到hive表,否则是从HDFS加载数据到Hive表 |
Inpath |
表是加载数据的路径 |
Overwrite |
表示覆盖表中已有数据,否则表示追加 |
Into table |
表示加载数据到哪张表中 |
Partition |
表示加载数据到指定分区 |
案例实操:
这个操作前面其实已经用过多次了,这里我们再演示一遍。
首先创建一个student3表
1 | -- 创建表 |
- 将本地文件中的数据加载到
student3表中。
1 | load data local inpath '/opt/module/hive-3.1.2/datas/students.txt' into table student3; |
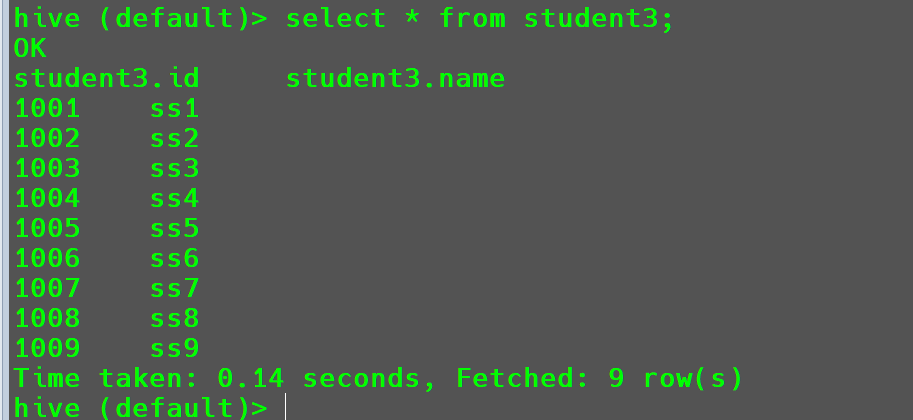
加载成功。
- 将
HDFS文件系统中的数据加载到student3表中。
首先将students.txt文件上传到HDFS的以下目录/school/student。
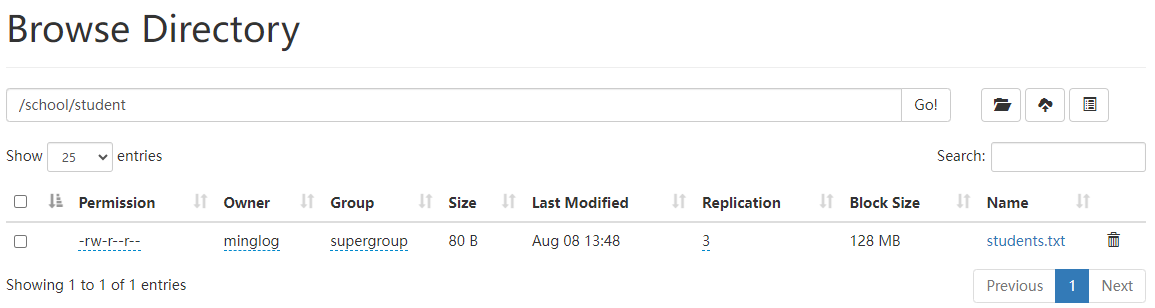
然后使用以下代码将其导入到student3中。
1 | load data inpath '/school/student/students.txt' into table student3; |
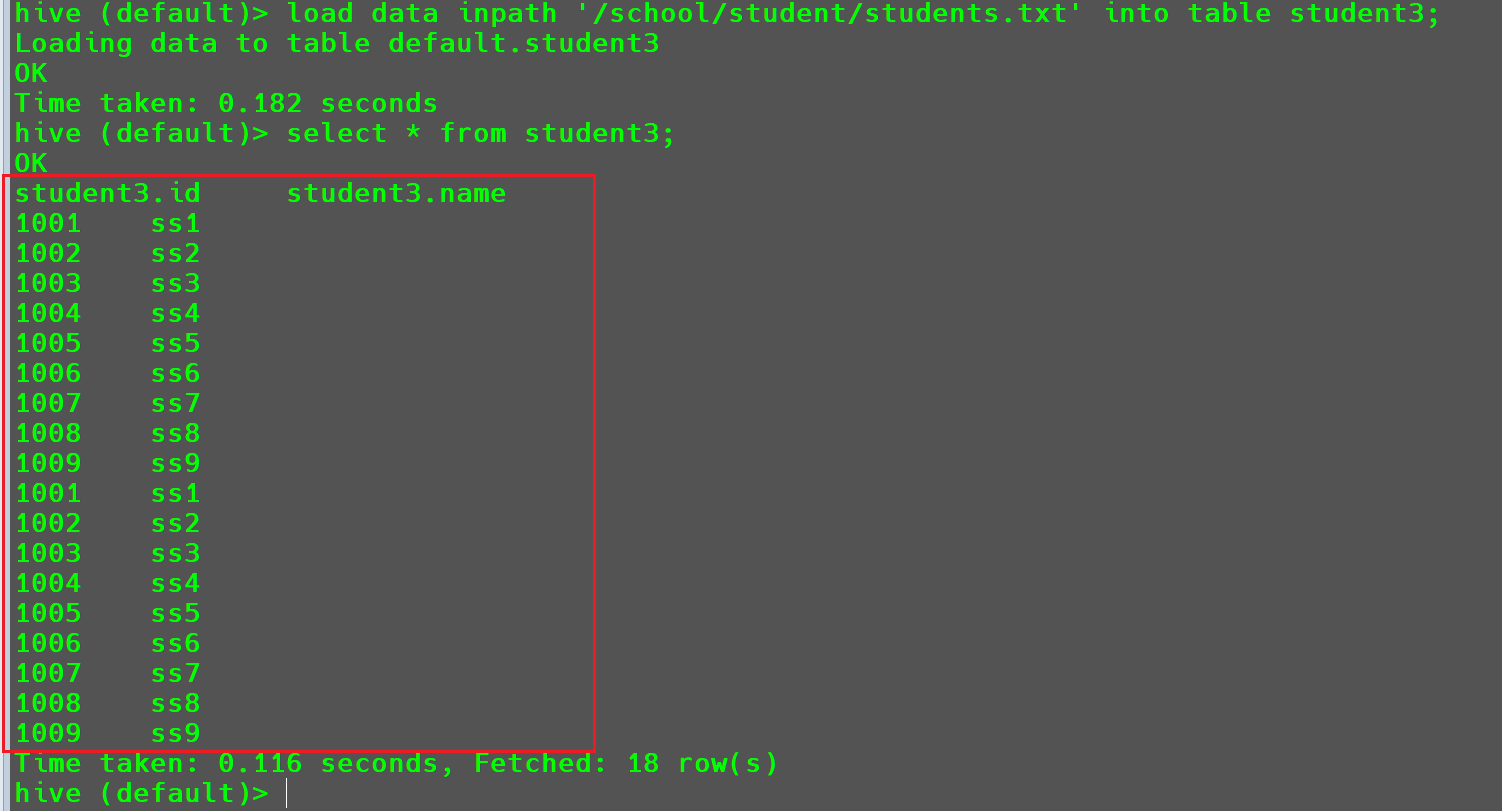
可以看到数据导入成功,这个时候可以看到数据又被导入到student3中一次。
使用此方法导入数据后,在
HDFS中的数据文件就会被删除。
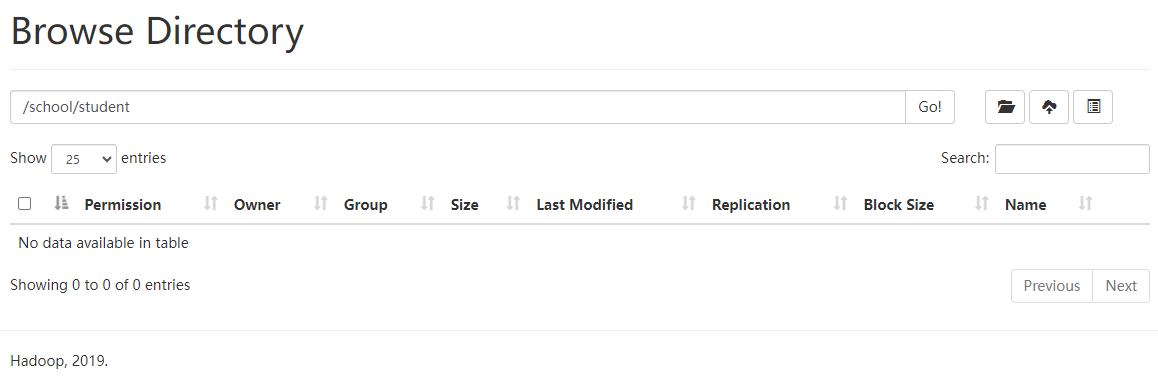
经过前面的操作,我们将students.txt文件导入到student3两次,其中数据出现了重复,想要重复数据在导入的过程中自动覆盖,可以在导入数据的过程中加入overwrite参数。
1 | load data local inpath '/opt/module/hive-3.1.2/datas/students.txt' overwrite into table student3; |
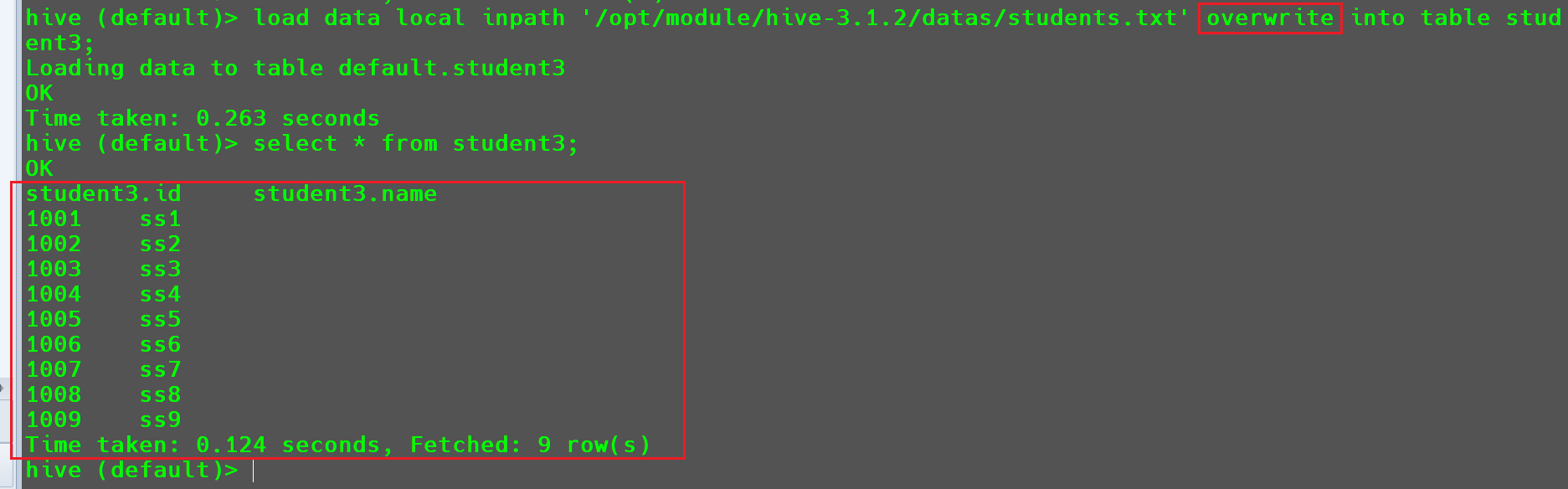
经过覆盖写入之后,在数据表中就不存在重复数据了。
细心的同学可以发现,在这里不重复数据不仅仅是导入中的数据不重复导入,而且会对整个数据表做校验,将重复数据只保留一次。
向表中插入数据(Insert)
依然是首先创建一个表student4。
1 | -- 创建表 |
最基础的使用方式,向表中插入多条数据。
1 | insert into student4 values(1, 'zhangsan'), (2, 'lisi'); |
此时会使用MR将数据插入到student4中。
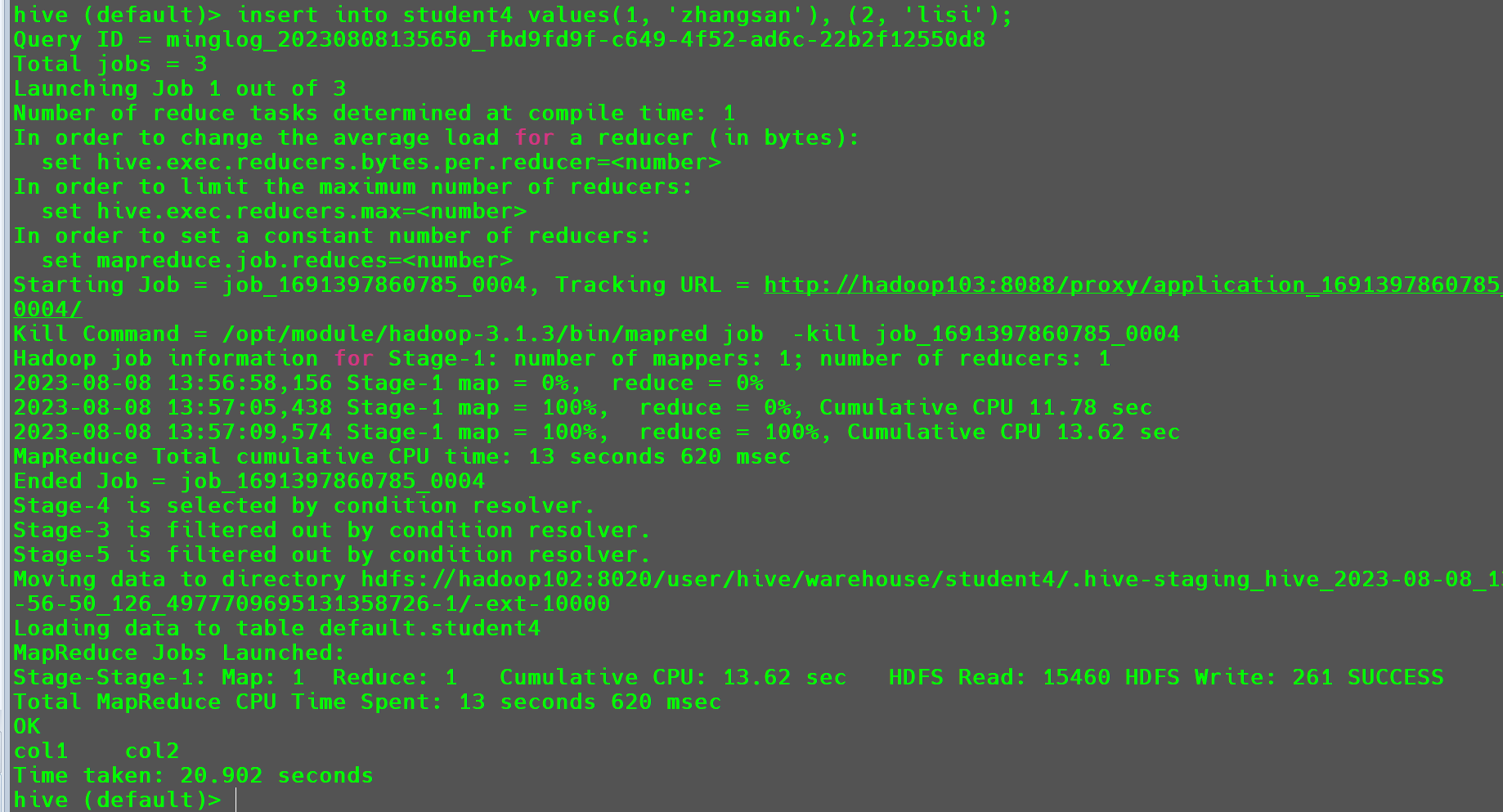
插入结果。
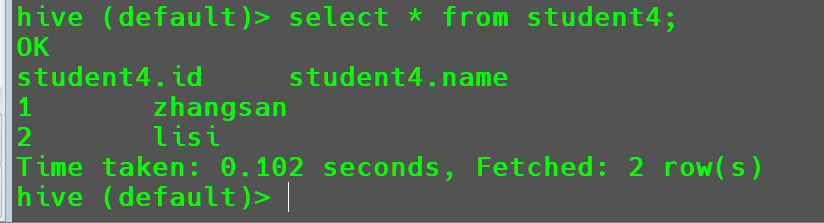
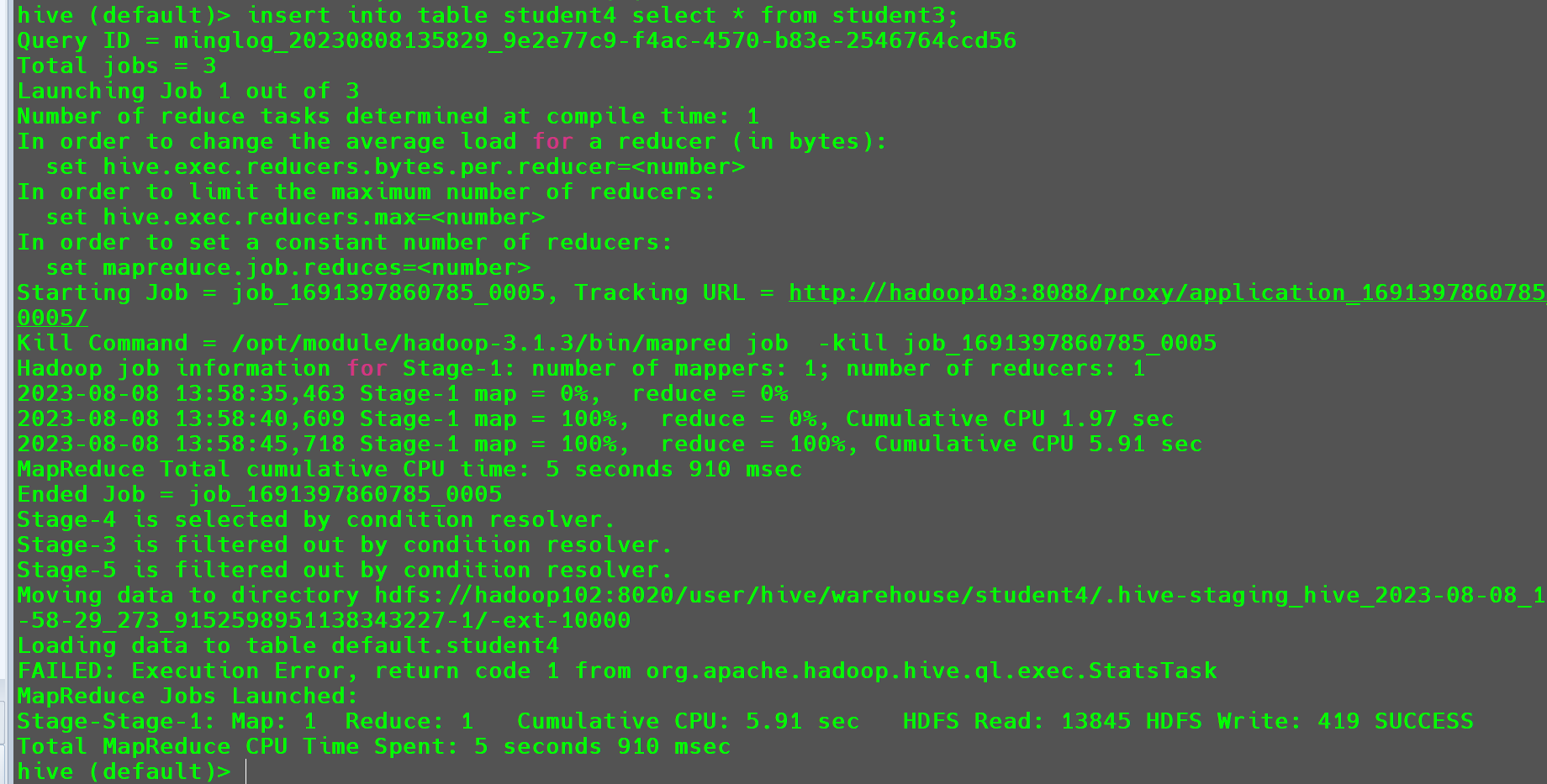
- 将查询的结果插入到表中。
1 | insert into table student4 select * from student3; |
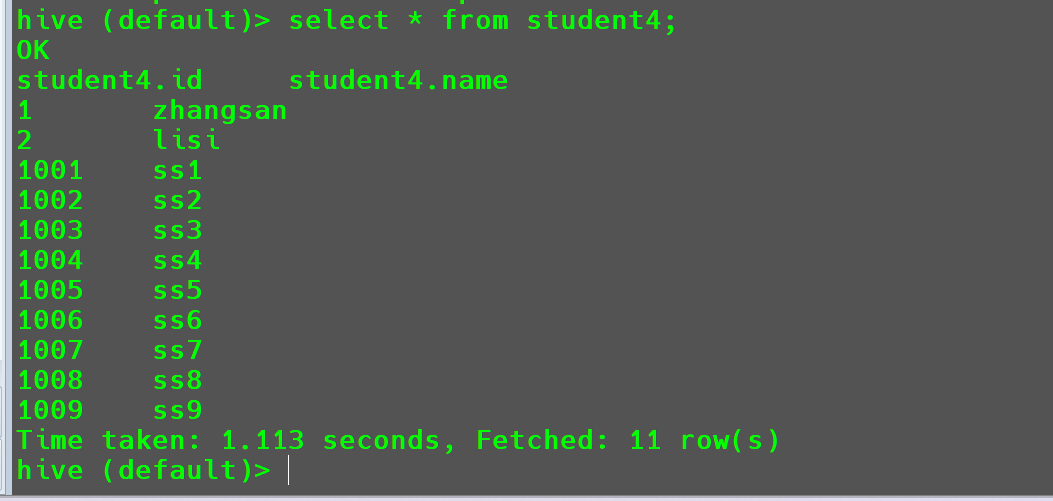
此时也会走MR将从student3中查询出来的数据插入到student4。
查询插入结果。
如果想要在插入的过程中不出现重复数据,需要将
into参数,修改为overwrite参数。
将查询结果创建为一个新的表
这个在本文章的3.2.1.1节中已经做过演示,在此不再演示其使用方式。
在此主要是给大家做一个对比,和前面inert之间有什么区别。
这里是将查询出来的结果创建为一个新的表;而前面讲的insert方法是将查询的结果插入到一个现有的表格中。
创建表时通过Location指定加载数据路径
这里在本文章中的3.2.1.2节中给大家也演示过,在此不再赘述。
注意:
hive创建表时,默认时将表的名字作为默认HDFS上表对应的存储路径的名字,但是,如果你通过localtion指定存储路径,就不会修改路径名字为表名了。如上边的表名为student5和其在HDFS上的存储路径student。
数据导出
将查询结果导出到本地
1 | insert overwrite local directory '/opt/module/hive-3.1.2/datas/export/student' select * from student4; |
此时在目录/opt/module/hive-3.1.2/datas/export/student下即可看到导出的文件内容。
将结果导出到HDFS上
1 | insert overwrite directory '/export/student' select * from student4; |
导出成功
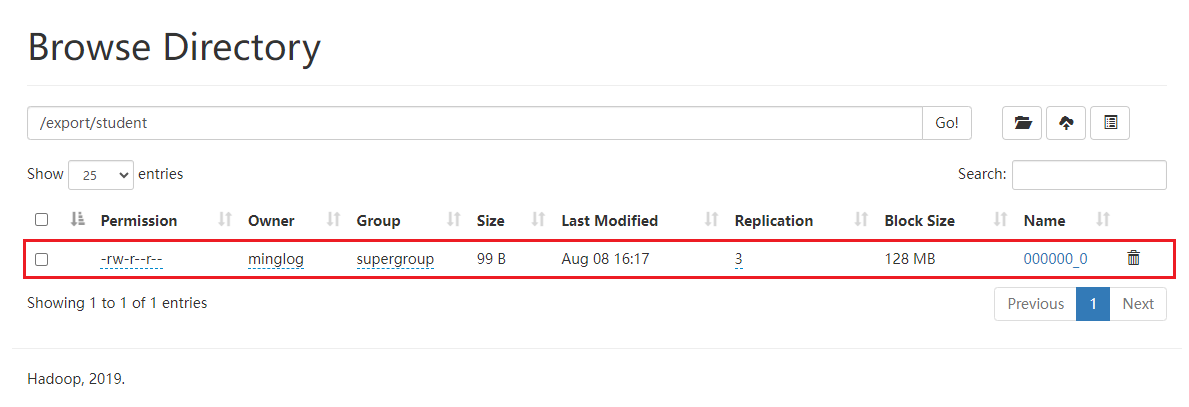
将查询的结果格式化导出到本地
查看导出的数据文件内容
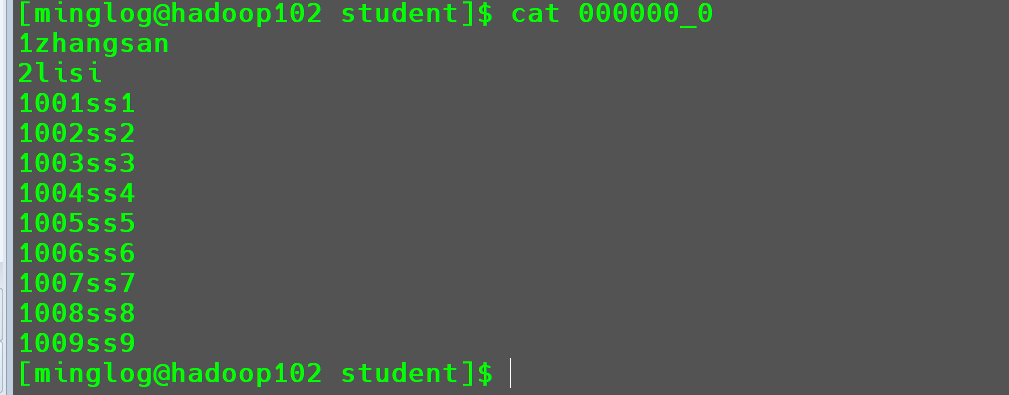
可以看到此时导出的结果,不同的字段之间没有分隔符。
导出时指定分隔符。
1 | insert overwrite local directory '/opt/module/hive-3.1.2/datas/export/student' |
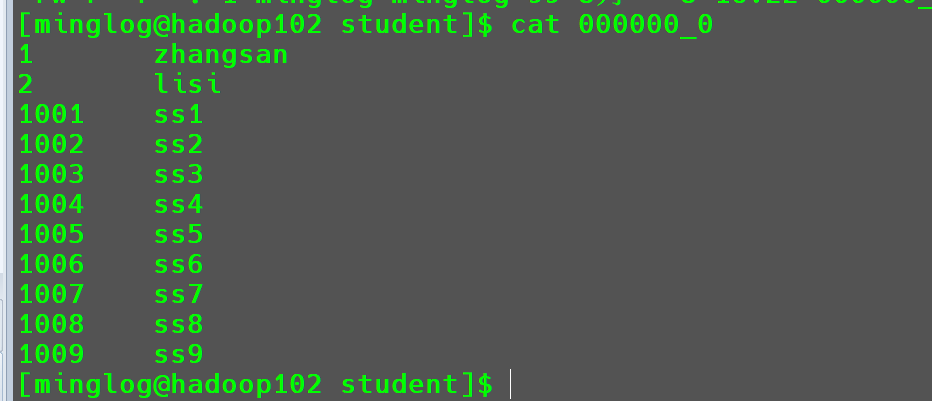
此时可以看到,字段之间的数据就使用\t作为了分隔符。
注意:
insert导出时,hive会自动创建导出目录,但是由于是overwrite,所以导出路径一定要写准确,否则存在误删数据的可能。
数据迁移
export和import命令主要用于两个Hadoop平台集群之间Hive表迁移。(包含元数据源+真实数据)
Export导出到HDFS上
1 | export table student4 to '/export/student4'; |

在HDFS中就出现了对应的文件,在做数据迁移时将该文件夹拷贝到其他集群的HDFS即可。
此时文件夹中就包含了对应的数据集。
Import数据到指定Hive表中
将其他集群中导出的Hive表文件导入到,现有的Hive集群。
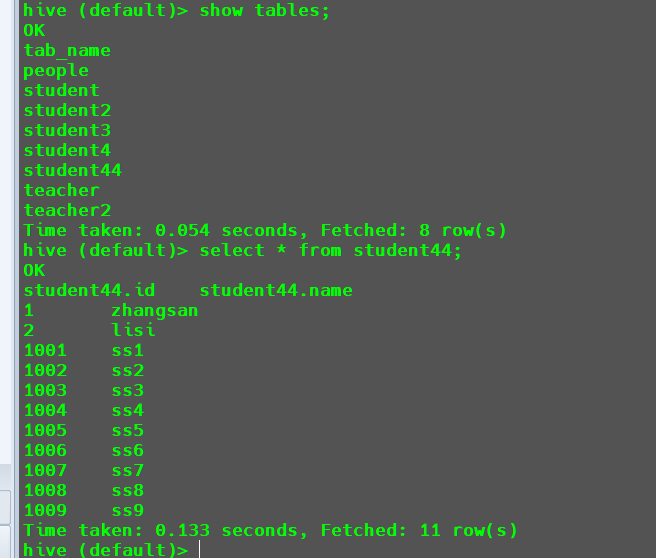
1 | import table student44 from '/export/student4'; |
注意:必须是其他
Hive集群使用export导出的Hive文件夹。