马尔可夫模型
首先,我们来看一下马尔可夫模型。
马尔可夫模型(Markov Model):马尔可夫模型是一种统计模型,它基于马尔可夫性质进行建模。马尔可夫性质指的是系统的下一个状态仅取决于其当前状态,而与过去的状态无关。这种性质使得马尔可夫模型在处理一系列具有时间依赖性的数据时非常有用。
广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域。经过长期发展,尤其是在语音识别中的成功应用,使它成为一种通用的统计工具。
举个具体的例子。例如:天气变化种类{晴天,多云,雷雨}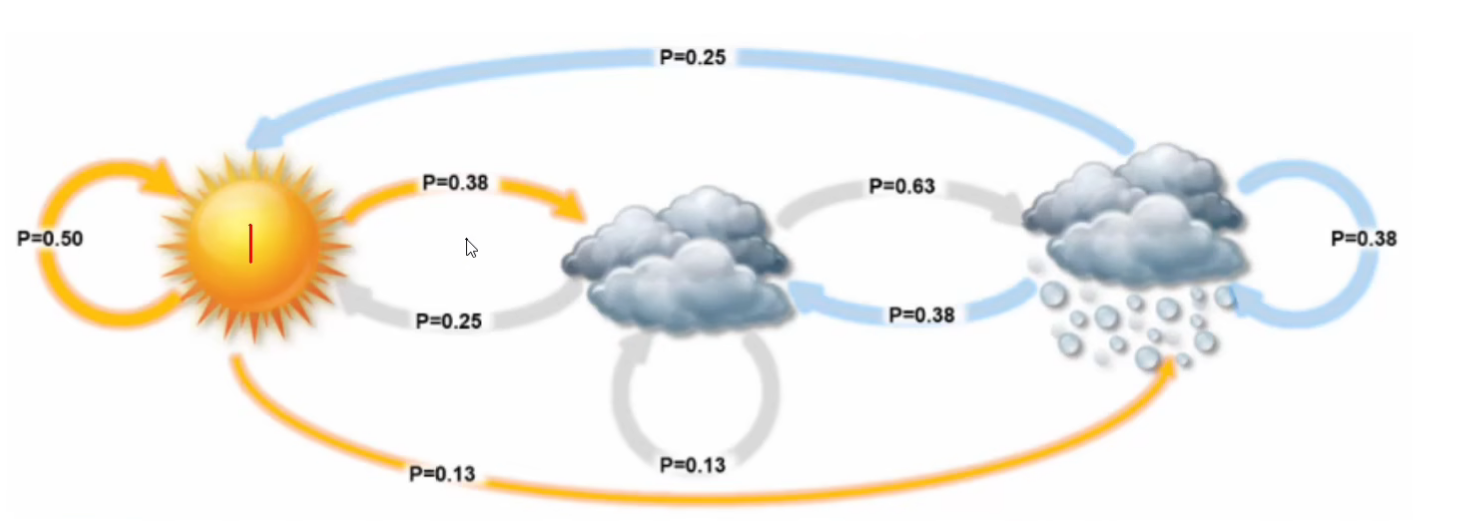
状态转移矩阵:
有了状态转移矩阵那么,我们只需要知道今天的天气情况就可以推导出以后天气的情况。
今天的天气情况我们称为初始概率,如果是晴天那么初始概率为:

那么我们就可以计算出明天的天气情况为:
所以明天天晴的概率为0.5, 多云的概率为0.25, 下雨的概率为0.25
以此类推,继续求出后天天气的概率
这个就是马尔可夫模型,给定初始状态和不同状态之间的转移矩阵即可求出后续任意时间的状态概率分布。
1 | import numpy as np |
1 | # 定义转移概率矩阵 |
1 | # 时刻1(明天)的天气情况 |
array([0.5 , 0.25, 0.25])
1 | # 时刻2(后天)的天气情况 |
array([0.375 , 0.3125, 0.3125])
隐马尔可夫模型(HMM)
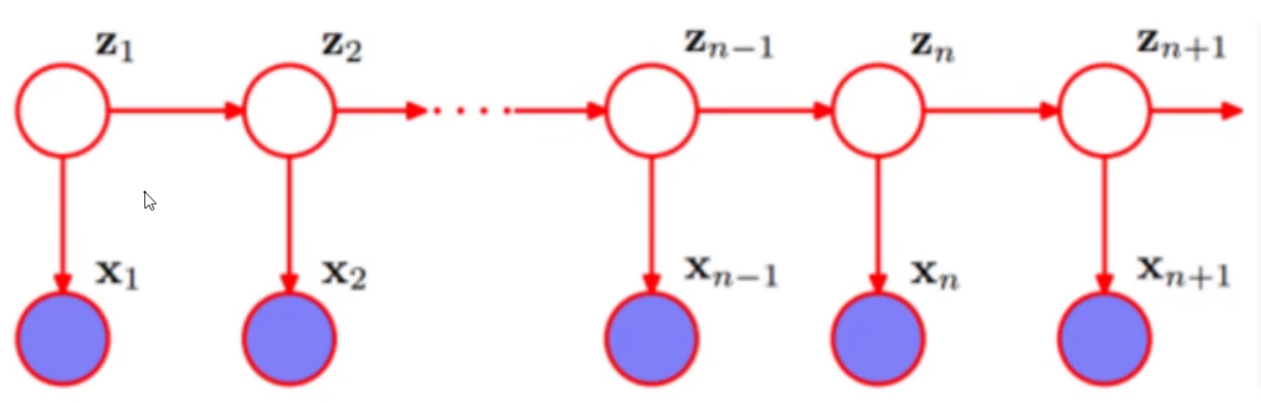
隐马尔可夫模型(Hidden Markov Model),是一种统计模型,用于预测一系列隐藏状态的概率,这些隐藏状态是基于给定的观察状态得出的。在HMM中,状态具有时序关系,每个时刻处于某一状态,所取得的观测值与状态相关。
HMM基于两个基本假设:
- 当前的状态只和前一状态有关
- 某个观测只和生成它的状态有关。
HMM广泛应用于数据科学和机器学习任务中,包括但不限于语音识别、图像分割、股市预测以及生物信息学等领域。在语音识别中,HMM被用于对语音信号的声学特征进行建模,以便识别单词和短语。在图像分割中,HMM则用于识别图像中的对象,通过分析形状、颜色和纹理等特征。此外,HMM还用于模拟生物序列,如蛋白质和DNA序列。
HMM模型比基础的马尔可夫模型多了一个观测概率分布,其由初始概率分布、状态转移概率分布和观测概率分布确定,因此可以用三元符号表示。
- 初始概率分布($\pi$):表示最初处于各个状态的概率集合;
- 状态转移概率矩阵(A):表示从一个隐藏状态转移到另一个隐藏状态的概率;
- 观测概率矩阵(B):表示在给定观测状态下各隐藏状态的概率。
举个例子:还是刚在的天气案例,只是难度加大了,现在这个天气情况我们没有办法去直接观测,是一个隐藏状态,我们只能够直接观测到海藻的状态【Dry(干燥), Dryish(稍干), Damp(湿润), Soggy(浸水)】,而海藻的状态跟天气有一定的关系。
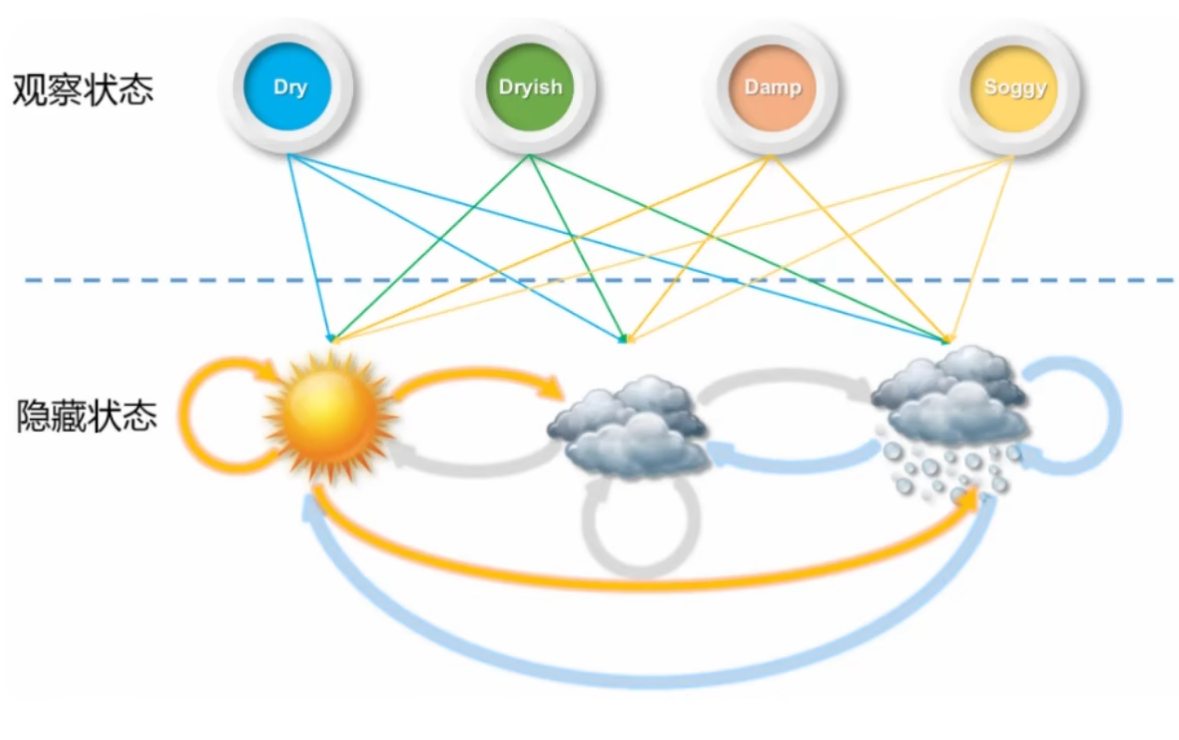
这个时候和前面的基础的马尔可夫模型案例相比,还需要已知一个观测概率矩阵,也就是海藻的状态和天气之间具体有什么关联:
观测概率矩阵:
现在已知观测到未来三天的海藻状态为[Dry, Dryish, Dry],求最有可能的隐藏状态序列.
求解方法:维特比算法
1 | # 定义转移概率矩阵 |
1 | # 时刻1初始的隐藏状态概率为pi |
array([0.48 , 0.025, 0.005])
1 | # 第二天隐藏状态矩阵 |
array([0.0495 , 0.061875, 0.02475 ])
1 | # 第三天隐藏状态矩阵 |
array([0.02784375, 0.01160156, 0.00232031])
1 | # 汇总所有时刻的隐藏状态矩阵 |
array([[0.48 , 0.0495 , 0.02784375],
[0.025 , 0.061875 , 0.01160156],
[0.005 , 0.02475 , 0.00232031]])
1 | # 求出最大的概率组合 |
array([0, 1, 0], dtype=int64)
定义维特比算法求解函数
求解任务模式
已知:
- HMM模型的完整参数(转移概率矩阵A,观测状态矩阵B,初始概率矩阵pi)
求解: - 指定观测状态序列$O_i$下隐藏状态序列$I_j$出现概率最大的结果。
1 | def viterbi(A, B, pi, O): |
1 | viterbi(A, B, pi, O) |
array([0, 1, 0], dtype=int64)
使用监督学习训练HMM
将问题抽象出来即:已知观测状态序列(O)和隐藏状态序列(I),如何求出对应的HMM模型($\lambda\{\pi, A, B\}$)?
生成数据
为了简单起见,直接使用前面的HMM模型训练数据。
1 | def random_data(T): |
1 | random_data(10) |
([2, 1, 2, 1, 0, 0, 2, 1, 1, 2], [3, 0, 3, 0, 0, 1, 3, 0, 0, 2])
1 | # 定义数据量 |
初始化参数
1 | # 计算观测状态O_num和隐藏状态i=I_num |
开始计算
1 | # 计算初始状态 |
array([0.807, 0.098, 0.095])
1 | # 计算状态转移矩阵 |
array([[0.50096283, 0.37414269, 0.12489448],
[0.25011337, 0.25012538, 0.49976125],
[0.25004353, 0.37500375, 0.37495272]])
1 | # 计算观测矩阵 |
array([[0.59910993, 0.19991908, 0.15019779, 0.0507732 ],
[0.24941232, 0.25002477, 0.25091343, 0.24964949],
[0.04929884, 0.10106142, 0.34963224, 0.5000075 ]])
计算成功!经过和原始数据对比发现相似度很高。
使用HMM实现中文分词任务
在中文分词任务中,观测状态为字,隐藏状态为每个字为BEMS中的一个状态。
- B:词语开始
- E:词语结束
- M:词语中间字
- S:孤立的单个字称为一个词语
1 | from tqdm import tqdm |
读取数据
1 | with open('../data/icwb2-data/training/pku_training.utf8', 'r', encoding='UTF-8') as f: |
19054
处理数据
按照BEMS方式标记数据
1 | I = [] # 存储隐藏状态 |
训练HMM模型
现在和前面的监督学习训练HMM一样,已知观测状态链和隐藏状态链。同样可以求出对应的HMM模型。
1 | # 计算观测状态O_num和隐藏状态i=I_num |
1 | # 计算初始状态 |
array([0.63456492, 0. , 0. , 0.36543508])
1 | # 计算状态转移矩阵 |
100%|██████████████████████████████████████████████████████████████████████████| 19054/19054 [00:05<00:00, 3230.11it/s]
array([[0. , 0.49242151, 0. , 0.50757849],
[0.85322422, 0. , 0.14677578, 0. ],
[0.6543287 , 0. , 0.3456713 , 0. ],
[0. , 0.57792637, 0. , 0.42207363]])
1 | # 计算观测矩阵 |
100%|██████████████████████████████████████████████████████████████████████████████| 1000/1000 [43:43<00:00, 2.62s/it]
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
这里可以自己手动去修改对数据量的循环
[:1000]如果将这个内容删除,则会对所有样本进行训练,预计消耗时间14h。
1 | # 存储中间结果 |
使用HMM进行分词
前面我们已经将HMM模型训练完毕,接下来使用训练好的HMM模型,对指定序列进行分词。
这里就可以使用到维特比算法,找到指定观测序列最大概率的隐藏序列。
1 | test_text = '我们即将以丰收的喜悦送走牛年,以昂扬的斗志迎来虎年。我们伟大祖国在新的一年,将是充满生机、充满希望的一年。' |
1 | # 将指定文本转化为观测序列 |
53
1 | # 使用维特比算法求解最大概率的隐藏序列结果 |
1 | # 将分词结果还原到句子中,在所有的1和3后面加上| |
'我们|即将|以|丰收的|喜悦|送|走|牛年|,|以|昂扬|的|斗|志|迎来|虎年|。|我们|伟大祖国|在|新的|一|年|,|将|是|充满|生机、|充满|希望|的|一|年|。|'
编写成函数
1 | def cut(string, A=None, B=None, pi=None, sep=' ', model_params_path=None): |
使用100个样本的训练参数
1 | cut('台湾是中国领土不可分割的一部分', sep='|', model_params_path='hmm_model_params_epoch100.npz') |
'台湾|是|中国|领土|不|可分|割|的|一部|分|'
使用1000个样本的训练参数
1 | cut('台湾是中国领土不可分割的一部分', sep='|', model_params_path='hmm_model_params_epoch1000.npz') |
'台湾|是|中国|领土不|可分割的|一|部|分'
由于模型训练比较耗时,这里我使用了1000个样本进行训练时,消耗的时间是43分钟,训练的CPU是Inter i7-11th,大家要想得到更好的效果可以自行尝试增加训练样本,如果将所有样本全部放入模型中进行训练可能会消耗14个小时左右。