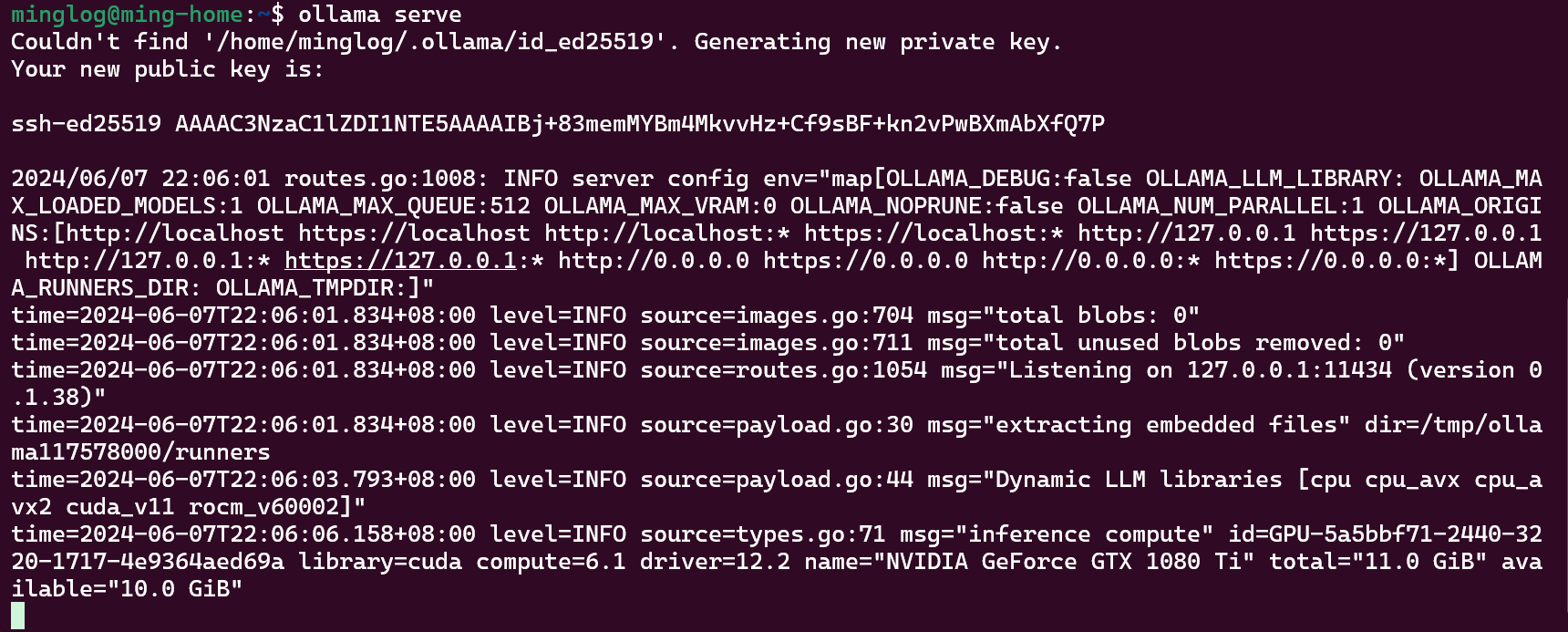
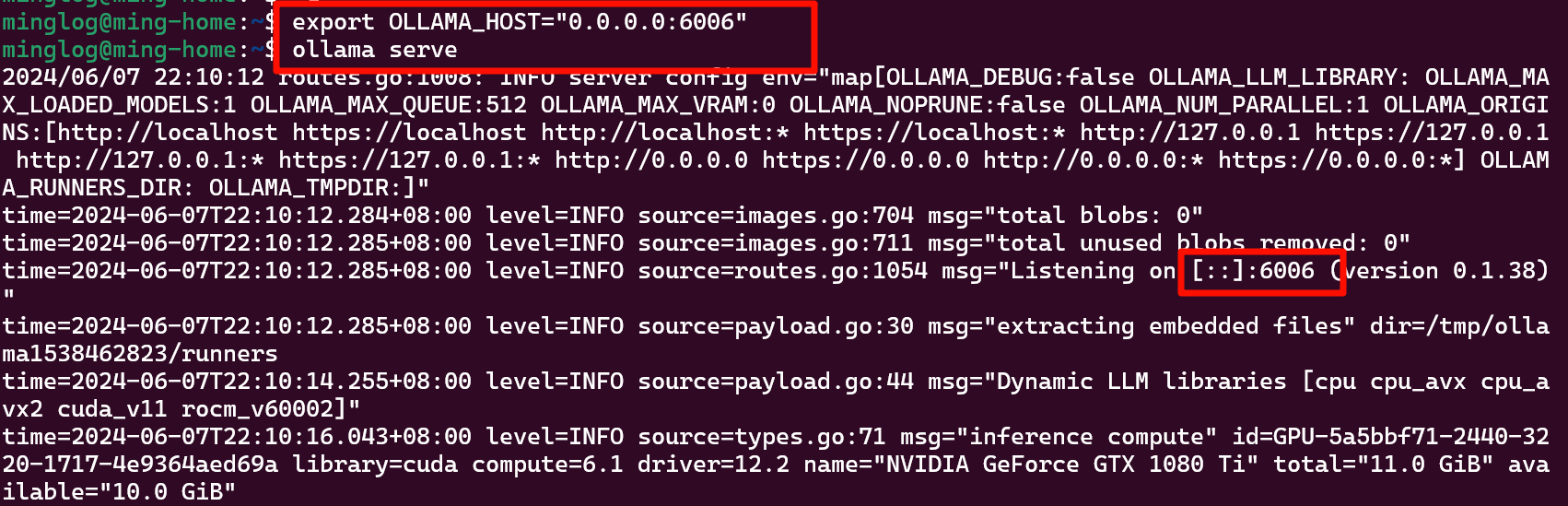
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| import requests
import json
class OllamaChat():
def __init__(self, system_message="你的名字叫做minglog,是一个由骆明开发的大语言模型。", url="http://localhost:11434/api/chat", model_name="qwen:7b"):
"""
url: ChatModel API. Default is Local Ollama
# url = "http://localhost:6006/api/chat" # AutoDL
# url = "http://localhost:11434/api/chat" # localhost
model_name: ModelName.
Default is Qwen:7b
"""
self.url = url
self.model_name = model_name
self.system_message = {
"role": "system",
"content": f"""{system_message}"""
}
def ouput_response(self, response, stream=False, is_chat=True):
if stream:
return_text = ''
for chunk in response.iter_content(chunk_size=None):
if chunk:
if is_chat:
text = json.loads(chunk.decode('utf-8'))['message']['content']
else:
text = json.loads(chunk.decode('utf-8'))['response']
return_text += text
print(text, end='', flush=True)
else:
if is_chat:
return_text = ''.join([json.loads(response)['message']['content'] for response in response.text.split('\n') if len(response) != 0])
else:
return_text = ''.join([json.loads(response)['response'] for response in response.text.split('\n') if len(response) != 0])
return return_text
def chat(self, prompt, message=[], stream=False, temperature=None):
"""
prompt: Type Str, User input prompt words.
messages: Type List, Dialogue History. role in [system, user, assistant]
stream: Type Boolean, Is it streaming output. if `True` streaming output, otherwise not streaming output.
"""
if not message:
message.append(self.system_message)
message.append({"role": "user", "content": prompt})
data = {
"model": self.model_name,
"messages": message
}
if temperature is not None:
data["options"] = {
"temperature": temperature
}
headers = {
"Content-Type": "application/json"
}
responses = requests.post(self.url, headers=headers, json=data, stream=stream)
return_text = self.ouput_response(responses, stream)
message.append({"role": "assistant", "content": return_text})
return return_text, message
def generate(self, prompt, stream=False, temperature=None):
generate_url = self.url.replace('chat', 'generate')
data = {
"model": self.model_name,
"prompt": prompt
}
if temperature is not None:
data["options"] = {
"temperature": temperature
}
headers = {
"Content-Type": "application/json"
}
responses = requests.post(generate_url, headers=headers, json=data, stream=stream)
return_text = self.ouput_response(responses, stream, is_chat=False)
return return_text
if __name__ == "__main__":
Chat = OllamaChat()
return_text = Chat.generate('你是谁。', stream=True)
print(return_text)
|