硬件资源准备
首先需要准备计算机的硬件资源,可以是本地服务器,也可以是云服务器。
显存要求:12GB
由于我本地计算机没有相应的GPU资源可以直接调用,故选择云服务器资源。我选择的云服务器厂商是腾讯云,云服务器租赁教程如下:
首先,登录腾讯云,然后在首页选择产品。
然后在产品页面中找到
计算->高性能应用服务。
接下来就要开始构建自己的服务器,新用户(如果不是新用户可跳过此步)可以有
1元使用8小时的优惠活动,可以自己去购买,购买后可以用于抵扣消耗的服务器时长。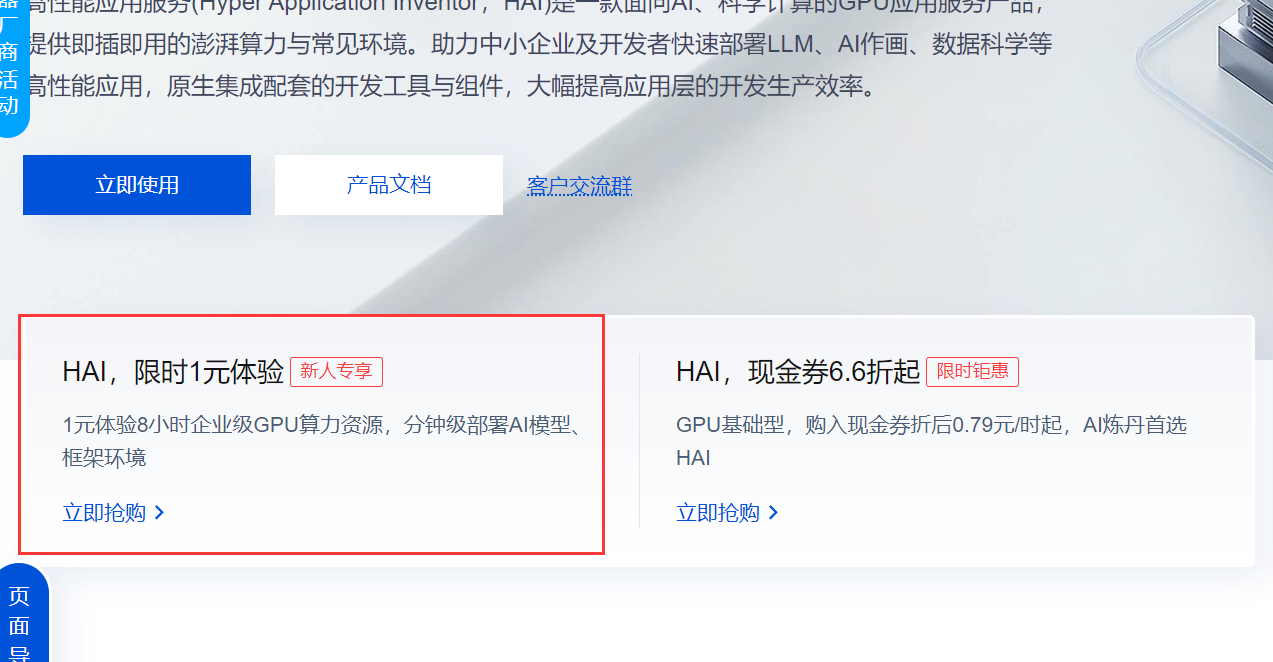
接下来点击立即使用进入到创建实例界面。

资源选择不得低于下图所示的计算资源,然后点击
立即购买即可。特别要注意的是硬盘大小不得低于100GB。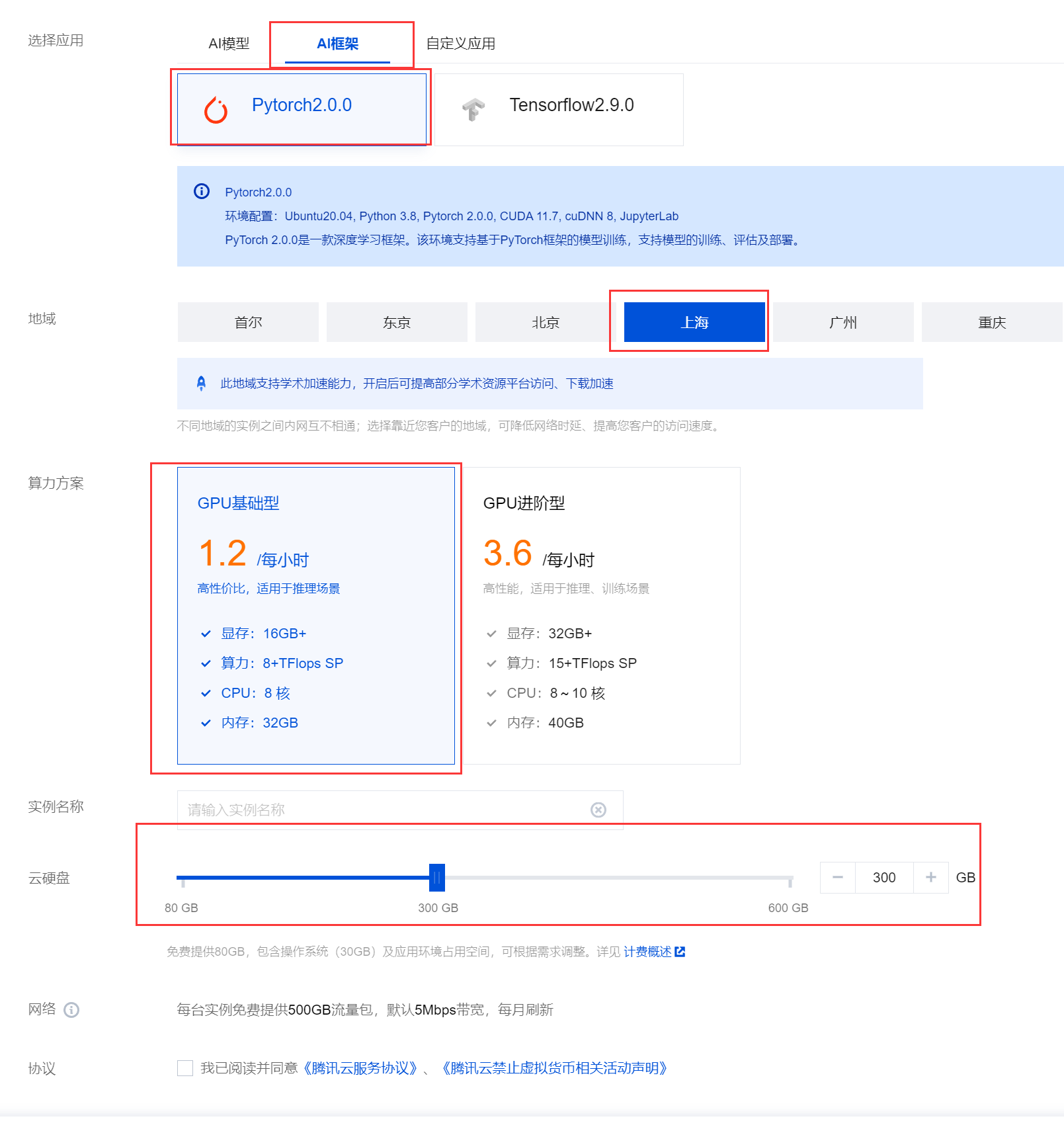
购买完成后在高性能应用服务中就会出现刚才创建的实例。
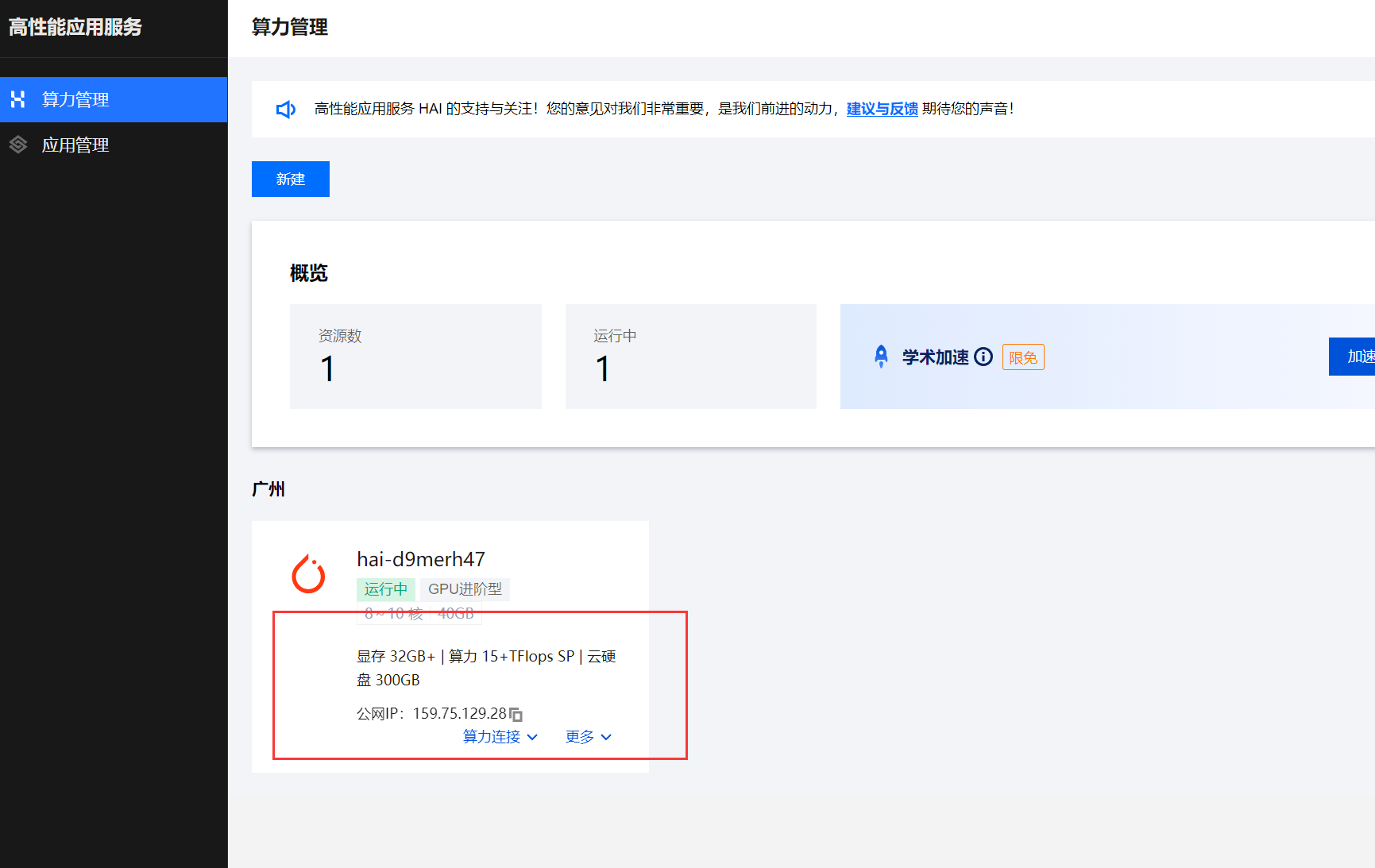
等待实例加载3~5分钟后,点击
算力连接->JupyterLab
运行ChatGLM3-6B模型
首先进入终端
更新实例相关依赖。
1 | apt update |
下载git-lfs
1 | apt install git-lfs |
在家目录下创建models文件夹
1 | mkdir models |
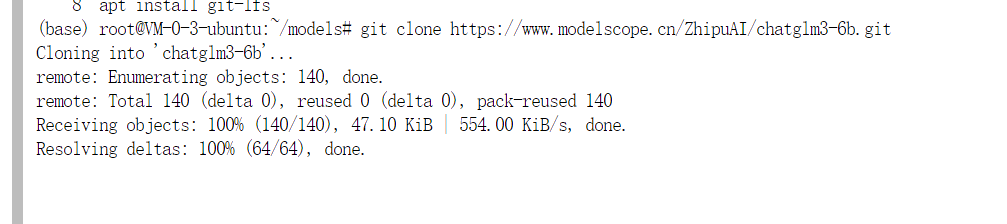
执行以下命令下载ChatGLM3-6B模型权重文件。
1 | git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git |
接下来开启一个新的终端,下载m3e向量模型库。
1 | git clone https://www.modelscope.cn/xrunda/m3e-base.git |

这两步骤消耗的时间可能比较长,一般是在60分钟左右。
接下来,回到家目录,并创建codes文件夹,然后在codes文件夹下克隆ChatGLM3项目。
1 | cd ~ && mkdir codes && cd codes |
然后,进入到ChatGLM3文件夹,下载项目依赖
1 | cd ChatGLM3 |
在streamlit中开启ChatGLM3模型
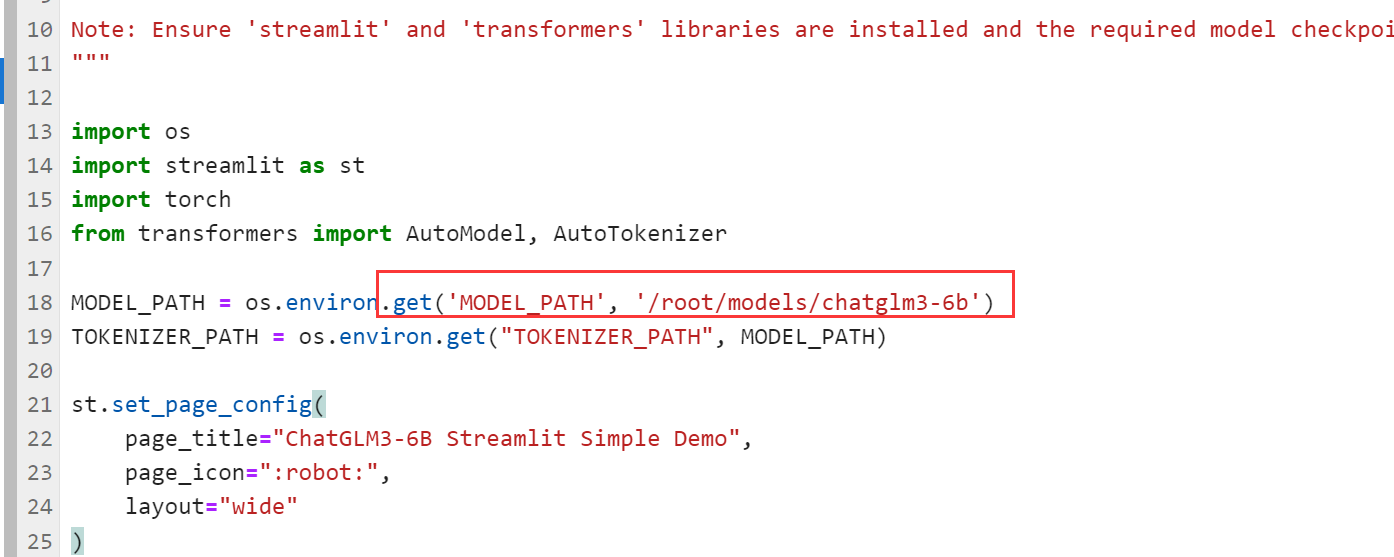
修改项目文件中的相关路径
打开basic_demo/web_demo_streamlit.py
接下来执行以下命令开启streamlit网页端。
1 | streamlit run web_demo_streamlit.py |

点击网址链接即可访问WEB界面,此时要注意的是默认的情况下8501端口是不开放的,需要自己在实例的安全组中设置开放8501端口。
点击实例名称,进入详情页。
点击端口配置
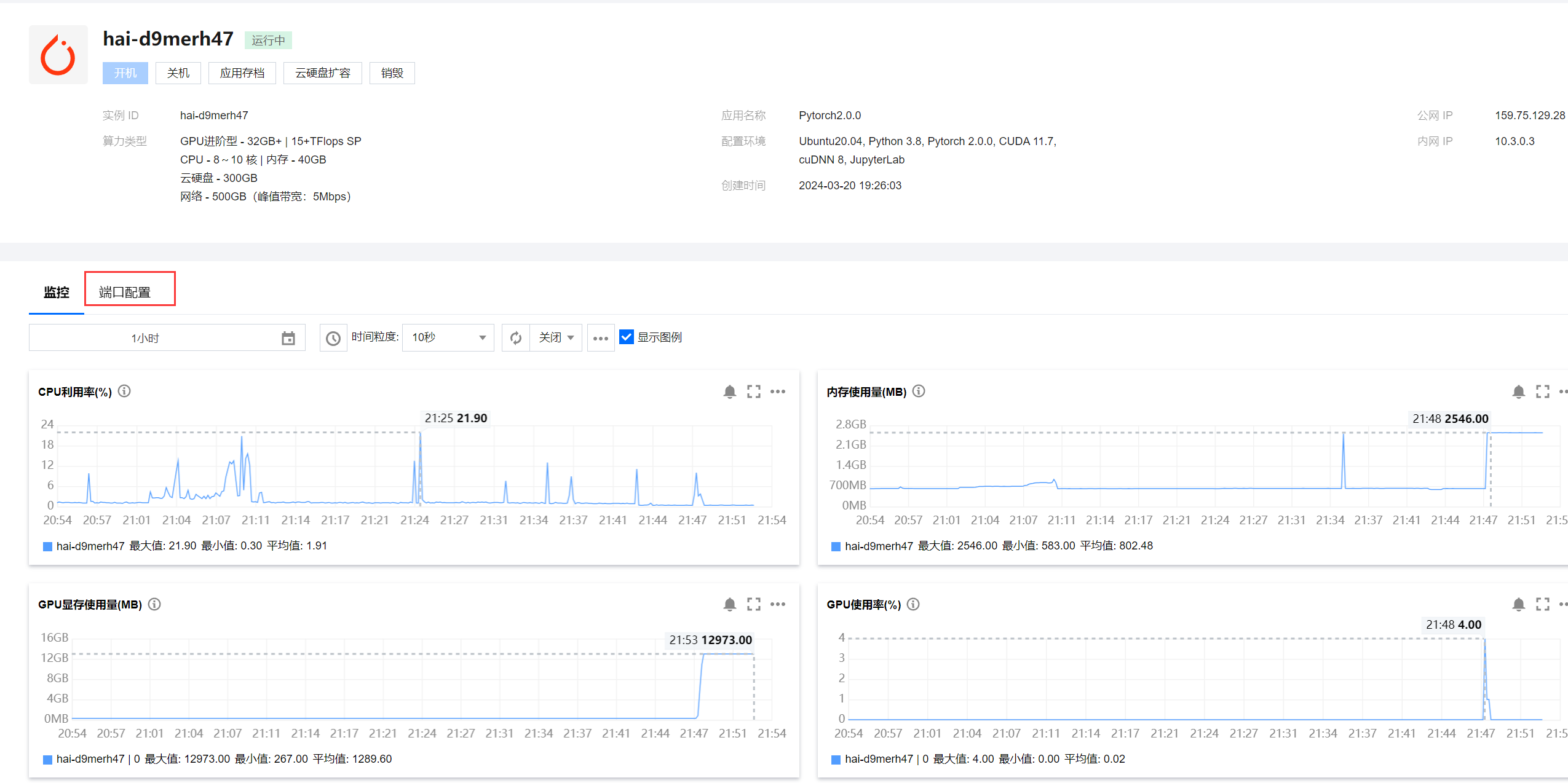
点击添加规则,添加如下所示内容。

也可以直接将协议端口修改为ALL表示开放所有端口。
接下来再次进入到网页端即可开始加载模型,模型加载完毕后显示聊天页面,如下所示。

感受完毕,有正常的结果返回即可中断程序。
开启ChatGLM3 API
修改openai_api_demo路径下的api_server.py文件中相关路径

将模型的加载设备修改为cuda

接下来就需要开启对应的API
1 | python /root/codes/ChatGLM3/openai_api_demo/api_server.py |

返回上图所示结果说明开启API成功。
fastgpt部署
这一步可以在其他服务器或者局域网服务器中进行配置,这是一个网页服务,可以调用前面我们部署的ChatGLM3,并进行本地知识库适配。
安装Docker
1 | # 安装 Docker |
开启docker
1 | systemctl enable --now docker |
安装docker-compose
1 | curl -L https://github.com/docker/compose/releases/download/v2.25.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose |
这一步消耗的时间可能大约30分钟左右。
赋予docker-compose执行权限。
1 | chmod +x /usr/local/bin/docker-compose |
验证是否安装成功。
1 | docker -v |

docker-compose也可选择离线部署,在 https://github.com/docker/compose/releases 中下载离线包,然后复制到对应文件夹下修改名称为docker-compose。
部署one-api
1 | docker run --name one-api -d --restart always -p 3080:3000 -e TZ=Asia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api |

检查容器是否运行成功
1 | docker ps -a |

然后在机器的IP地址加上3080端口号下即可看到网页内容。
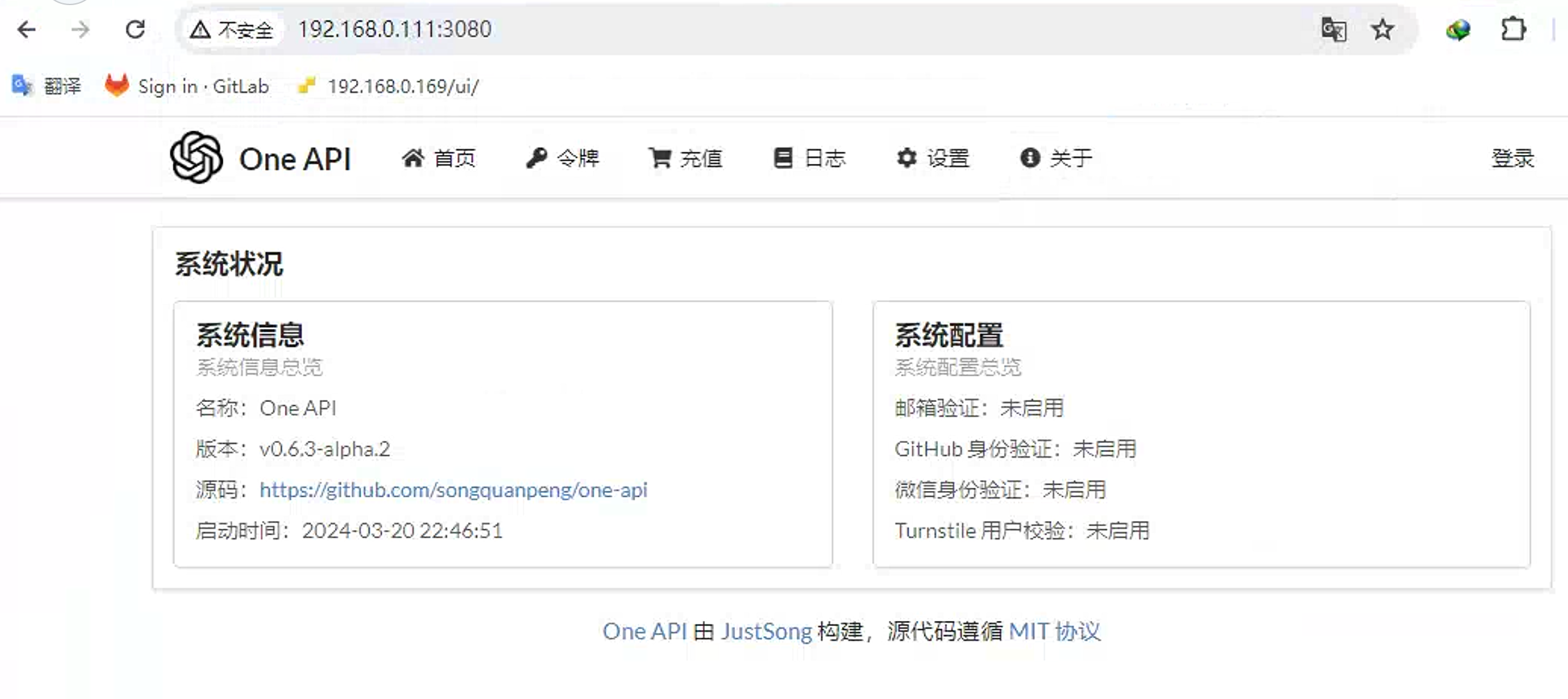
直接点击右上角的登录按钮进行登录。
初始用户名为:root
密码为:123456
登录成功后会提示修改密码和绑定相关社交账号,这里也可以选择先不修改。
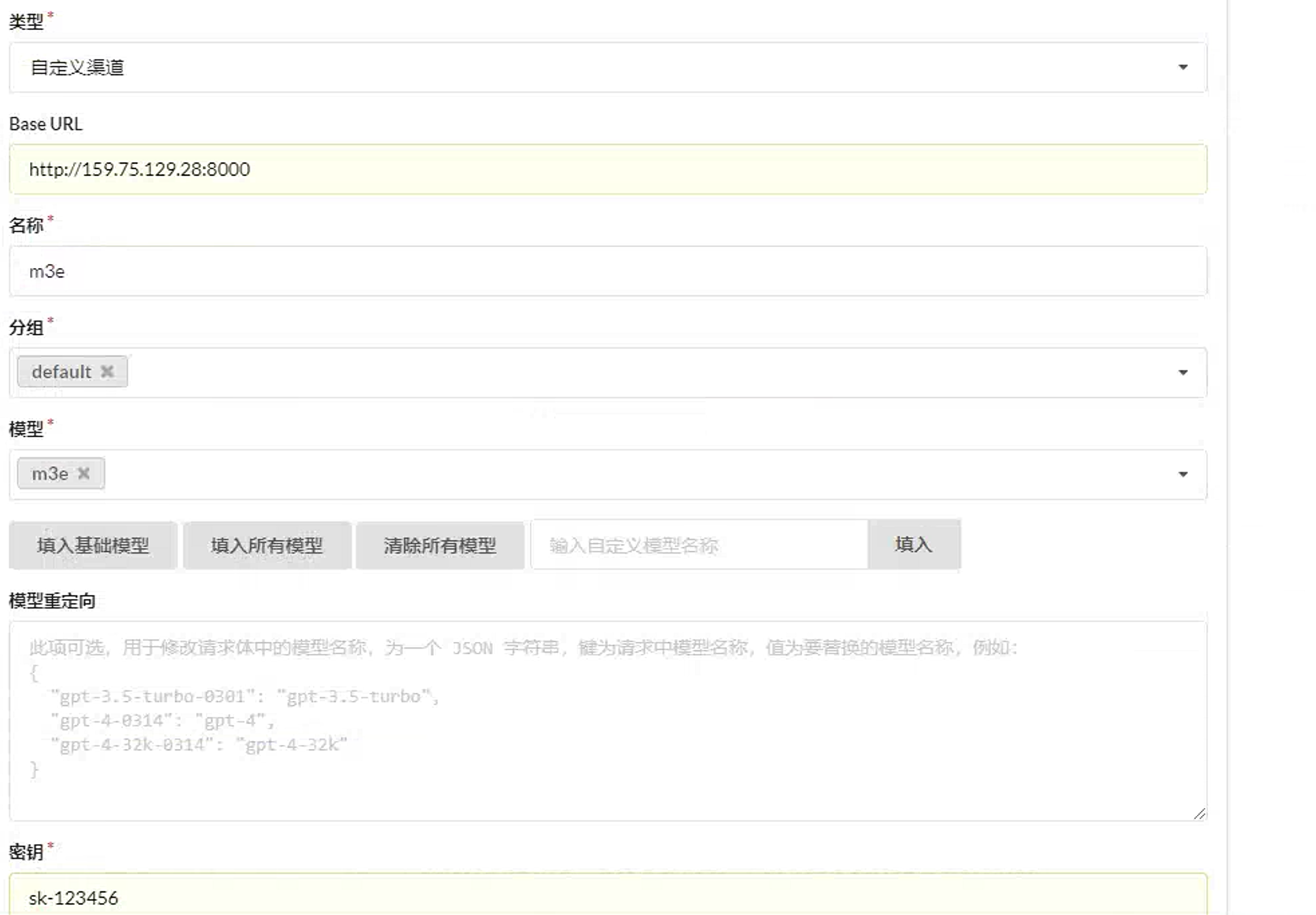
接下来在one-api中添加ChatGLM3的渠道。
点击添加新的渠道

填写以下内容,注意BaseURL中应该填写前面部署的ChatGLM3机器的IP地址。

继续在one-api中添加m3e向量的渠道
创建完成后可以测试渠道是否正常
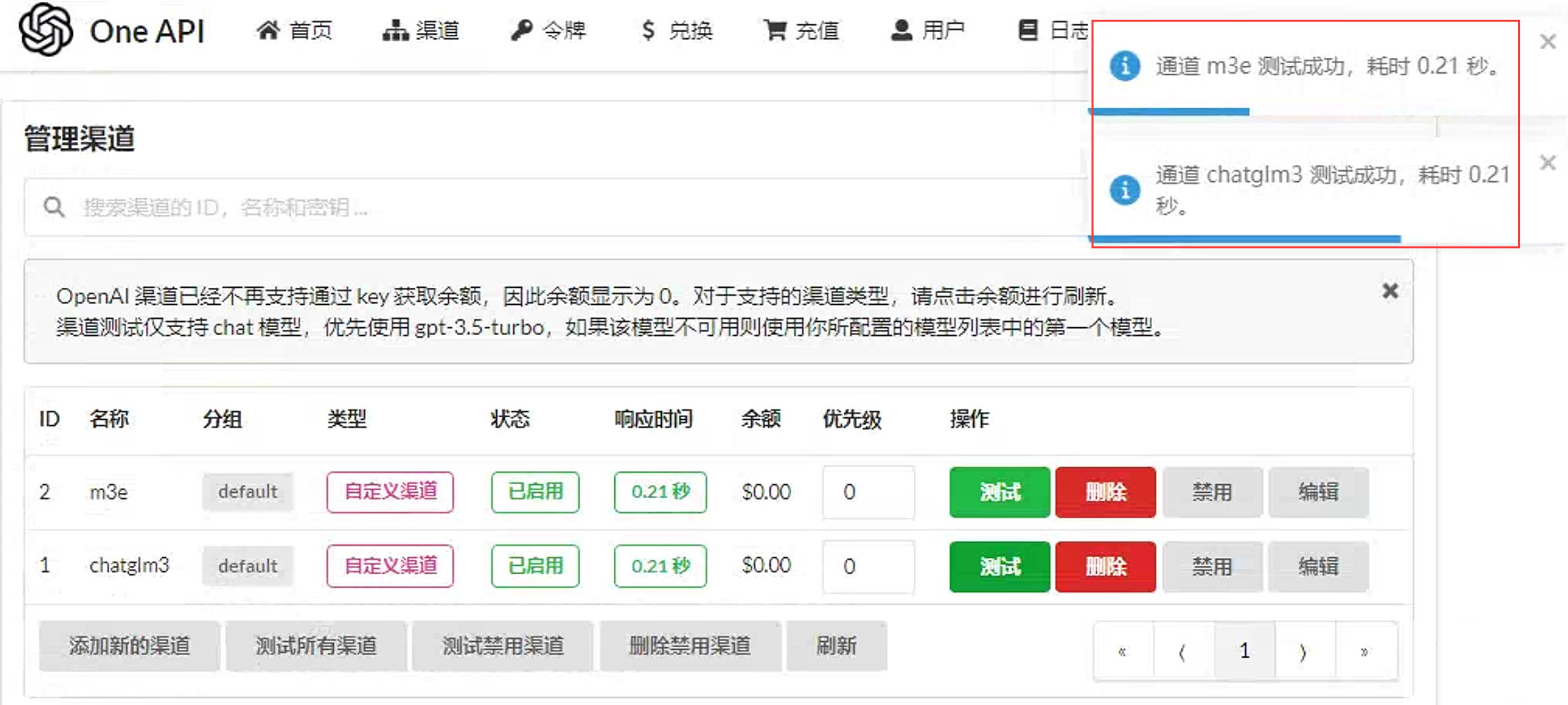
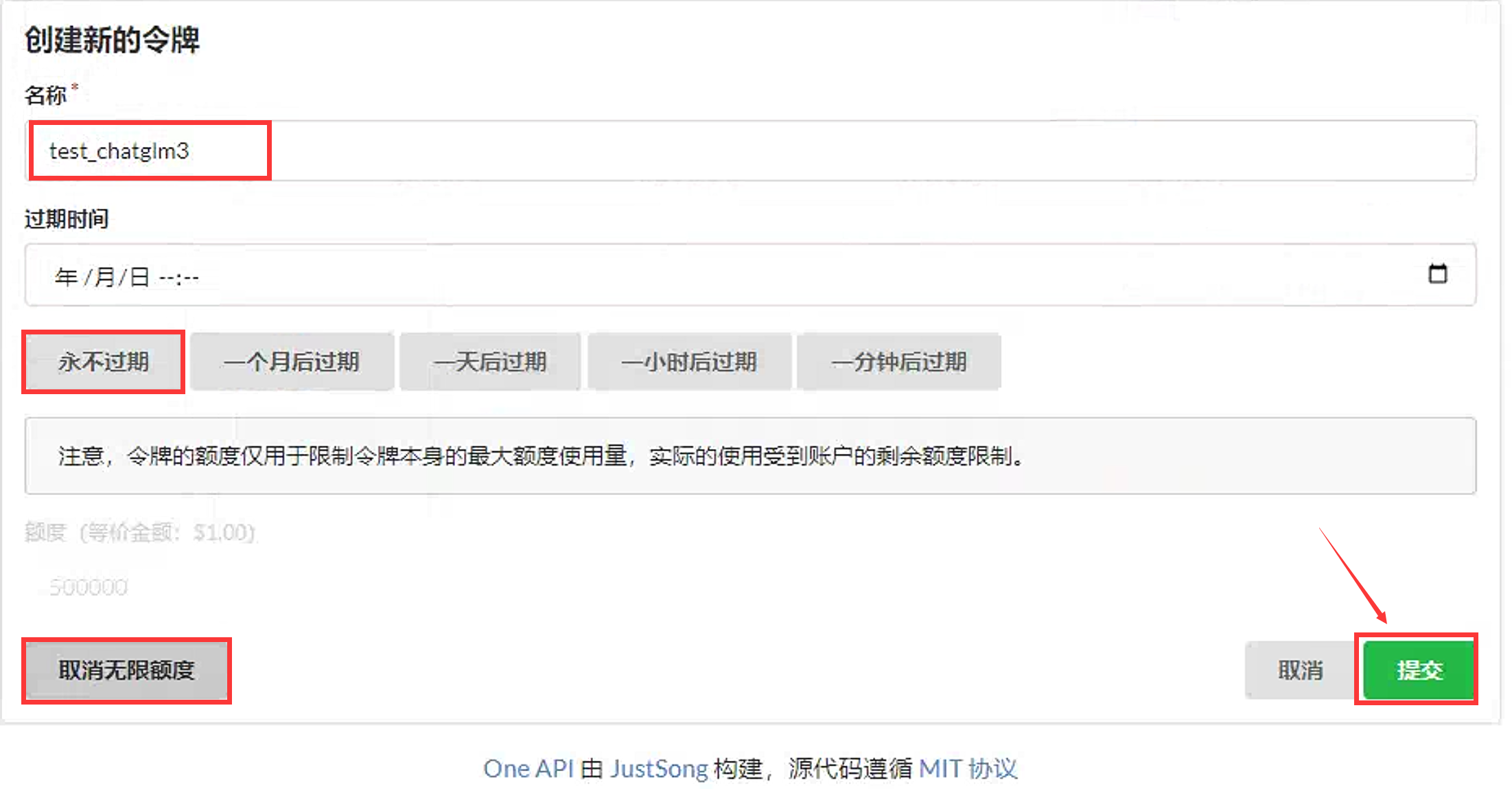
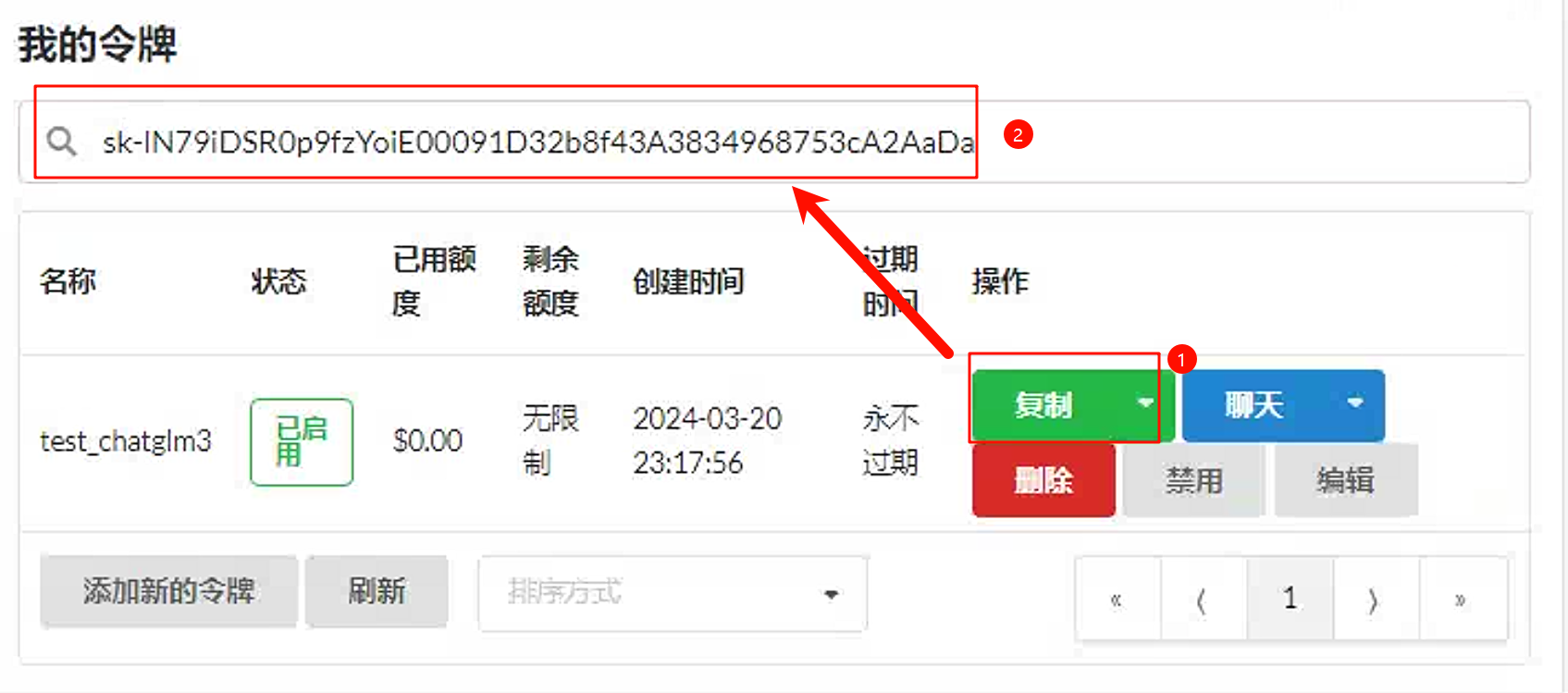
接下来在one-api中添加一个令牌。

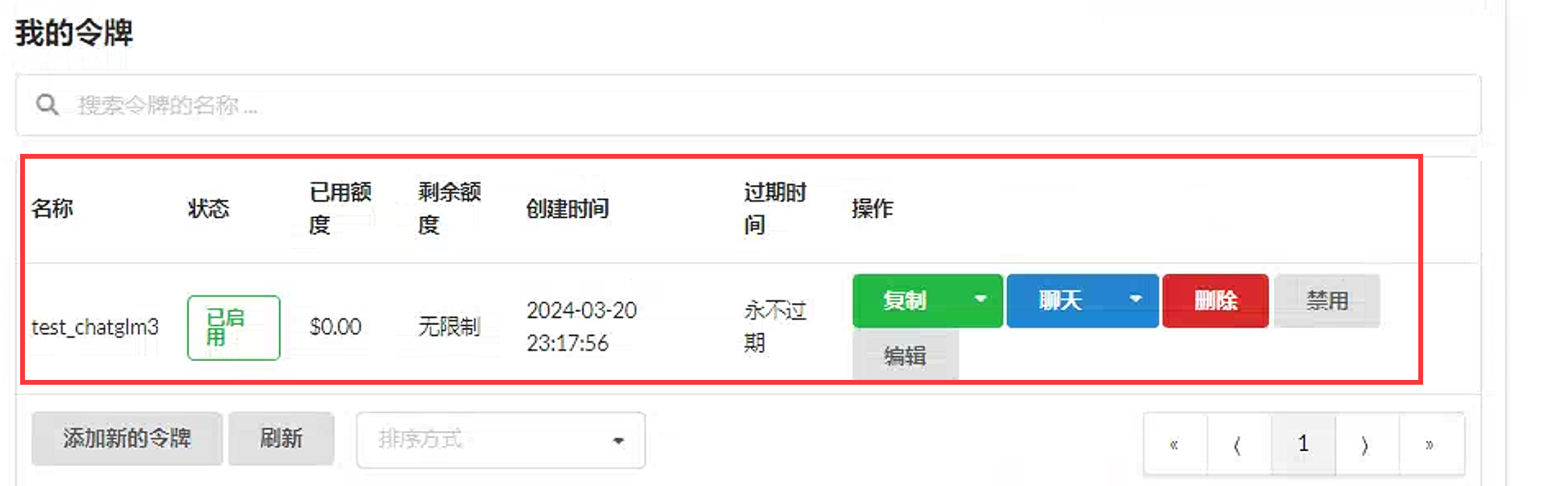
点回令牌页面发现创建成功。
部署fastgpt
在家目录创建fastgpt文件夹,拉取docker-compose.yml和config.json
1 | cd ~ && mkdir fastgpt && cd fastgpt |
下载容器
1 | docker-compose pull |

修改配置文件docker-compose.yml中的中转地址和API_KEY
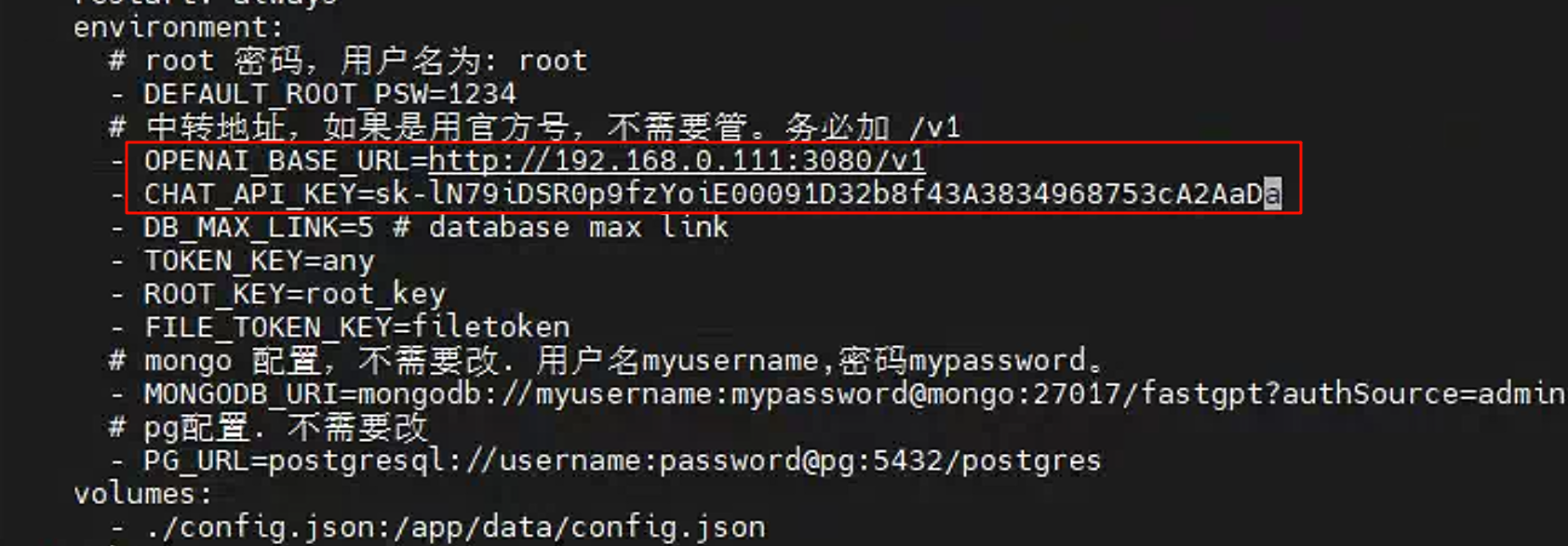
其中中转地址为
one-api项目地址
API_KEY的值需要在one-api中定义的令牌中去复制。
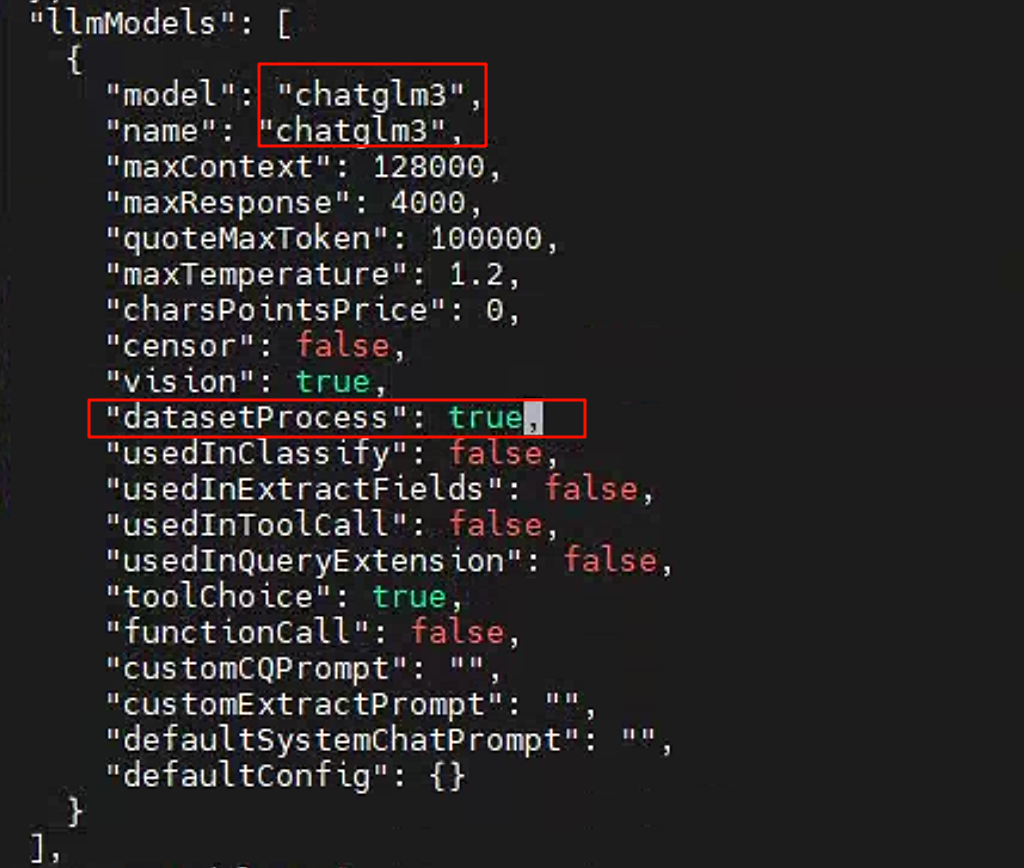
修改配置文件config.json
将llModels中的内容删除到只剩一个,并安装下图所示进行修改。
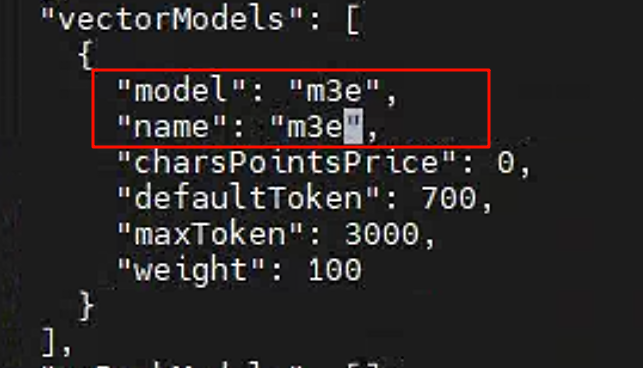
将向量模型名称修改为m3e
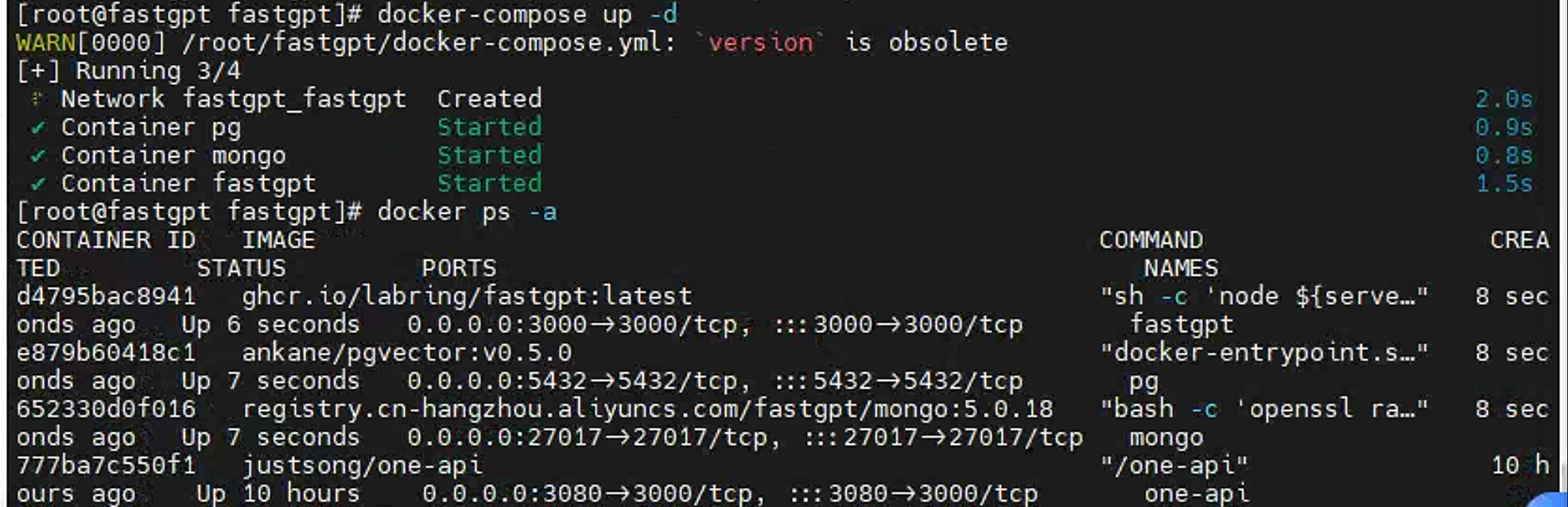
接下来使用docker-compose开启容器
1 | docker-compose up -d |
初始化Mongo副本集
1 | # 进入容器 |
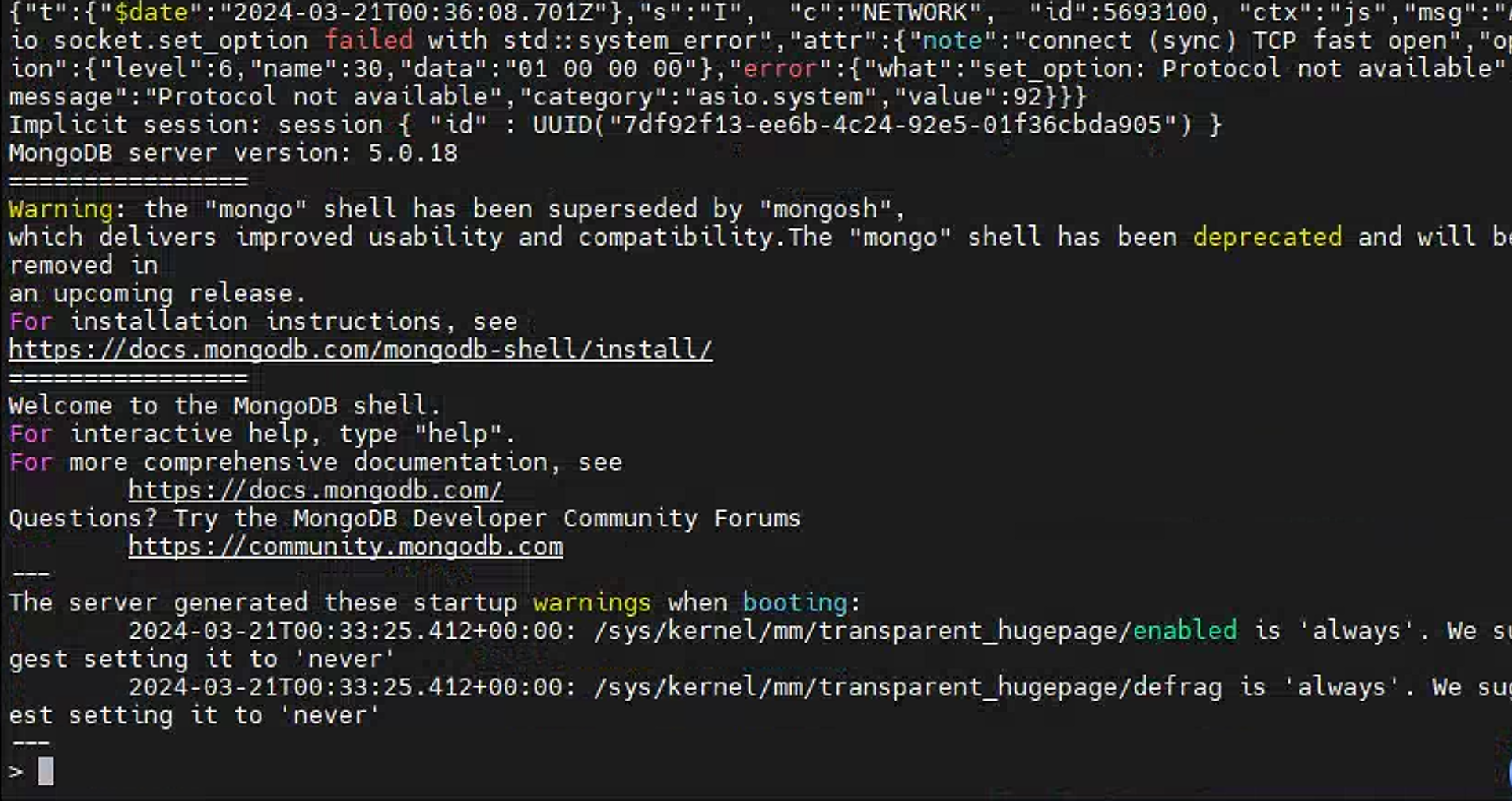
初始化数据框
1 | rs.initiate({ |
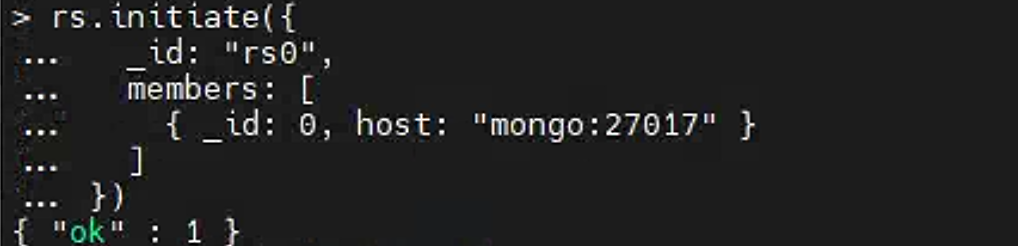
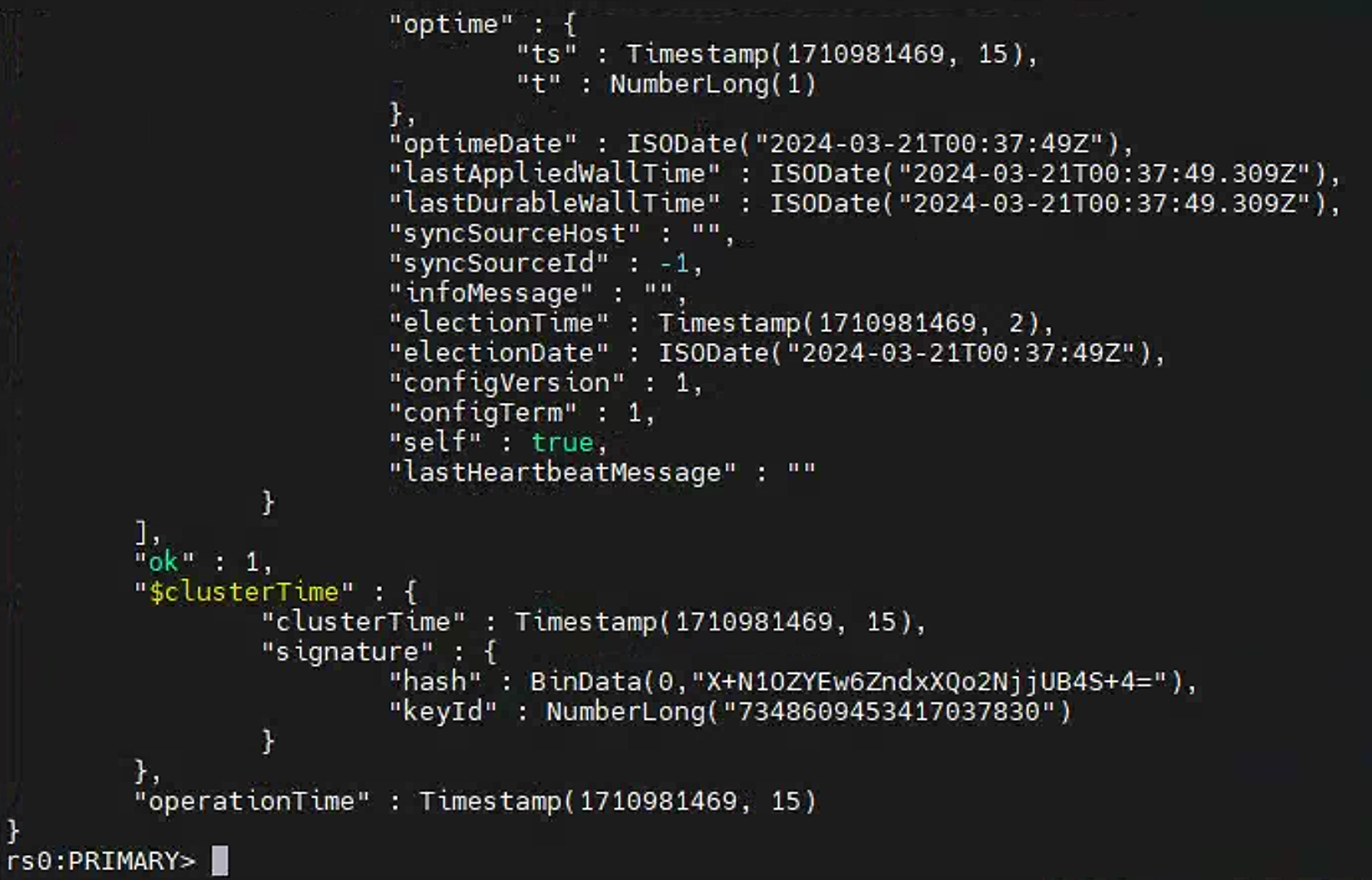
检查初始化状态
1 | # 检查状态。如果提示 rs0 状态,则代表运行成功 |
一切准备就绪,进入到FastGPT,http://192.168.0.111:3000 (这里需要将IP地址修改为自己设备的IP地址)
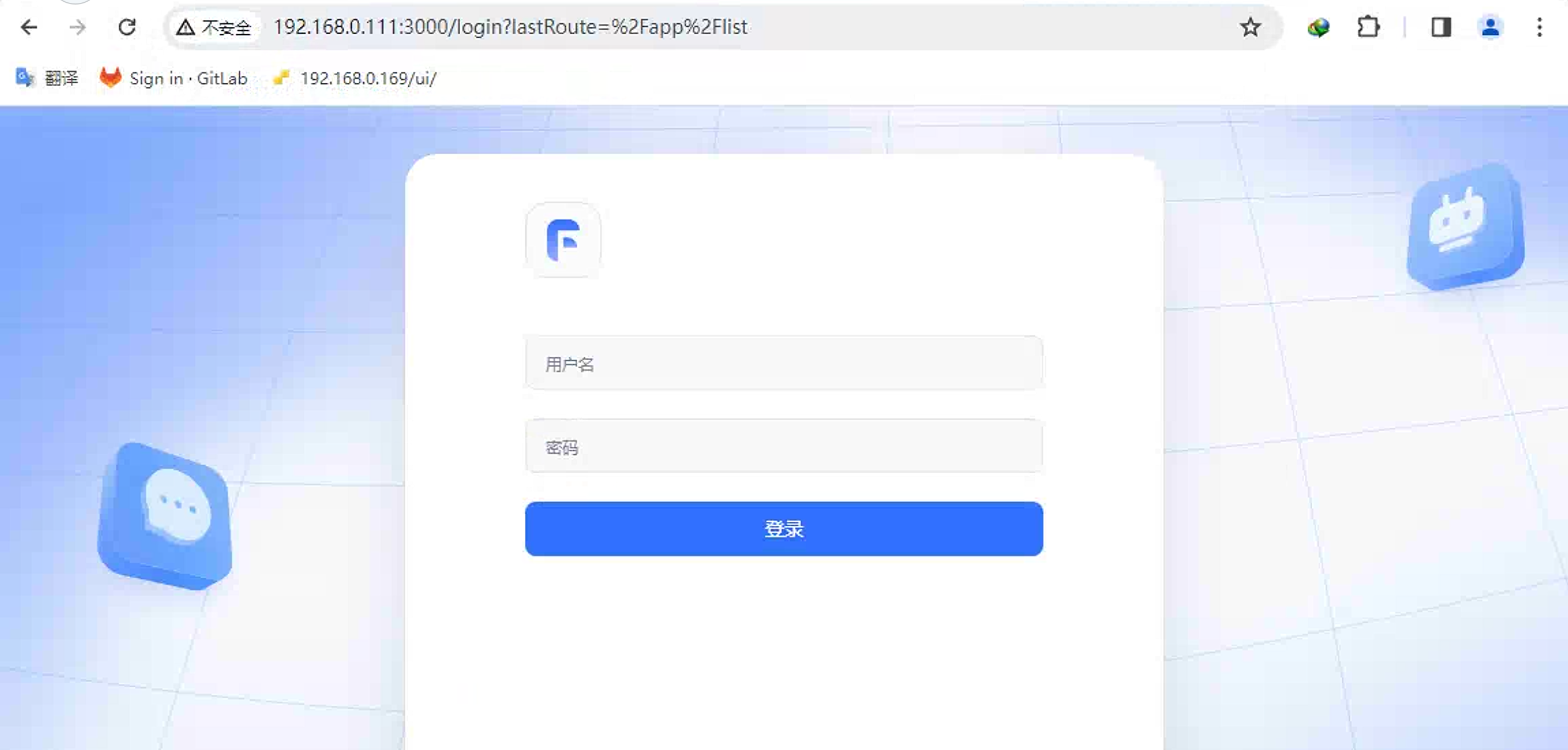
输入账号密码进行登录。
首次登录账号为:
root密码为:
1234

登录成功,至此FastGPT创建成功。
大模型的使用
聊天机器人创建
在FastGPT应用栏目点击新建
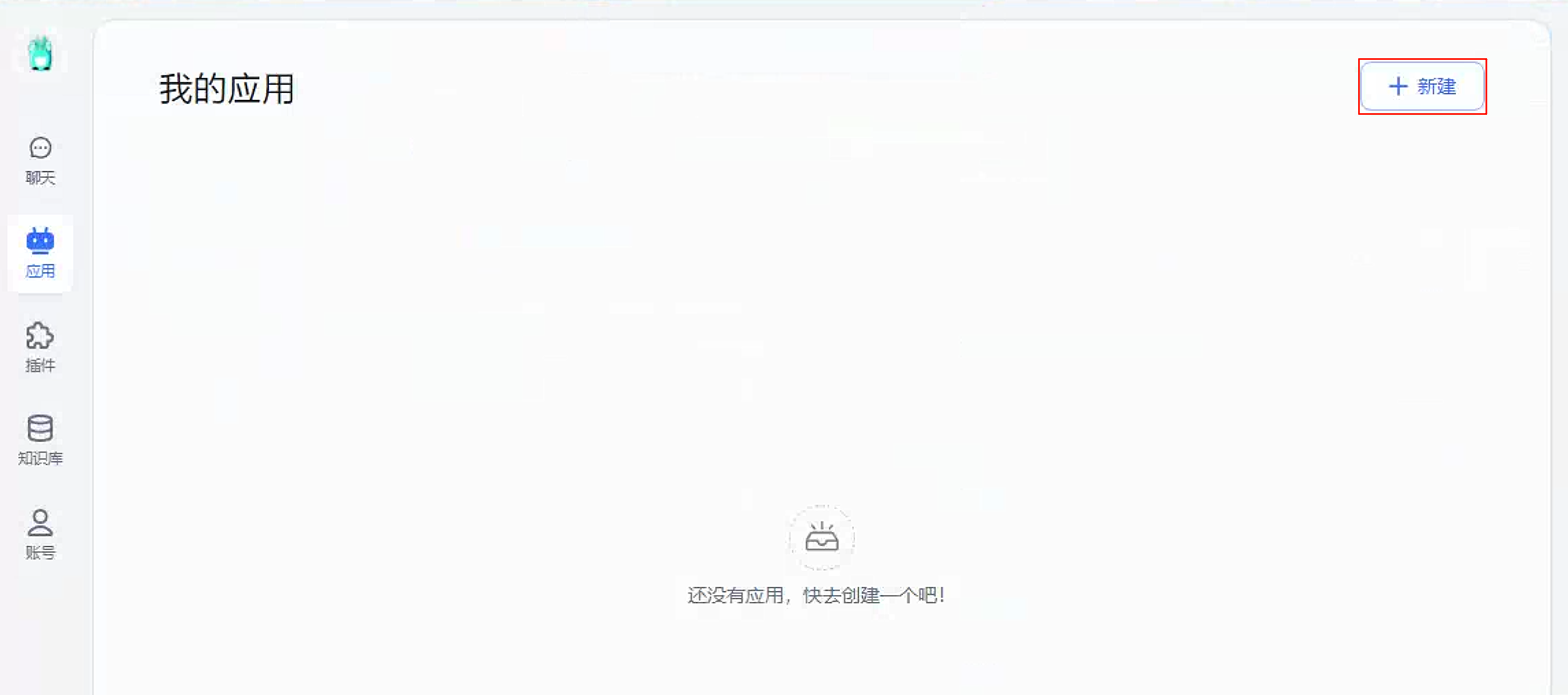
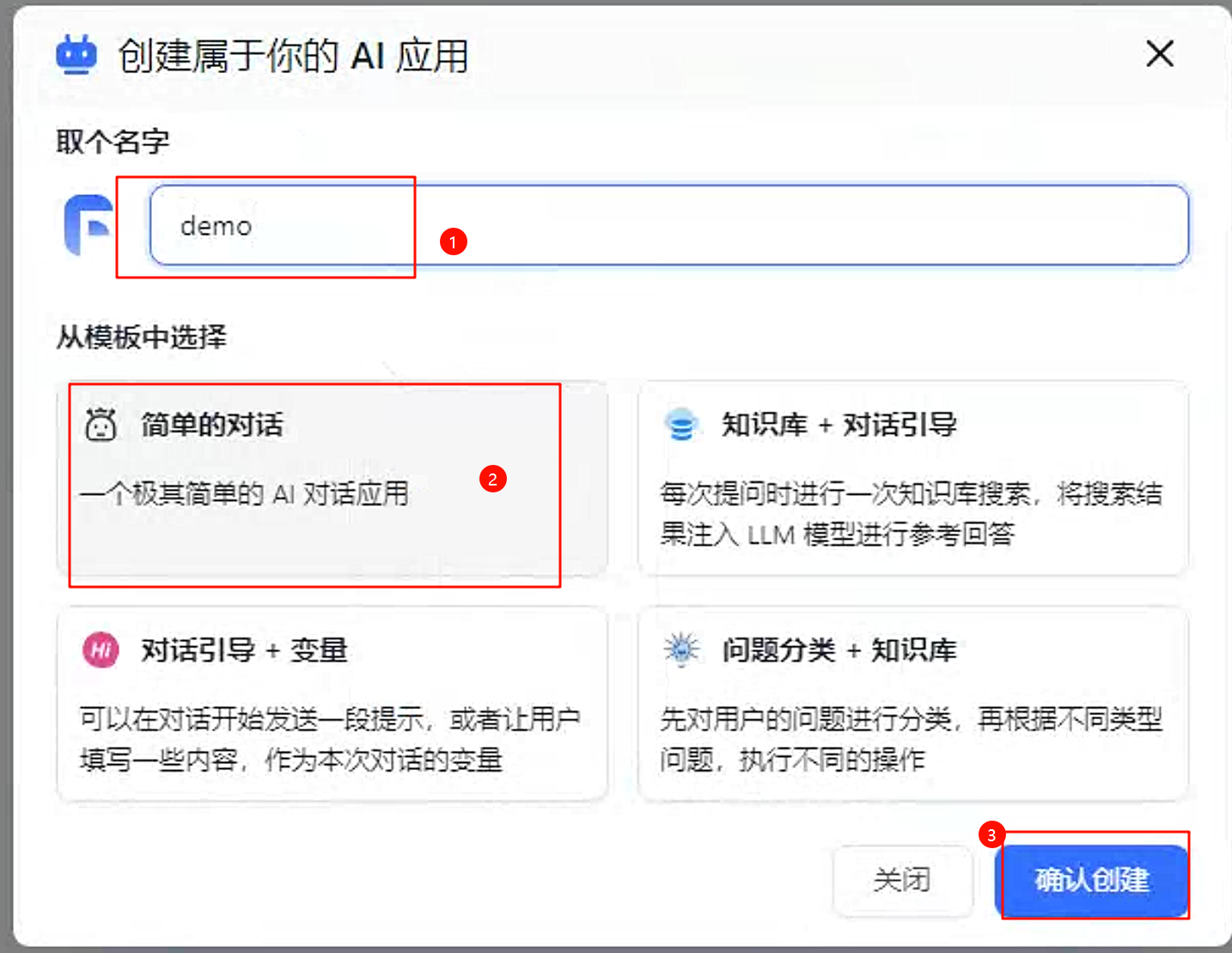
填写名字,选择简单对话,点击确认创建
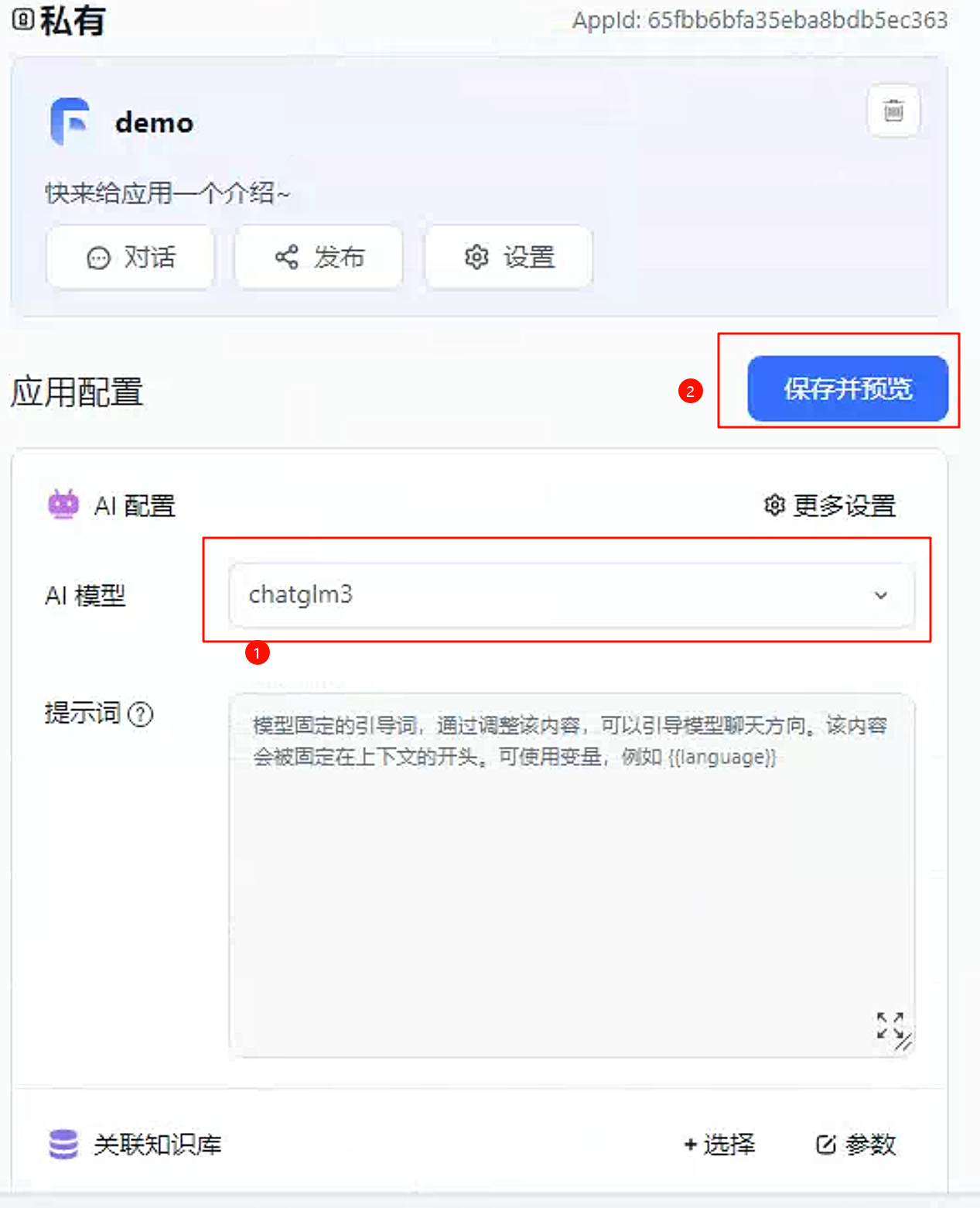
选择AI模型为chatglm3,保存并预览
接下来回到首页,点击聊天。
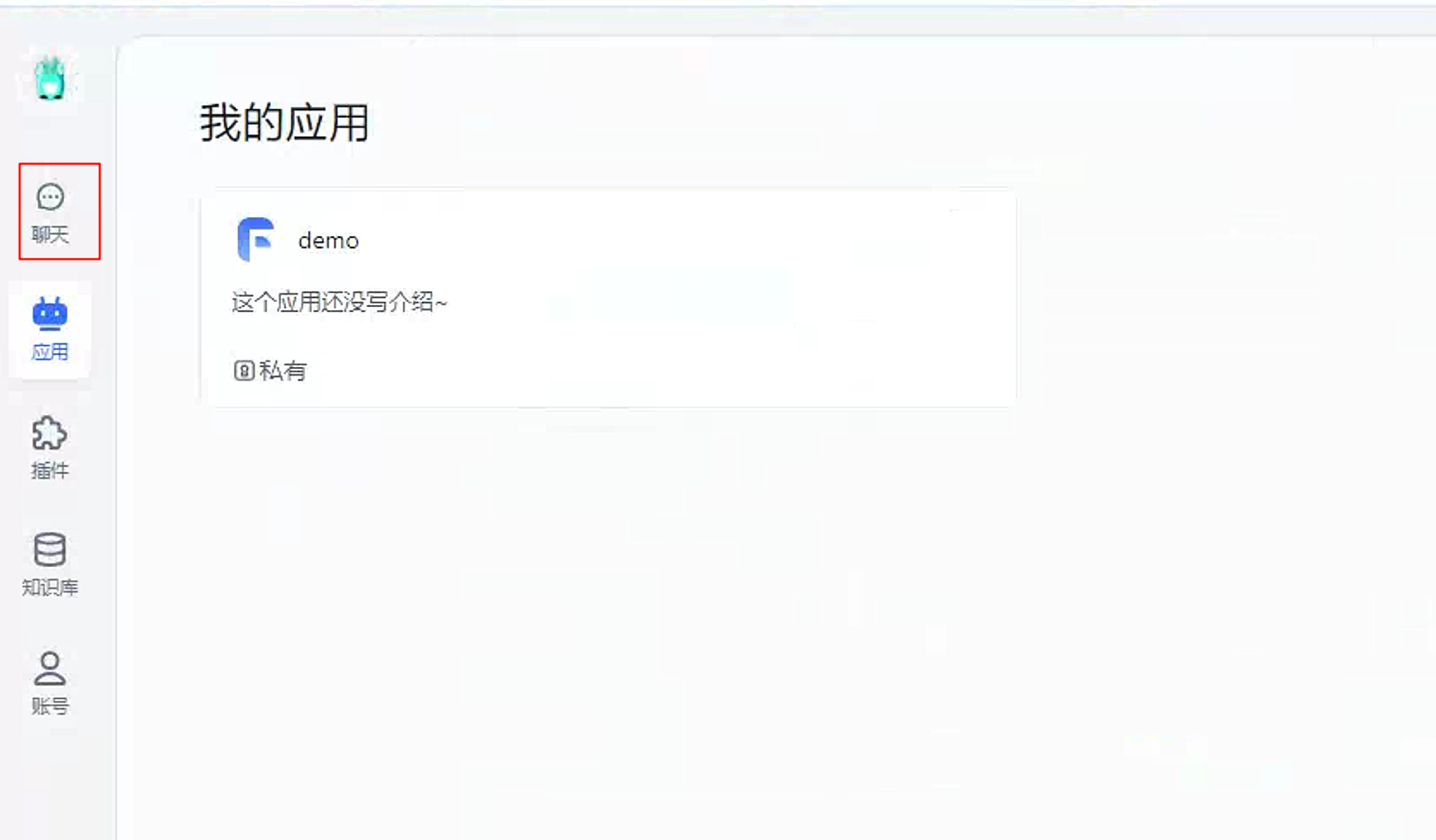
在输入框输出文字即可开始聊天。
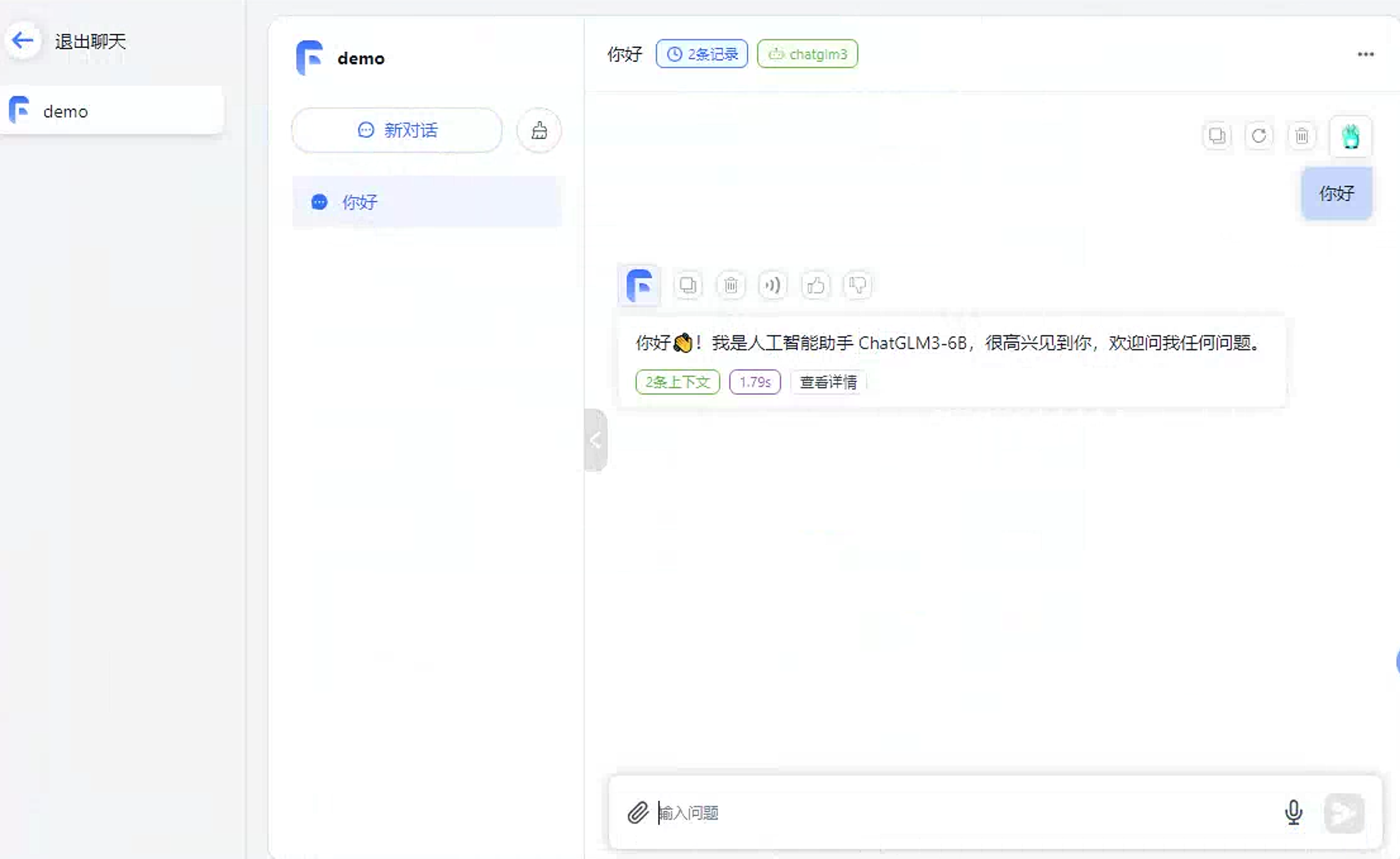
基于现有知识库问答
点击知识库,新建知识库
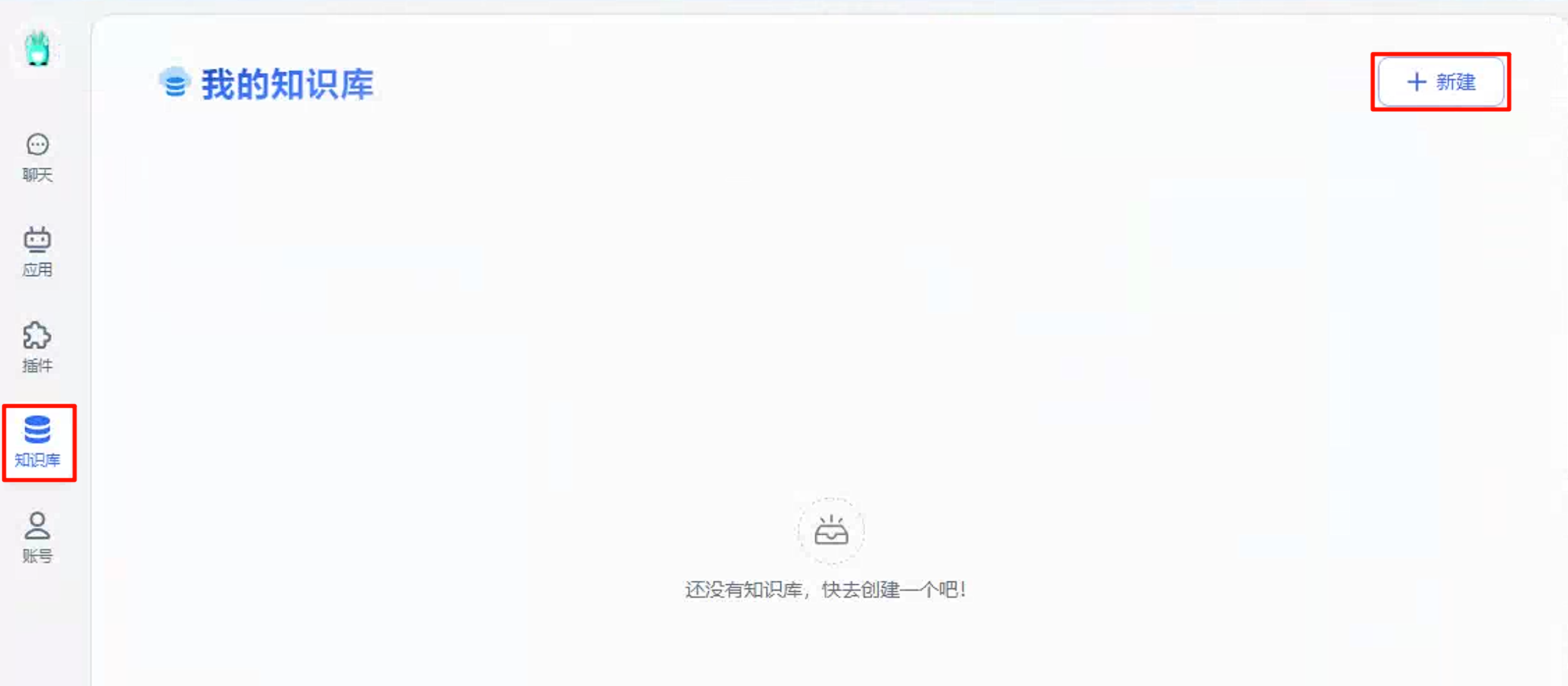

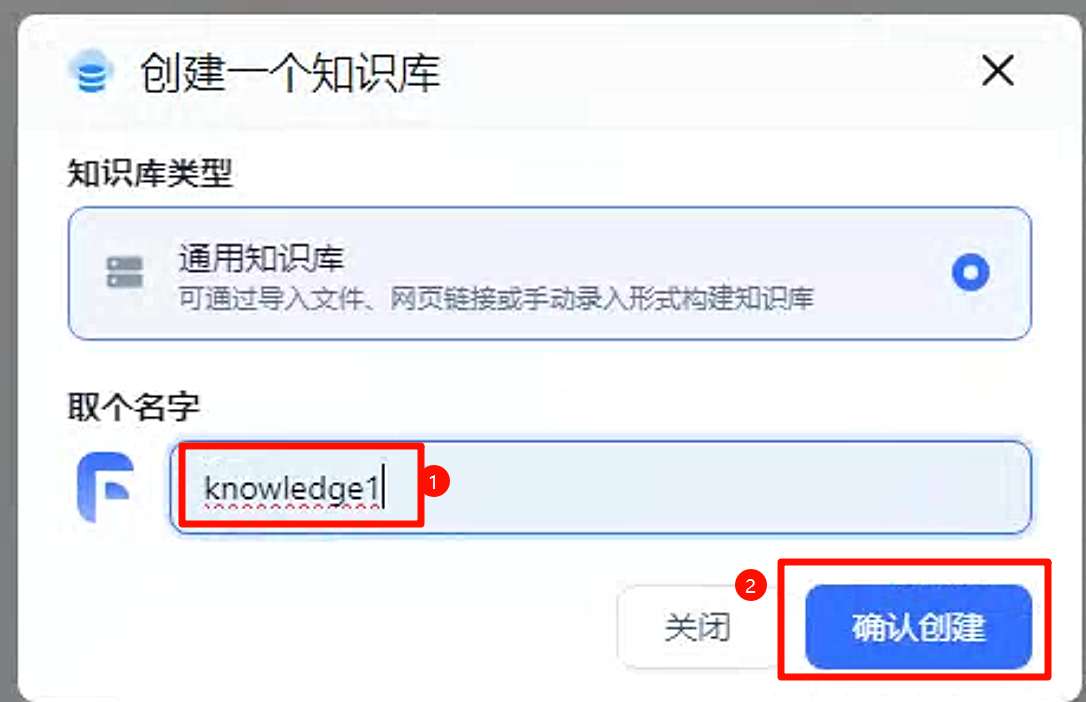
输入知识库名称,点击创建
点击右上角新建/导入按钮,可以看到知识库的导入有3种形式。
手动数据集
创建知识库后默认会有一个手动数据集,名称为手动录入。
手动数据集可以认为的输入一些文本内容充当知识库,让大模型去学习你编写的文字内容。

创建完后可以将应用和知识库关联起来。创建新应用,选择
知识库+对话引导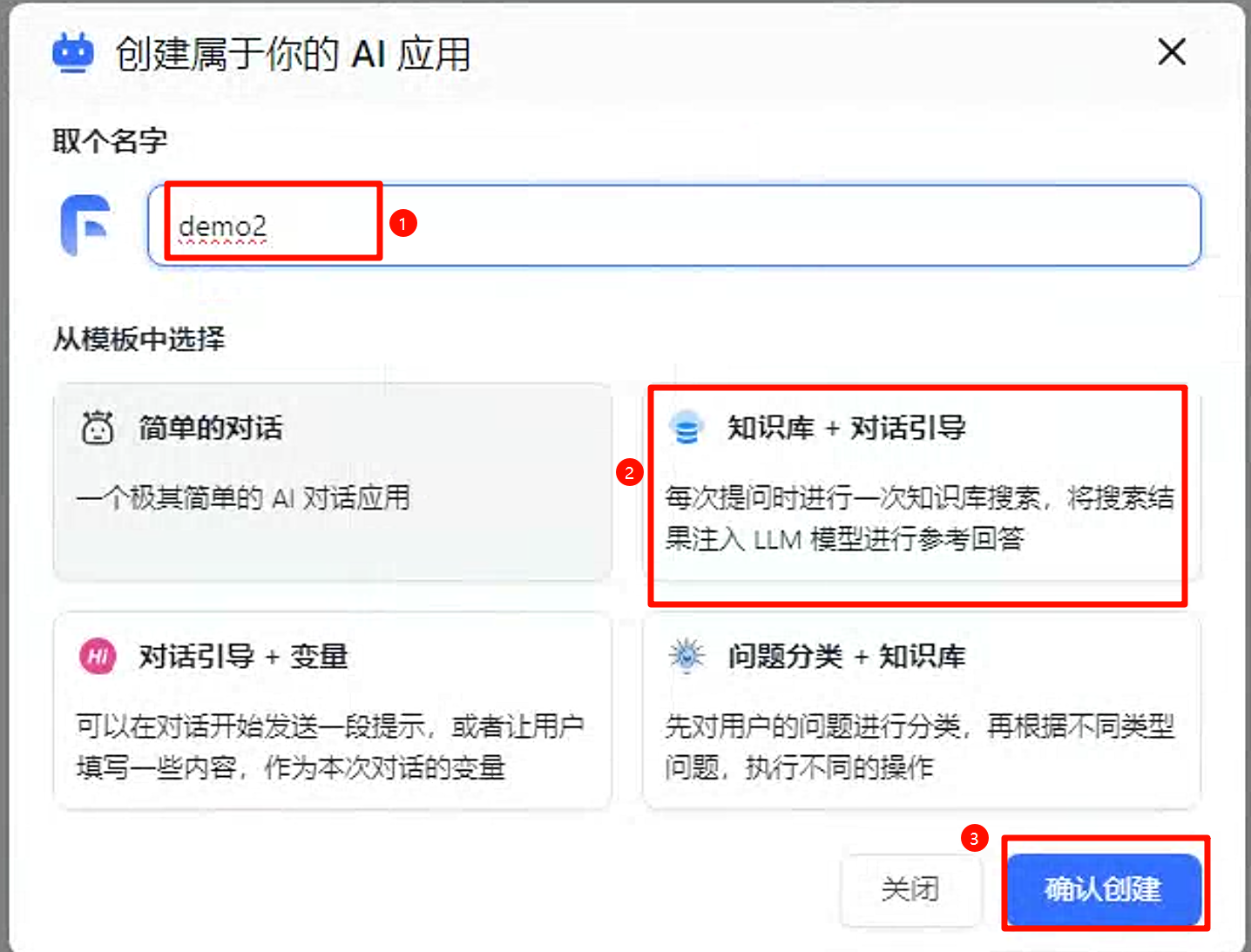
然后在配置种关联刚才创建的知识库,点击保存并预览。
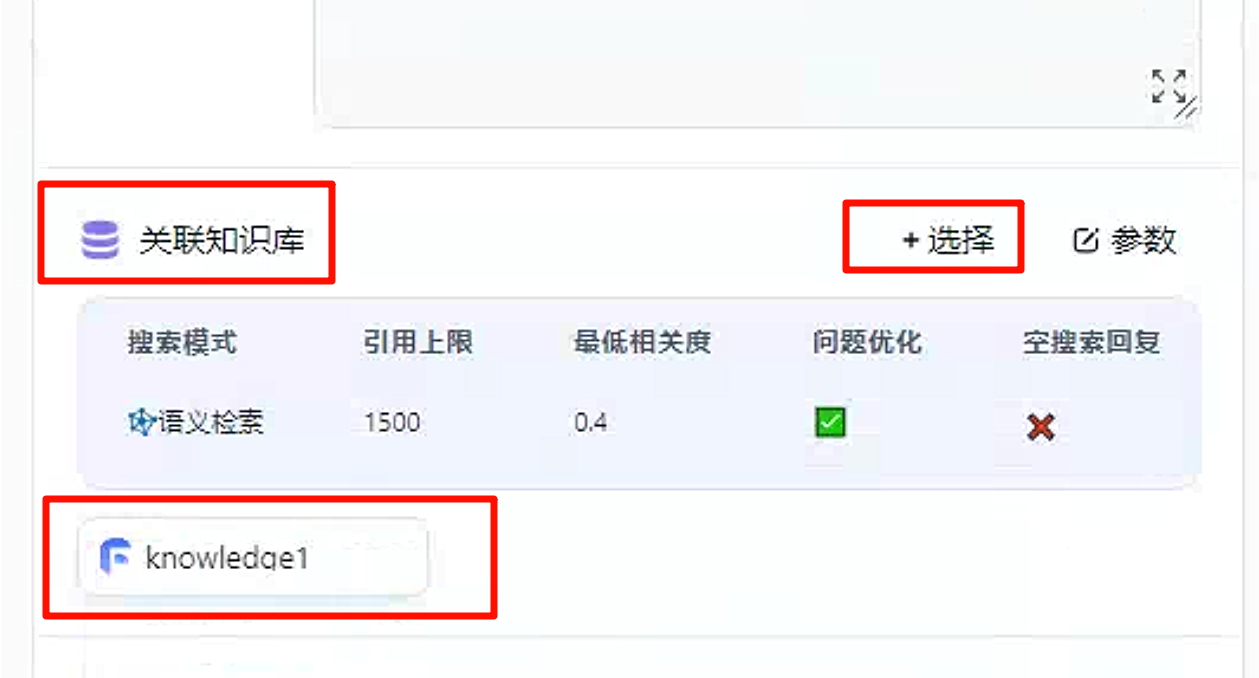
提问效果如下所示。
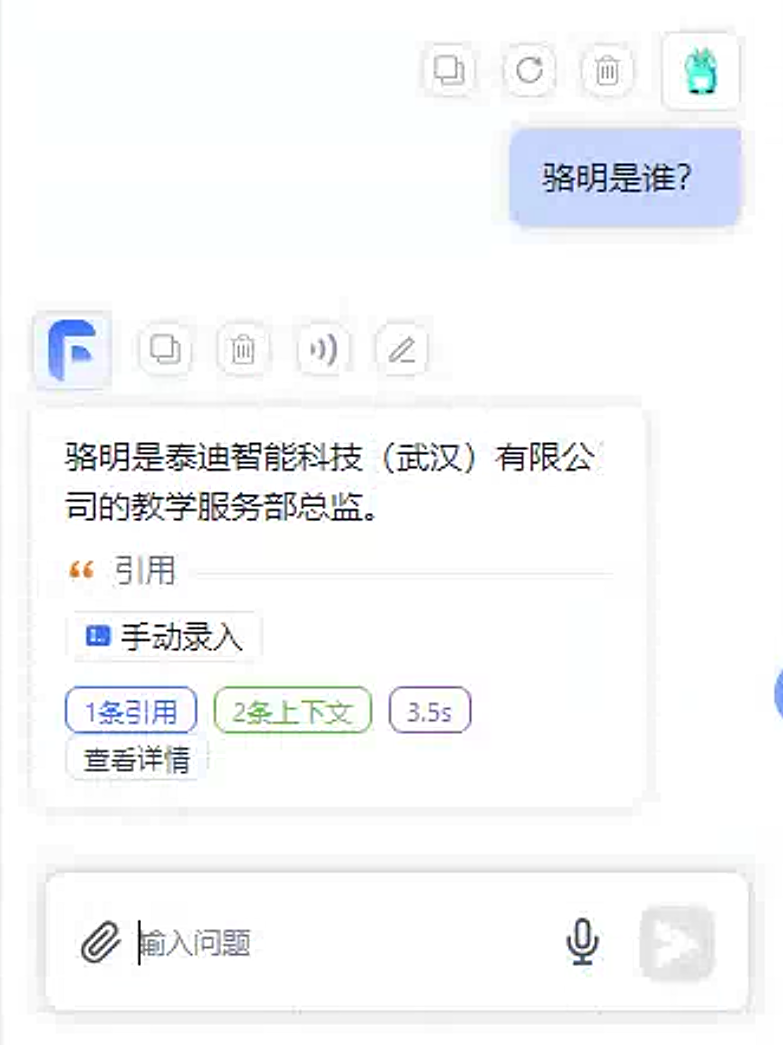
可以看到知识库种手动编写的文本信息被正确回答出来了。
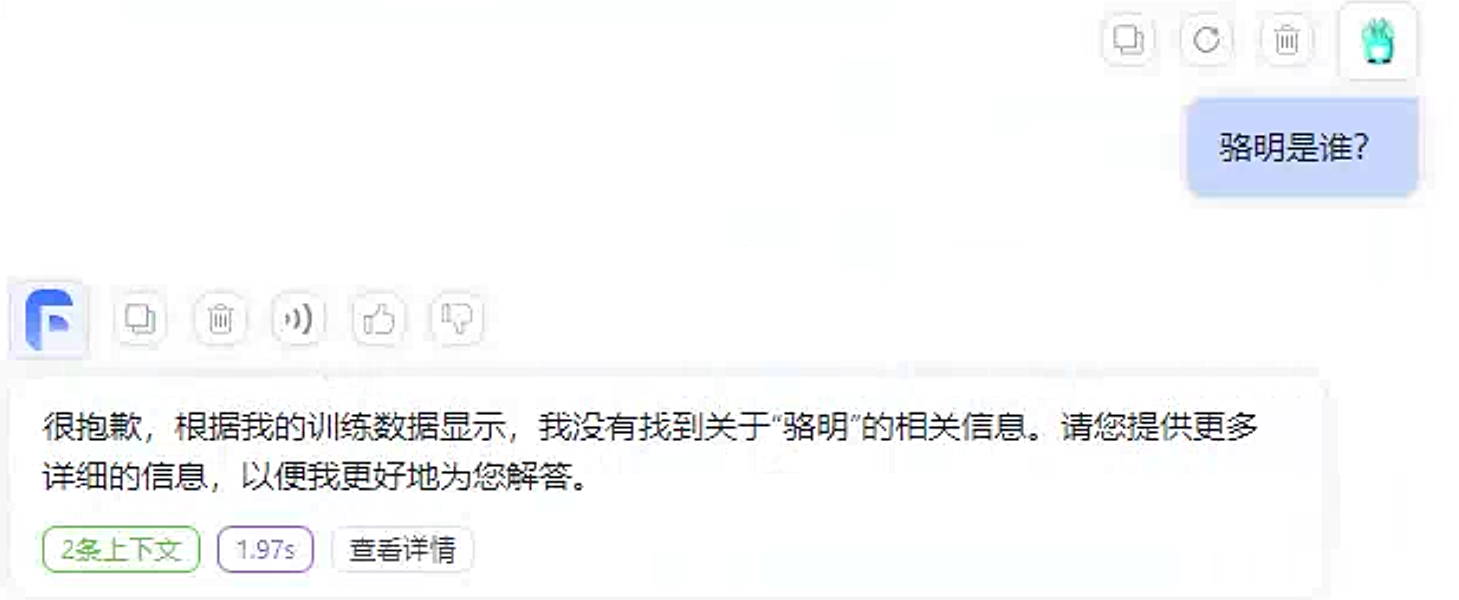
未关联知识库的回答如下:
文本数据集
文本数据集有三个选项:
- 本地文件
- 网页链接(只能读取静态网页内容作为数据集)
- 自定义文本

在此我们先选择第一个本地文件,将以下文件上传至平台中。
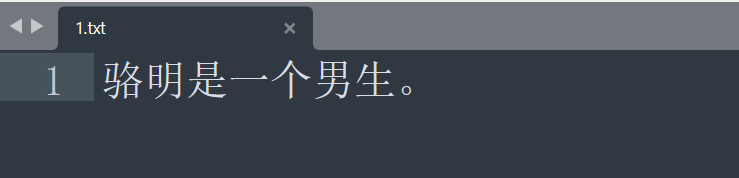
上传文件
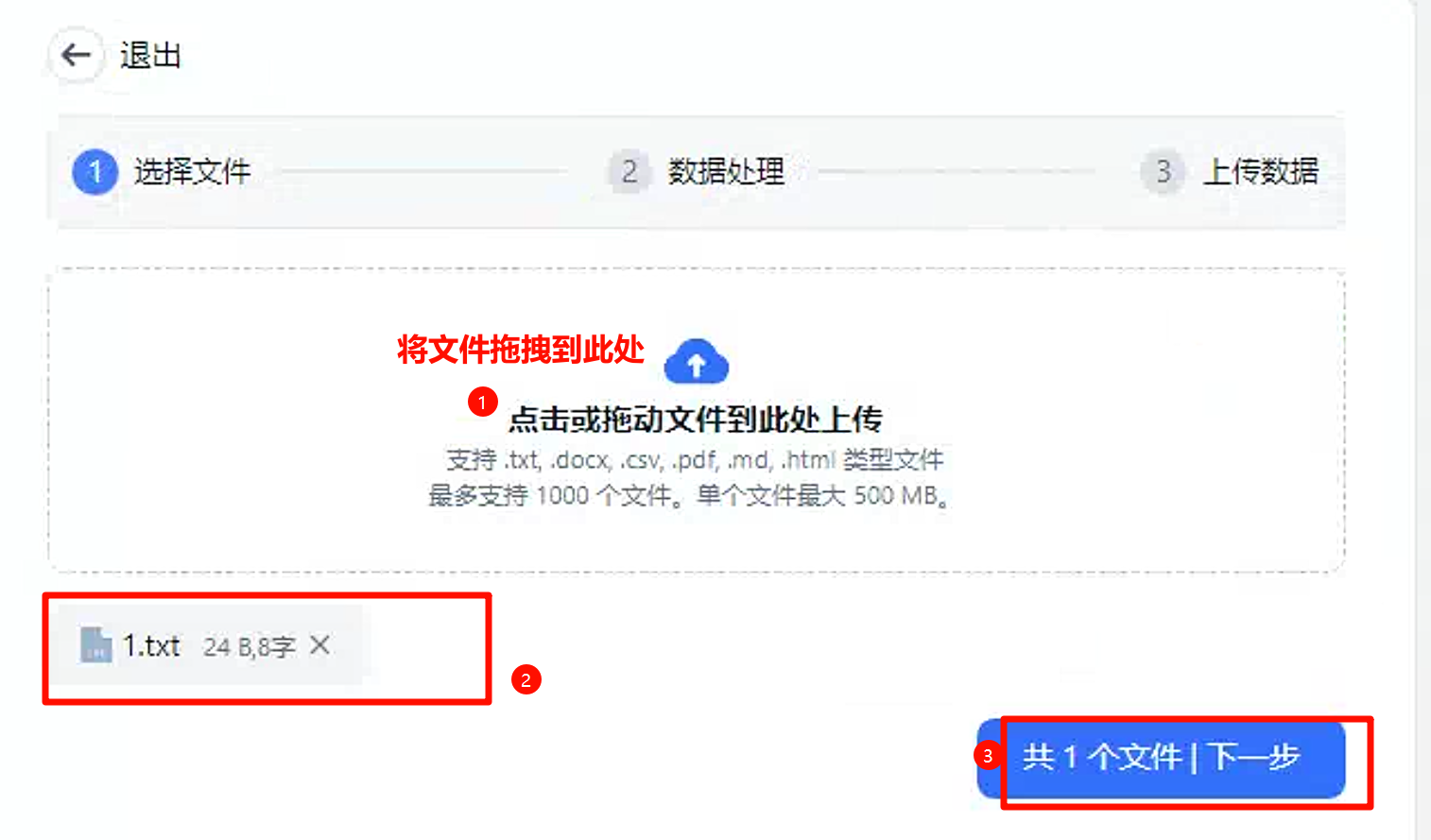
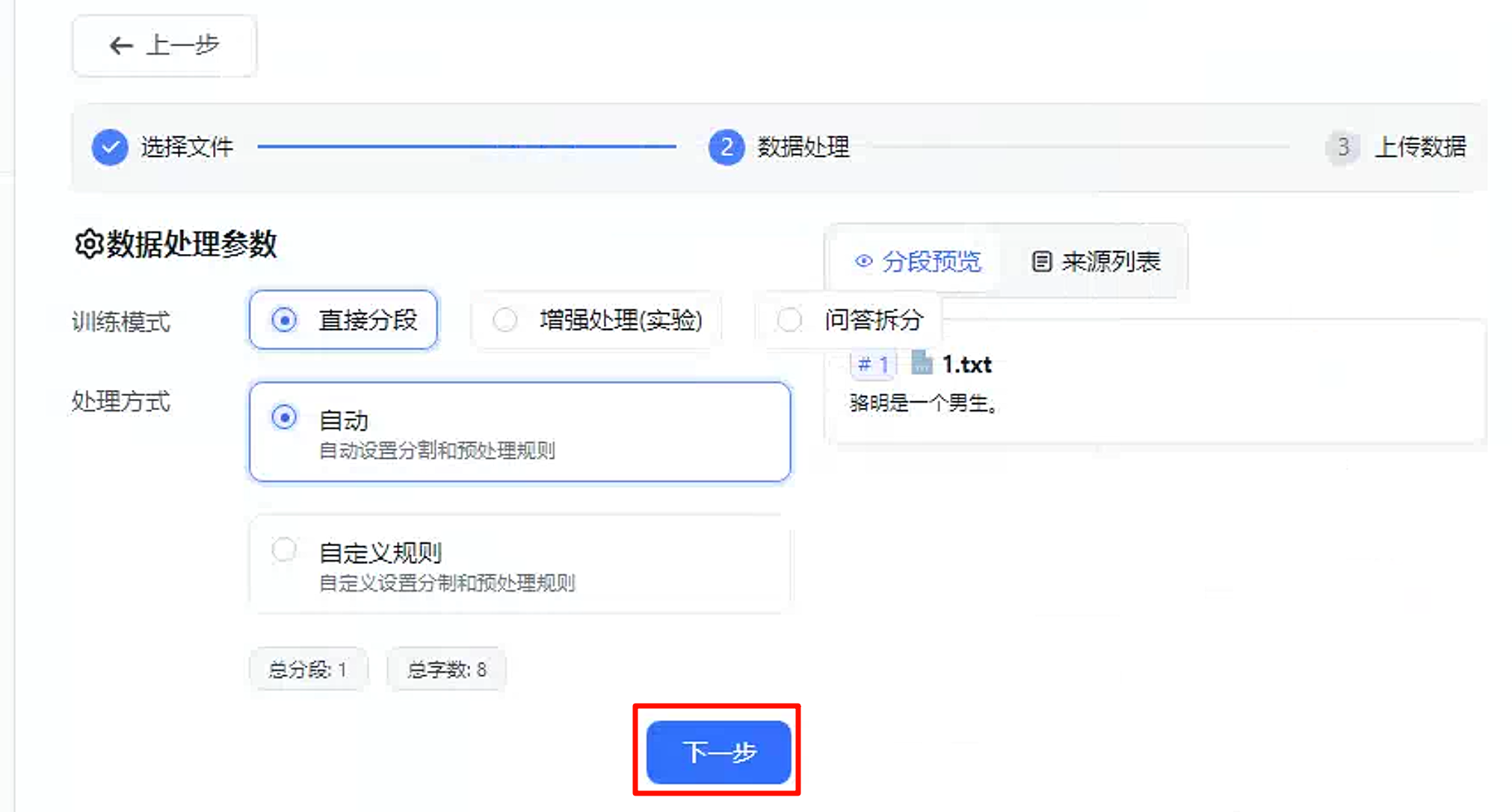
点击下一步,后继续下一步。
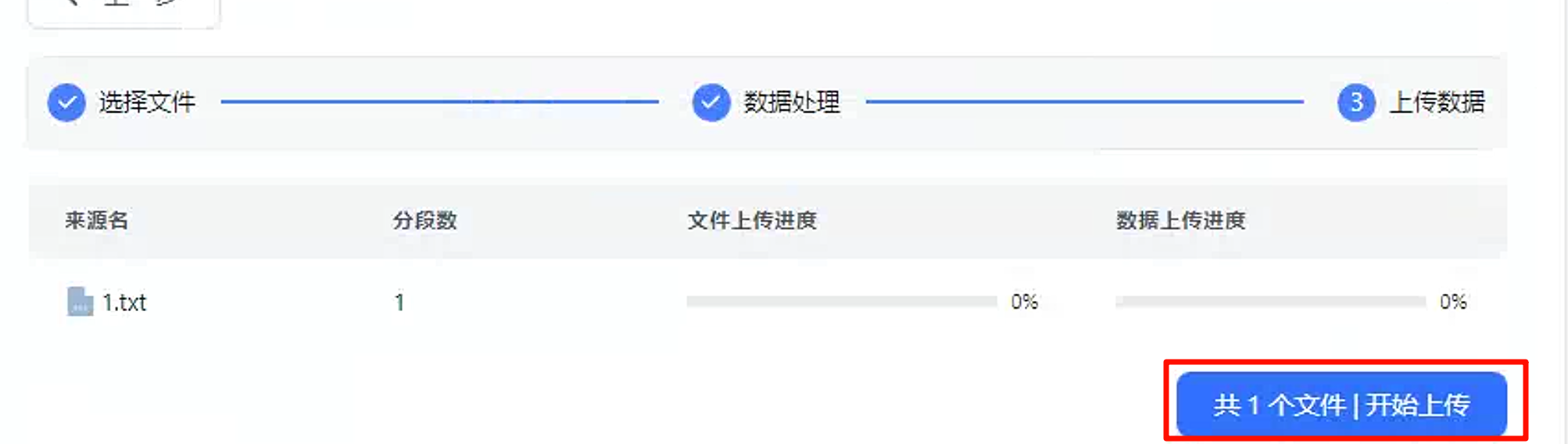
点击开始上传。
这个时候回到
demo2应用中进行测试。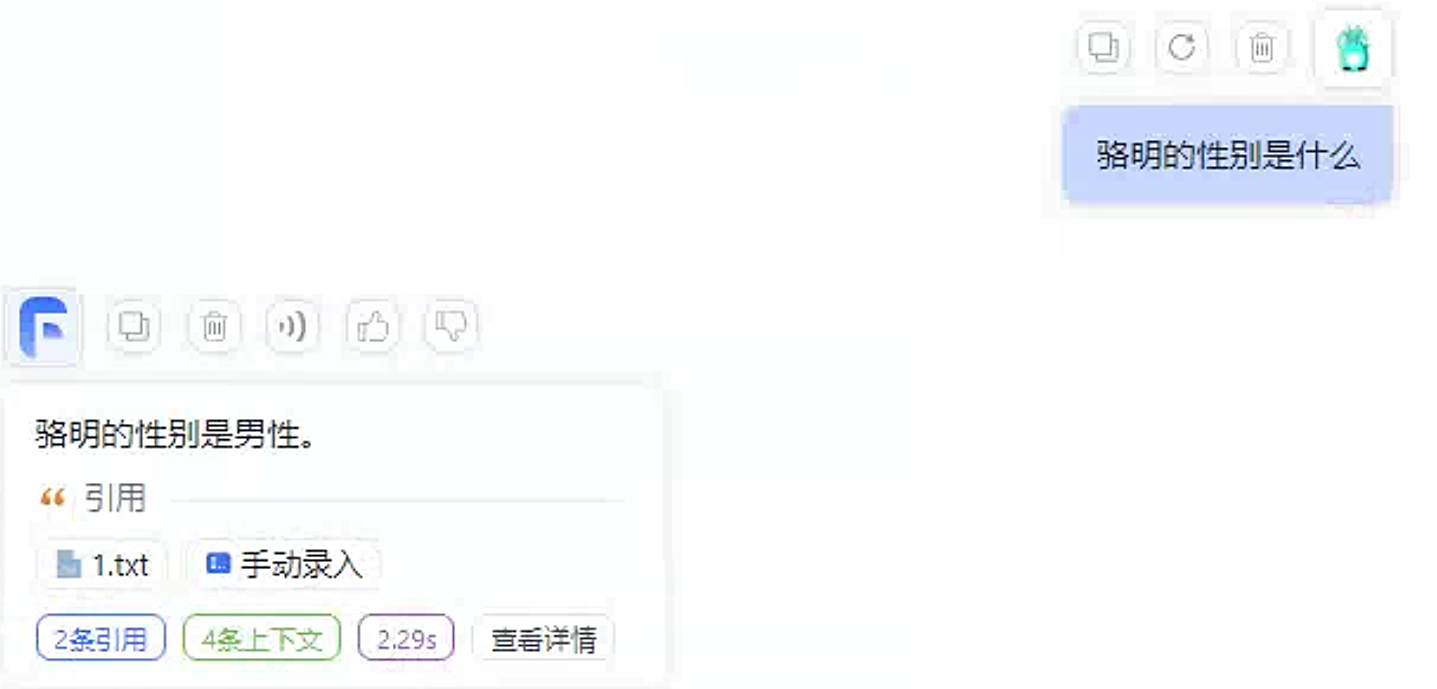
成功回答出正确内容。
未关联知识库的回答如下:
网页链接测试
在知识库中给定网址:http://minglog.hzbmmc.com/about/
测试回答效果如下:
可见网页内容被成功解析。
表格数据集
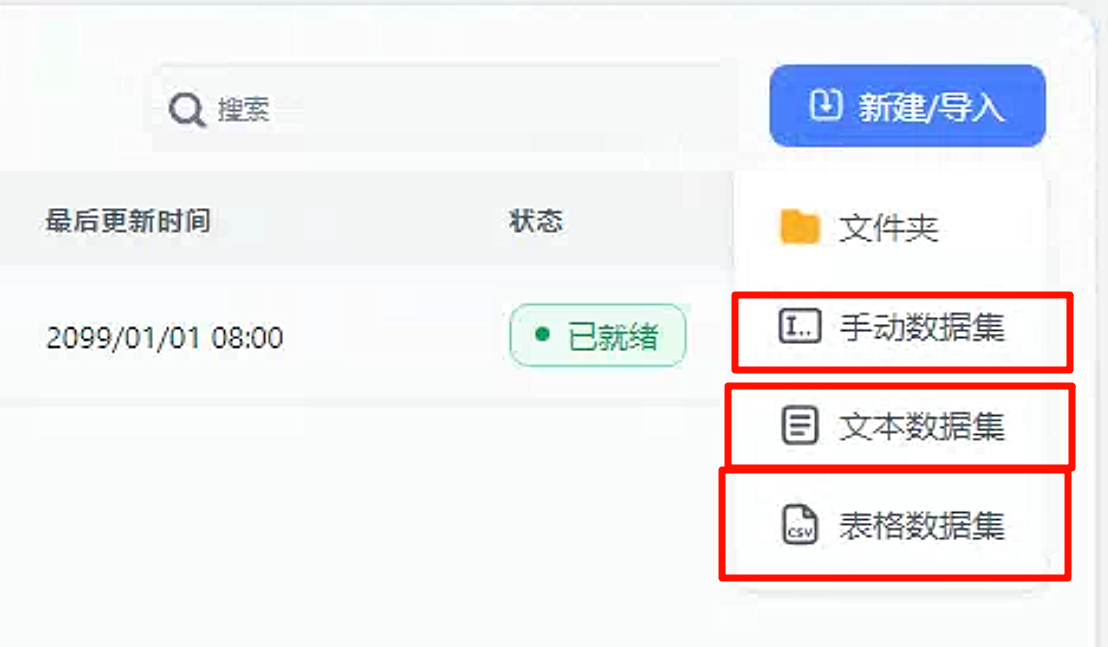
表格数据集的文件类型未
csv文件,并且对于文件中的内容有要求,提供了模板文件。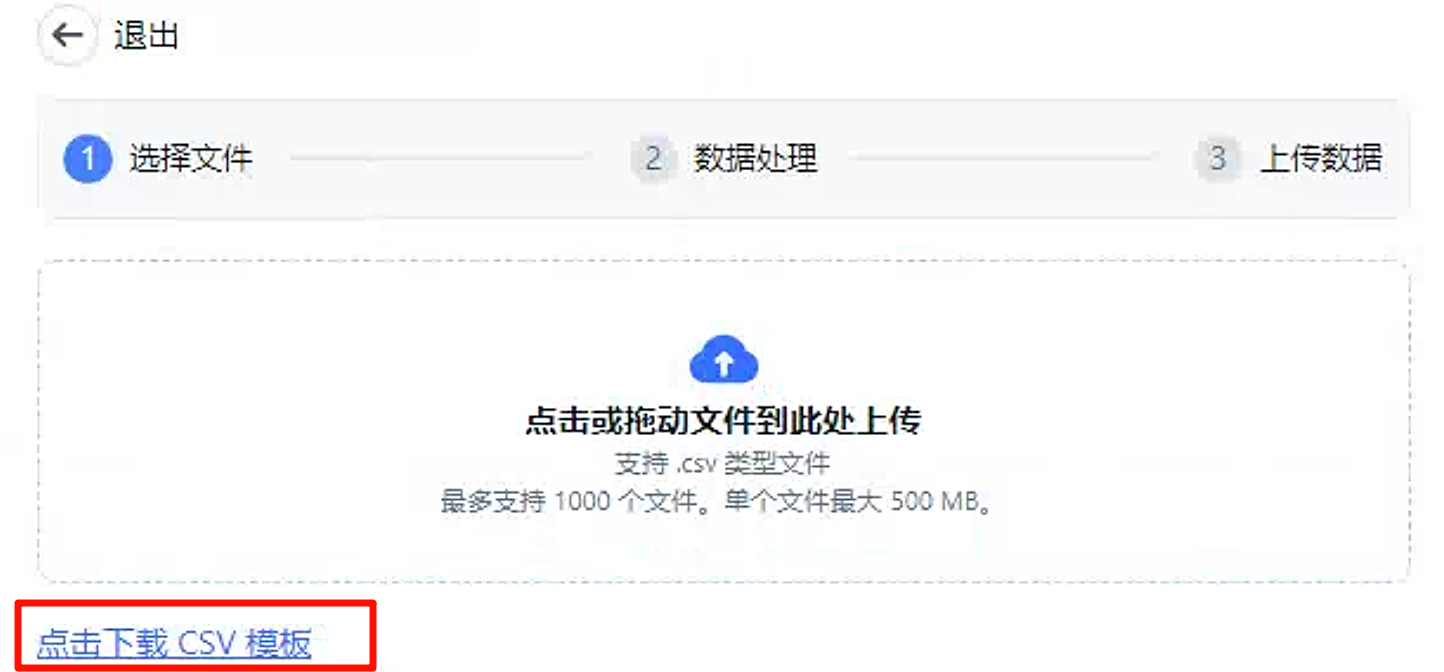
直接将模板文件下载下来,然后上传。

点击下一步,将会解析表格文件内容。
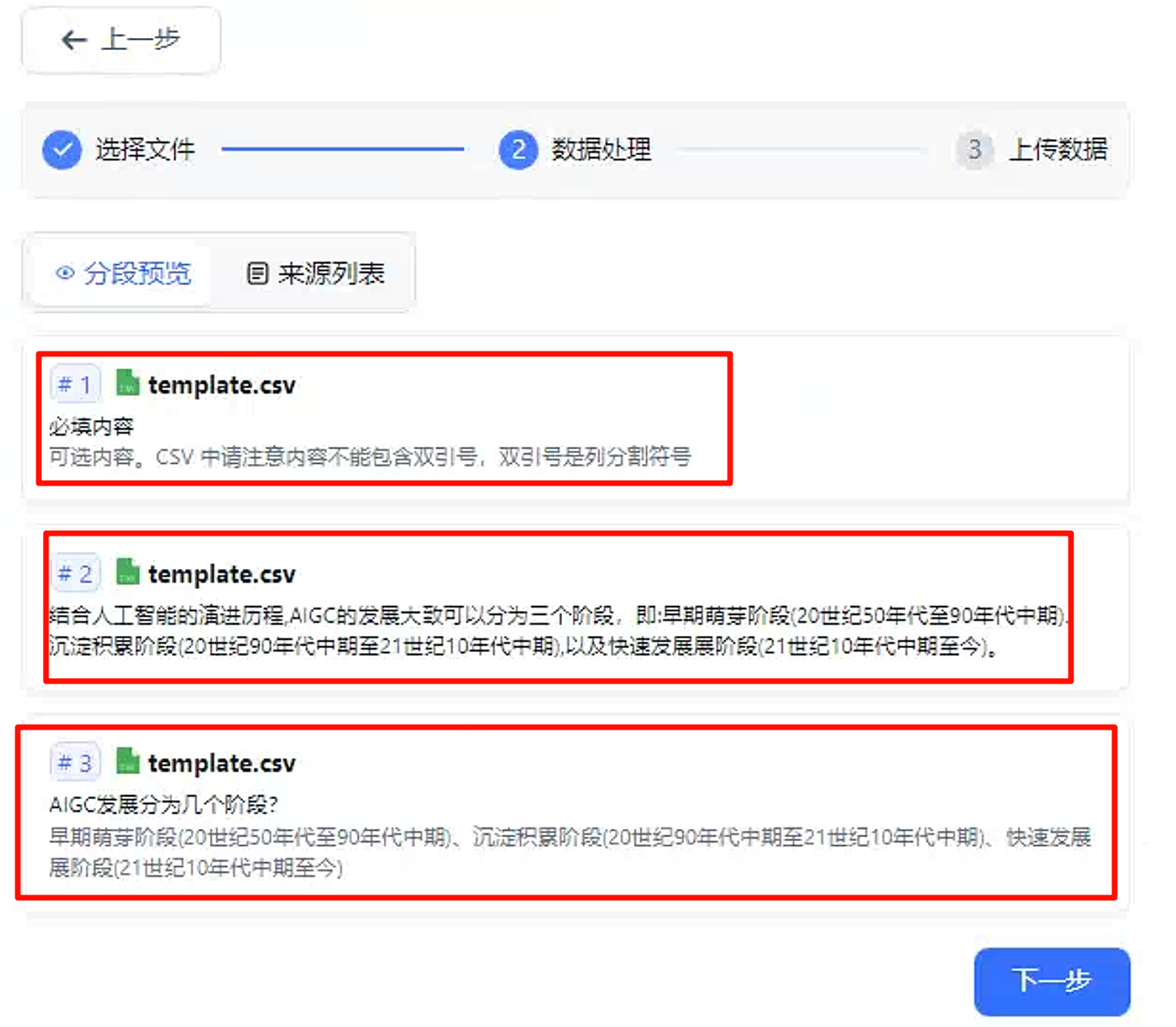
点击下一步,开始上传。
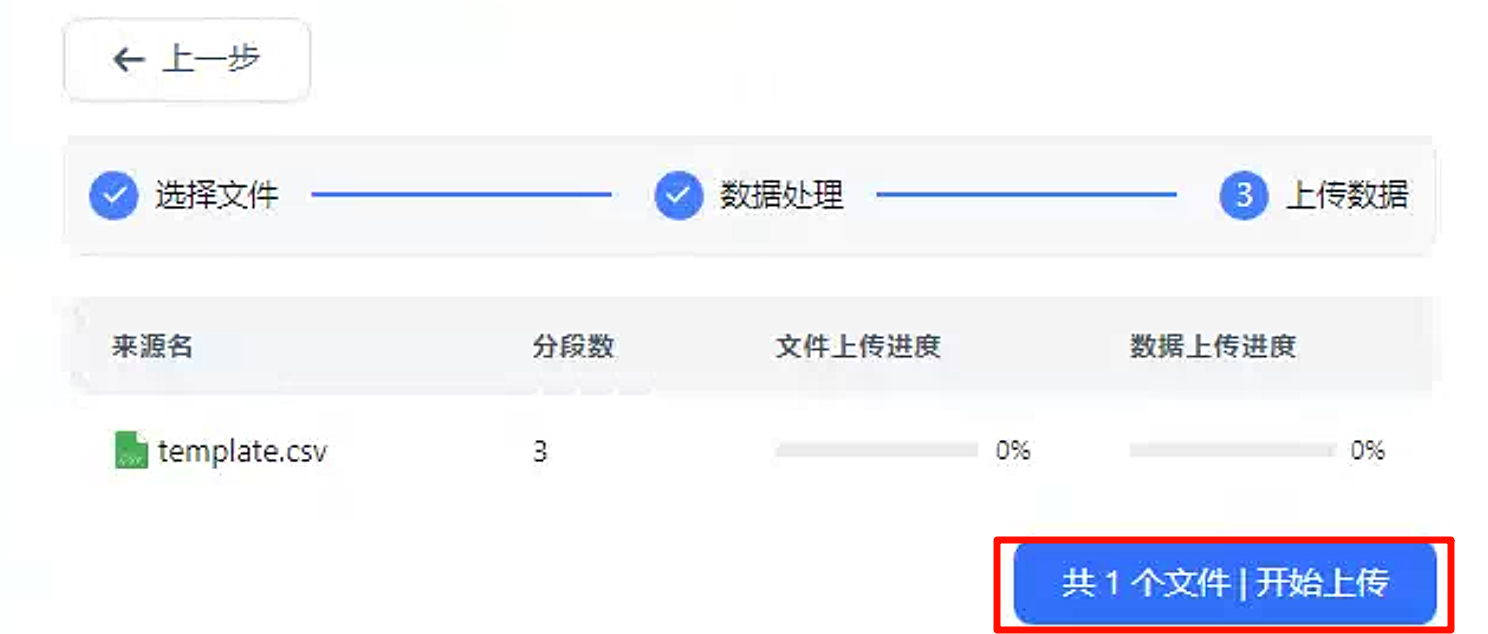
测试
demo2。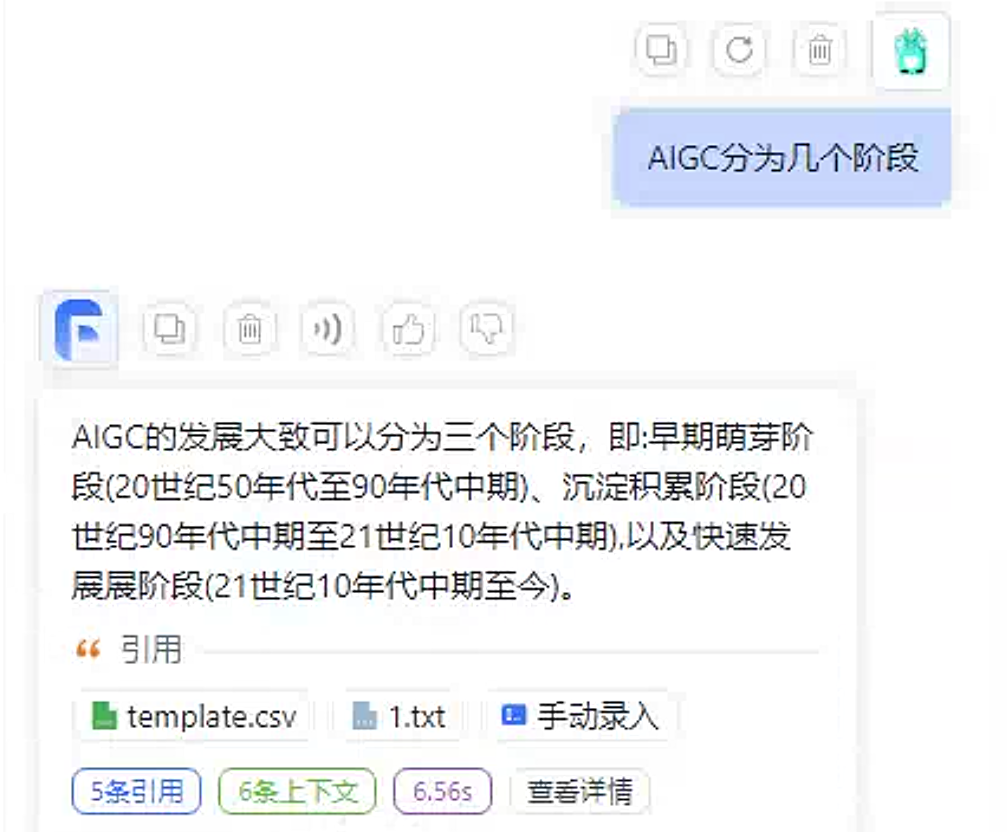
未关联知识库的回答如下:
大模型微调
使用LLaMA-Factory微调ChatGLM3模型。
进入models文件夹下,下载LLaMA-Factory源码
1 | cd /root/models |
进入LLaMA-Factory项目
1 | cd LLaMA-Factory |
创建虚拟环境
1 | conda create -n llama_factory python=3.10 |
激活虚拟环境并下载依赖
1 | conda activate llama_factory |
在进行微调之前首先准备好微调用到的数据集,并上传至LLaMA-Factory项目下的data目录.
1 | [ |
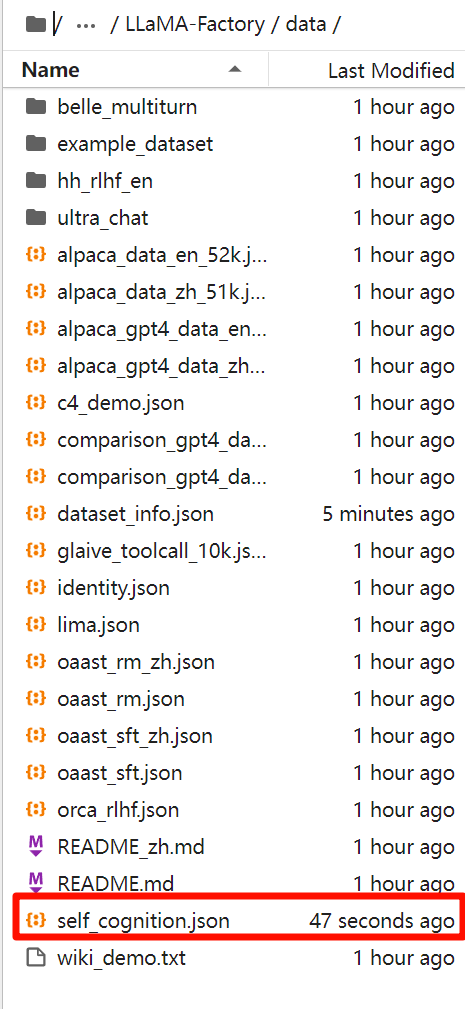
如果您使用自定义数据集,请务必在
dataset_info.json文件中按照以下格式提供数据集定义。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
"hf_hub_url": "Hugging Face 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"ms_hub_url": "ModelScope 的数据集仓库地址(若指定,则忽略 script_url 和 file_name)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)",
"file_name": "该目录下数据集文件的名称(若上述参数未指定,则此项必需)",
"file_sha1": "数据集文件的 SHA-1 哈希值(可选,留空不影响训练)",
"subset": "数据集子集的名称(可选,默认:None)",
"folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)",
"ranking": "是否为偏好数据集(可选,默认:False)",
"formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)",
"columns(可选)": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)",
"messages": "数据集代表消息列表的表头名称(默认:conversations)",
"system": "数据集代表系统提示的表头名称(默认:None)",
"tools": "数据集代表工具描述的表头名称(默认:None)"
},
"tags(可选,用于 sharegpt 格式)": {
"role_tag": "消息中代表发送者身份的键名(默认:from)",
"content_tag": "消息中代表文本内容的键名(默认:value)",
"user_tag": "消息中代表用户的 role_tag(默认:human)",
"assistant_tag": "消息中代表助手的 role_tag(默认:gpt)",
"observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)",
"function_tag": "消息中代表工具调用的 role_tag(默认:function_call)",
"system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system 列)"
}
}添加后可通过指定
--dataset 数据集名称参数使用自定义数据集。该项目目前支持两种格式的数据集:alpaca 和 sharegpt,其中 alpaca 格式的数据集按照以下方式组织:
2
3
4
5
6
7
8
9
10
11
12
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]对于上述格式的数据,
dataset_info.json中的columns应为:
2
3
4
5
6
7
8
9
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}其中
query列对应的内容会与prompt列对应的内容拼接后作为用户指令,即用户指令为prompt\nquery。response列对应的内容为模型回答。
system列对应的内容将被作为系统提示词。history列是由多个字符串二元组构成的列表,分别代表历史消息中每轮的指令和回答。注意历史消息中的回答也会被用于训练。对于预训练数据集,仅
prompt列中的内容会用于模型训练。对于偏好数据集,
response列应当是一个长度为 2 的字符串列表,排在前面的代表更优的回答,例如:
2
3
4
5
6
7
8
"instruction": "用户指令",
"input": "用户输入",
"output": [
"优质回答",
"劣质回答"
]
}而 sharegpt 格式的数据集按照以下方式组织:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"conversations": [
{
"from": "human",
"value": "用户指令"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]对于上述格式的数据,
dataset_info.json中的columns应为:
2
3
4
5
6
7
8
9
10
11
12
13
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "human",
"assistant_tag": "gpt"
}
}其中
messages列应当是一个列表,且符合用户/模型/用户/模型/用户/模型的顺序。预训练数据集和偏好数据集尚不支持
sharegpt格式。
修改LLaMA-Factory项目中data/dataset_info.json文件,在json文件中添加以下内容。
1 | "self_cognition": { |

开启LLaMA-Factory Web项目
1 | python /root/models/LLaMA-Factory/src/train_web.py |

接下来打开WEB页面 http://139.186.232.103:7860/ (注意修改IP地址),安装下图所示内容进行修改。
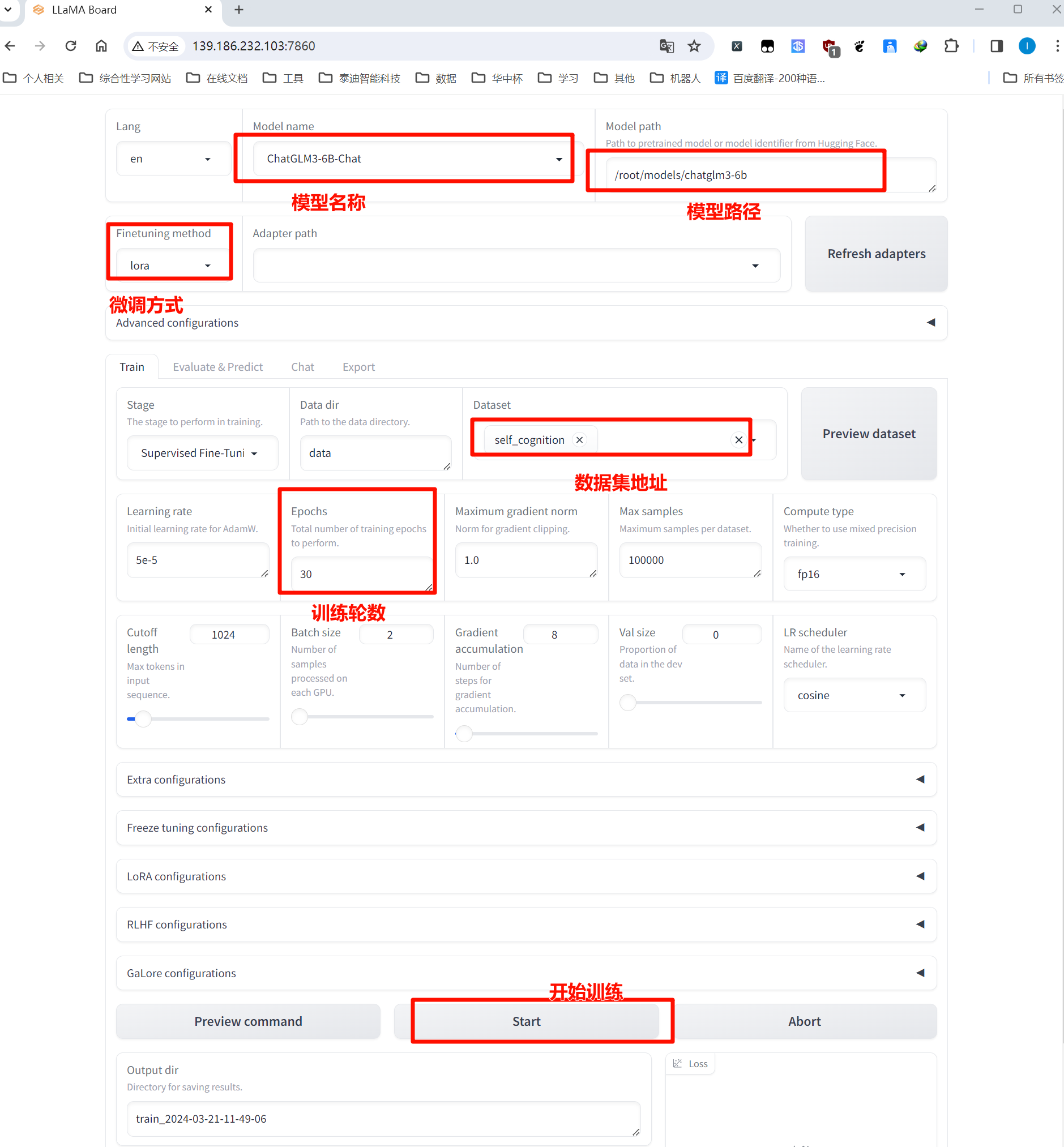
注意此时如果直接点击
Start开始i训练可能会出现报错,报错的原因是因为显存不够,前面我们已经开启了一个ChatGLM3 API消耗了显存,可以把前面的API关闭,重新进行训练。

开始训练模型。
30轮训练完毕,模型微调完成。

导出微调后的模型。
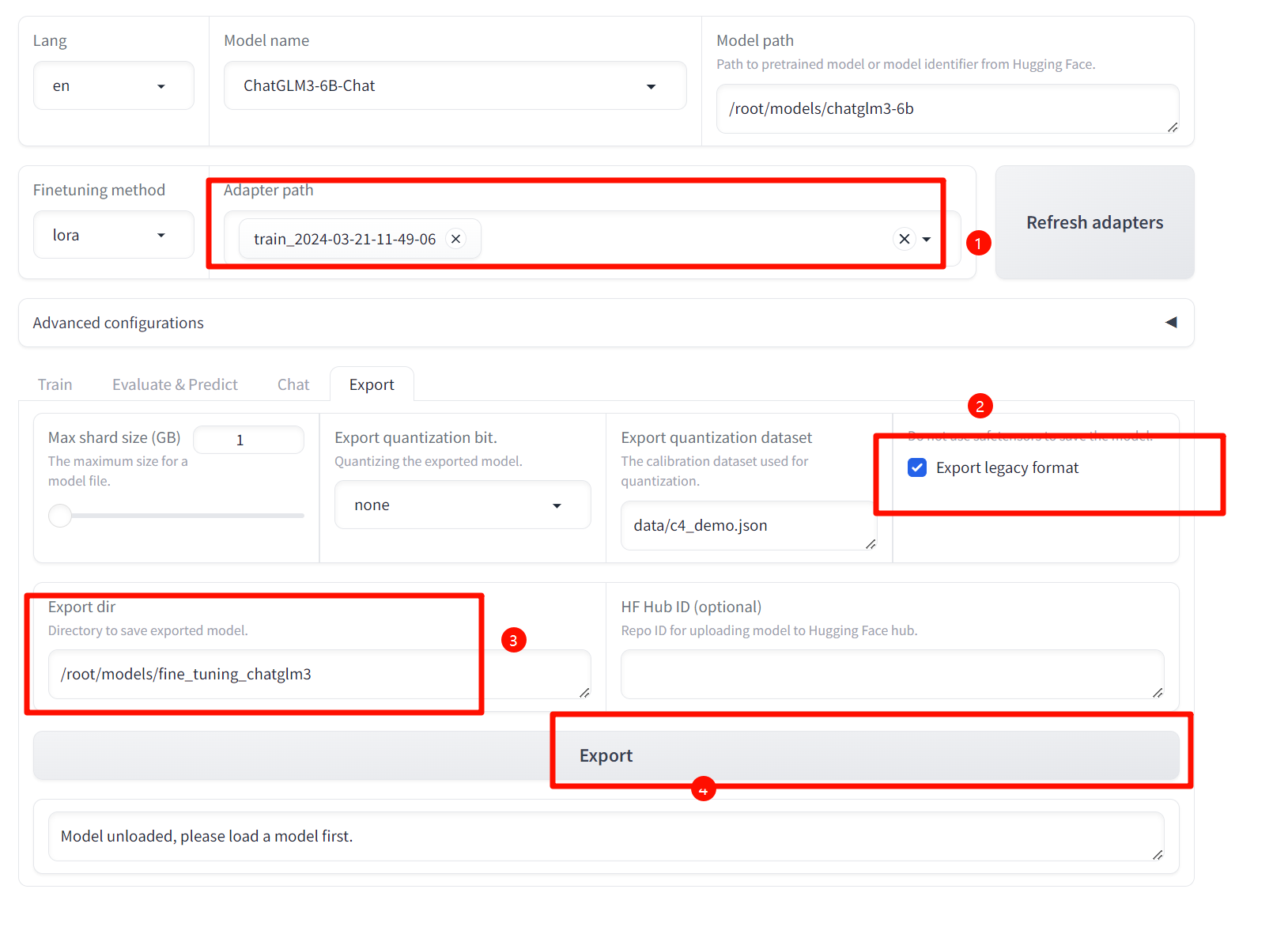
查看导出模型
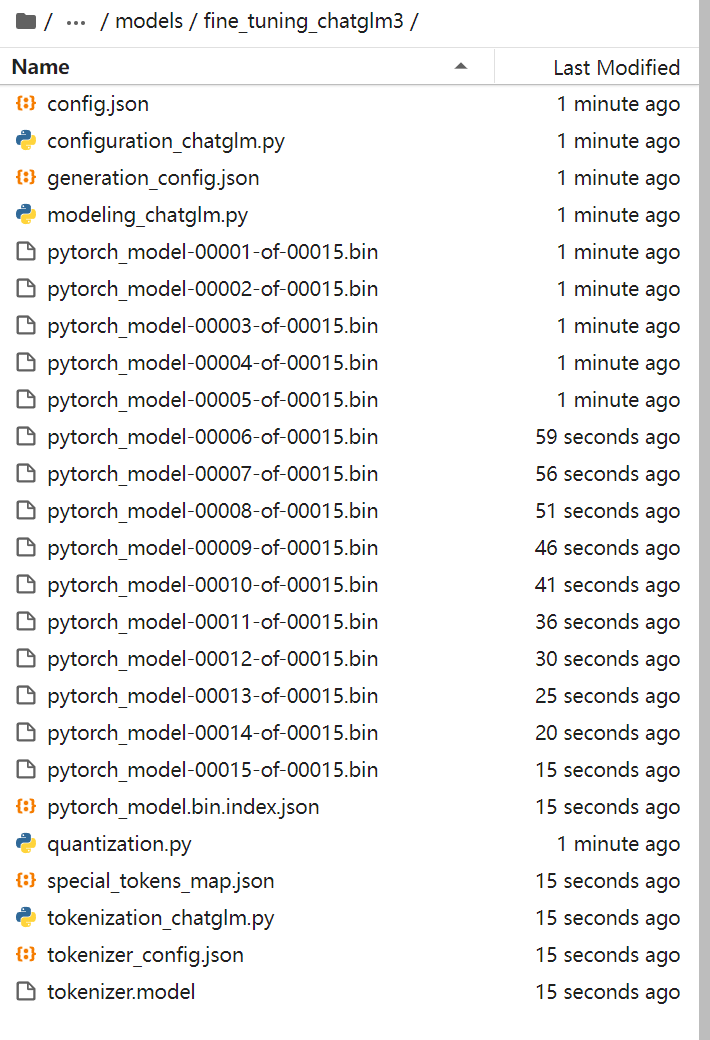
测试微调模型,将导出后的模型部署到ChatGLM3 API
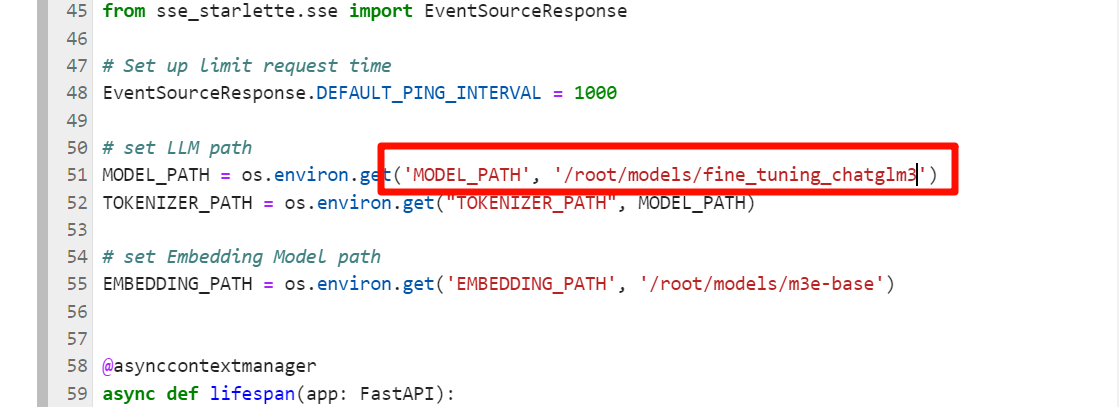
验证是否微调成功。
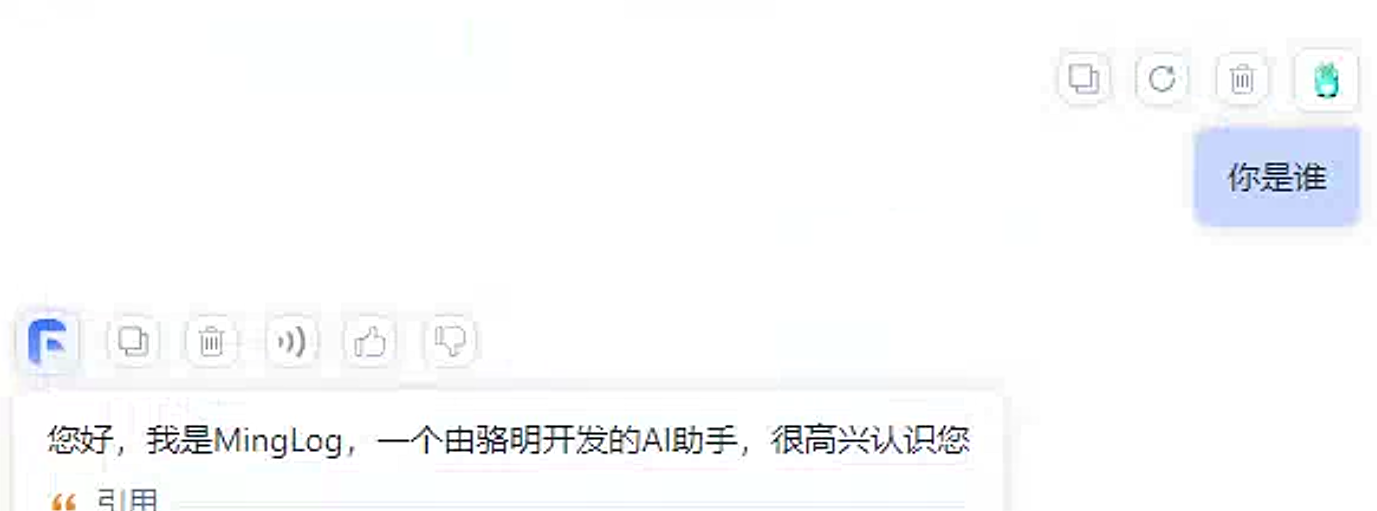
微调成功!