读取数据 1 import SimpleITK as sitk
1 2 3 import matplotlib.pyplot as pltimport numpy as npimport cv2
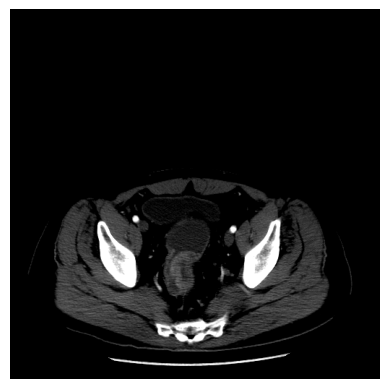
读取CT影像照片DCM文件 1 dcm_path = 'data/10009.dcm'
1 2 3 img = sitk.ReadImage(dcm_path) img = sitk.GetArrayFromImage(img) img = img.squeeze()
1 2 3 img[img < 0 ] = 0 img[img > 255 ] = 255 img = np.array(img, dtype=np.uint8)
1 2 3 4 plt.imshow(img, cmap='gray' ) plt.axis('off' ) plt.show()
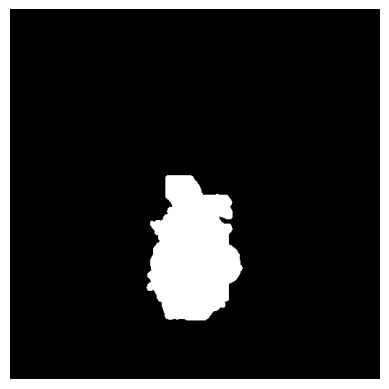
读取CT影像照片对应的掩膜图片 1 mask_path = 'data/10009_mask.png'
1 mask_img = cv2.imread(mask_path)[:, :, 0 ]
1 2 3 4 plt.imshow(mask_img, cmap='gray' ) plt.axis('off' ) plt.show()
在该任务中,我们将图像分割任务分为两个子任务。
首先去建立一个2分类模型,去判断每个CT影像图片中是否有肿瘤。
对有肿瘤的图片搭建图像分割模型,分割出肿瘤区域。
要实现这些任务,由于原始的数据量太大,并且图片像素很高,所以在进行建模前需要做大量的数据预处理工作。
要实现2分类任务,首先去要去构建标签,在构建标签前,还需要对原始的数据进行采样,保证正负样本的类别均衡。
正样本,在掩膜图片中存在肿瘤区域,也就是将掩膜图片中的像素进行求和后不为0;反之,则为负样本。
现有图片像素过大,但是经过观察发现,图片中的肿瘤区域都是集中在图像中部。
批量读取图片 读取掩膜图片 1 2 from glob import globfrom tqdm import tqdm
1 2 3 mask_imgs_path = glob('data/dcmData1/*/*/*.png' ) dcm_imgs_path = glob('data/dcmData1/*/*/*.dcm' )
1 2 3 4 5 mask_imgs = [] for mask_path in tqdm(mask_imgs_path): mask_img = cv2.imread(mask_path)[:, :, 0 ] mask_imgs.append(mask_img) mask_imgs = np.stack(mask_imgs, axis=0 )
100%|█████████████████████████████████████████████████████████████████████████████| 6248/6248 [00:06<00:00, 908.96it/s]
切分出肿瘤区域 1 2 3 4 5 sum_img = np.zeros((512 , 512 )) for mask_img in mask_imgs: sum_img += mask_img sum_img[sum_img != 0 ] = 255
1 2 3 4 plt.imshow(sum_img, cmap='gray' ) plt.axis('off' ) plt.show()
1 2 3 4 row_min, row_max = np.arange(512 )[sum_img.sum (axis=1 ) != 0 ][[0 , -1 ]] col_min, col_max = np.arange(512 )[sum_img.sum (axis=0 ) != 0 ][[0 , -1 ]] print (f"肿瘤区域位置为:[{row_min} :{row_max} , {col_min} :{col_max} ]" )
肿瘤区域位置为:[230:430, 189:321]
为了后续模型搭建方便,在此将数据肿瘤区域切分位置定位为208x144大小,必须为16的倍数
区域固定为:[226:434, 183:327]
1 2 mask_imgs = np.stack([mask_img[226 :434 , 183 :327 ] for mask_img in mask_imgs], axis=0 )
(6248, 208, 144)
构建正负样本 1 2 3 4 5 labels = [] for mask_img in mask_imgs: label = 0 if mask_img.sum () == 0 else 1 labels.append(label) labels = np.array(labels)
1 2 3 from collections import CounterCounter(labels)
Counter({0: 4453, 1: 1795})
可以看到,负样本占了绝大部分,正负样本分布不均衡。
1 2 3 4 5 index_1 = np.arange(len (labels))[labels == 1 ] index_0 = np.random.choice(np.arange(len (labels))[labels == 0 ], size=len (index_1)) index = np.concatenate([index_0, index_1])
读取所有图片和标签 1 2 3 4 5 6 7 8 9 10 11 labels_sample = labels[index] masks_sample = mask_imgs[index] imgs_sample = [] for i in tqdm(index): dcm_path = dcm_imgs_path[i] img = sitk.ReadImage(dcm_path) img_array = sitk.GetArrayFromImage(img) img_array = img_array.squeeze() img_array = img_array[226 :434 , 183 :327 ] imgs_sample.append(img_array) imgs_sample = np.stack(imgs_sample, axis=0 )
100%|█████████████████████████████████████████████████████████████████████████████| 3590/3590 [00:25<00:00, 140.12it/s]
1 2 3 4 plt.imshow(imgs_sample[2000 ], cmap='gray' ) plt.axis('off' ) plt.show()
1 2 3 4 plt.imshow(masks_sample[2000 ], cmap='gray' ) plt.axis('off' ) plt.show()
1
1 np.savez('data/dcmData.npz' , imgs_sample=imgs_sample, masks_sample=masks_sample, labels_sample=labels_sample)
切分数据集 1 2 3 4 data = np.load('data/dcmData.npz' ) imgs_sample = data['imgs_sample' ] masks_sample = data['masks_sample' ] labels_sample = data['labels_sample' ]
1 from sklearn.model_selection import train_test_split
1 train_imgs, test_imgs, train_masks, test_masks, train_labels, test_labels = train_test_split(imgs_sample, masks_sample, labels_sample, test_size=0.2 , random_state=2024 , shuffle=True )
1 2 print ('Train:' , train_imgs.shape)print ('Test:' , test_imgs.shape)
Train: (2872, 208, 144)
Test: (718, 208, 144)
判断CT图片中是否有肿瘤 1 2 3 4 5 6 7 import torchimport numpy as npimport torch.nn as nnimport torch.nn.functional as Ffrom torchvision.transforms import v2 as transformsfrom torch.utils.data import DataLoader, Dataset
自定义Dataset 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class CTDataset1 (Dataset ): def __init__ (self, imgs, labels, transforms=None ): super (CTDataset1, self).__init__() self.imgs = np.expand_dims(imgs, -1 ) self.labels = labels self.transforms = transforms def __len__ (self ): return len (self.imgs) def __getitem__ (self, idx ): img = self.imgs[idx].copy() img[img < 0 ] = 0 img[img > 255 ] = 255 img = np.array(img, dtype=np.uint8) label = int (self.labels[idx]) if self.transforms: img = self.transforms(img) return img, label
1 2 3 4 5 6 7 8 9 10 11 train_dataset = CTDataset1(train_imgs, train_labels, transforms=transforms.Compose([ transforms.ToImage(), transforms.ToDtype(torch.float32, scale=True ) ])) test_dataset = CTDataset1(test_imgs, test_labels, transforms=transforms.Compose([ transforms.ToImage(), transforms.ToDtype(torch.float32, scale=True ) ]))
定义模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class CNNModel (nn.Module): def __init__ (self, label_nums=2 ): super (CNNModel, self).__init__() self.conv1 = nn.Conv2d(in_channels=1 , out_channels=16 , kernel_size=(3 , 3 ), padding=1 ) self.batch_norm1 = nn.BatchNorm2d(16 ) self.pool = nn.MaxPool2d(kernel_size=2 ) self.conv2 = nn.Conv2d(in_channels=16 , out_channels=32 , kernel_size=(3 , 3 ), padding=1 ) self.batch_norm2 = nn.BatchNorm2d(32 ) self.conv3 = nn.Conv2d(in_channels=32 , out_channels=8 , kernel_size=(3 , 3 ), padding=1 ) self.batch_norm3 = nn.BatchNorm2d(8 ) self.flatten = nn.Flatten() self.relu = nn.ReLU() self.fc1 = nn.Linear(3744 , 512 ) self.fc2 = nn.Linear(512 , label_nums) self.dropout = nn.Dropout(0.5 ) def forward (self, x ): x = self.batch_norm1(self.conv1(x)) x = self.relu(self.pool(x)) x = self.batch_norm2(self.conv2(x)) x = self.relu(self.pool(x)) x = self.batch_norm3(self.conv3(x)) x = self.relu(self.pool(x)) x = self.flatten(x) x = self.relu(self.fc1(x)) x = self.dropout(x) x = self.fc2(x) return x
1 2 3 4 from torchsummary.torchsummary import summarycnn_model = CNNModel().to('cuda' ) summary(cnn_model, input_size=(1 , 208 , 144 ))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 208, 144] 160
BatchNorm2d-2 [-1, 16, 208, 144] 32
MaxPool2d-3 [-1, 16, 104, 72] 0
ReLU-4 [-1, 16, 104, 72] 0
Conv2d-5 [-1, 32, 104, 72] 4,640
BatchNorm2d-6 [-1, 32, 104, 72] 64
MaxPool2d-7 [-1, 32, 52, 36] 0
ReLU-8 [-1, 32, 52, 36] 0
Conv2d-9 [-1, 8, 52, 36] 2,312
BatchNorm2d-10 [-1, 8, 52, 36] 16
MaxPool2d-11 [-1, 8, 26, 18] 0
ReLU-12 [-1, 8, 26, 18] 0
Flatten-13 [-1, 3744] 0
Linear-14 [-1, 512] 1,917,440
ReLU-15 [-1, 512] 0
Dropout-16 [-1, 512] 0
Linear-17 [-1, 2] 1,026
================================================================
Total params: 1,925,690
Trainable params: 1,925,690
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.11
Forward/backward pass size (MB): 14.04
Params size (MB): 7.35
Estimated Total Size (MB): 21.50
----------------------------------------------------------------
定义损失函数 1 criterion = nn.CrossEntropyLoss()
定义优化器 1 optimizer = torch.optim.Adam(cnn_model.parameters())
模型训练 编写训练函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def train (model, device, train_loader, criterion, optimizer, epoch ): model.train() total = 0 for batch_idx, (data, target) in enumerate (train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() optimizer.step() total += len (data) progress = math.ceil(batch_idx / len (train_loader) * 50 ) print ("\rTrain epoch %d: %d/%d, [%-51s] %d%%" % (epoch, total, len (train_loader.dataset), '-' * progress + '>' , progress * 2 ), end='' )
编写测试函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import mathdef test (model, device, test_loader, criterion ): model.eval () test_loss = 0 correct = 0 with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += criterion(output, target).item() pred = output.argmax(dim=1 , keepdim=True ) correct += pred.eq(target.view_as(pred)).sum ().item() test_loss /= len (test_loader.dataset) print ('\nTest: average loss: {:.4f}, accuracy: {}/{} ({:.0f}%)' .format ( test_loss, correct, len (test_loader.dataset), 100. * correct / len (test_loader.dataset)))
训练主函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 epochs = 10 batch_size = 256 torch.manual_seed(2024 ) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True ) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True ) for epoch in range (1 , epochs+1 ): train(cnn_model, device, train_loader, criterion, optimizer, epoch) test(cnn_model, device, test_loader, criterion) print ('--------------------------' )
Train epoch 1: 2872/2872, [----------------------------------------------> ] 92%
Test: average loss: 0.0027, accuracy: 411/718 (57%)
--------------------------
Train epoch 2: 2872/2872, [----------------------------------------------> ] 92%
Test: average loss: 0.0025, accuracy: 437/718 (61%)
--------------------------
Train epoch 3: 2872/2872, [----------------------------------------------> ] 92%
Test: average loss: 0.0021, accuracy: 516/718 (72%)
--------------------------
Train epoch 4: 2872/2872, [----------------------------------------------> ] 92%
Test: average loss: 0.0016, accuracy: 574/718 (80%)
--------------------------
Train epoch 5: 2872/2872, [----------------------------------------------> ] 92%
Test: average loss: 0.0013, accuracy: 622/718 (87%)
--------------------------
Train epoch 6: 2872/2872, [----------------------------------------------> ] 92%
Test: average loss: 0.0011, accuracy: 647/718 (90%)
--------------------------
Train epoch 7: 2872/2872, [----------------------------------------------> ] 92%
Test: average loss: 0.0009, accuracy: 653/718 (91%)
--------------------------
Train epoch 8: 2872/2872, [----------------------------------------------> ] 92%
Test: average loss: 0.0009, accuracy: 652/718 (91%)
--------------------------
Train epoch 9: 2872/2872, [----------------------------------------------> ] 92%
Test: average loss: 0.0009, accuracy: 658/718 (92%)
--------------------------
Train epoch 10: 2872/2872, [----------------------------------------------> ] 92%
Test: average loss: 0.0008, accuracy: 661/718 (92%)
--------------------------
模型验证 1 2 3 4 5 6 pred_index = 37 pred = cnn_model(test_dataset[pred_index][0 ].unsqueeze(0 ).to('cuda' )).argmax() plt.imshow(test_masks[pred_index]) plt.title(f'Pred: {pred.item()} ' ) plt.axis('off' ) plt.show()
1 torch.save(cnn_model.state_dict(), 'cnn_model.pth' )
在判断有肿瘤区域的前提下,定位肿瘤区域的具体位置 1 2 3 4 5 import numpy as npdata = np.load('data/dcmData.npz' ) imgs_sample = data['imgs_sample' ] masks_sample = data['masks_sample' ] labels_sample = data['labels_sample' ]
1 2 3 imgs_sample = imgs_sample[labels_sample == 1 ] masks_sample = masks_sample[labels_sample == 1 ]
1 2 3 4 from sklearn.model_selection import train_test_splittrain_imgs, test_imgs, train_masks, test_masks = train_test_split(imgs_sample, masks_sample, test_size=0.2 , random_state=2024 , shuffle=True )
1 2 print ('Train:' , train_imgs.shape)print ('Test:' , test_imgs.shape)
Train: (1436, 208, 144)
Test: (359, 208, 144)
自定义Dataset 1 2 3 4 5 6 7 import torchimport numpy as npimport torch.nn as nnimport torch.nn.functional as Ffrom torchvision.transforms import v2 as transformsfrom torch.utils.data import DataLoader, Dataset
D:\ProgramSoftware\Python\Miniconda3\envs\pytorch\lib\site-packages\transformers\utils\generic.py:441: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.
_torch_pytree._register_pytree_node(
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class CTDataset2 (Dataset ): def __init__ (self, imgs, masks, transforms=None ): super (CTDataset2, self).__init__() self.imgs = np.expand_dims(imgs, -1 ) self.masks = masks self.transforms = transforms def __len__ (self ): return len (self.imgs) def __getitem__ (self, idx ): img = self.imgs[idx].copy() img[img < 0 ] = 0 img[img > 255 ] = 255 img = np.array(img, dtype=np.uint8) if self.transforms: img = self.transforms(img) mask = self.masks[idx].copy() mask[mask == 255 ] = 1 mask = torch.LongTensor(mask) return img, mask
1 2 3 4 5 6 7 8 9 10 11 train_dataset2 = CTDataset2(train_imgs, train_masks, transforms=transforms.Compose([ transforms.ToImage(), transforms.ToDtype(torch.float32, scale=True ) ])) test_dataset2 = CTDataset2(test_imgs, test_masks, transforms=transforms.Compose([ transforms.ToImage(), transforms.ToDtype(torch.float32, scale=True ) ]))
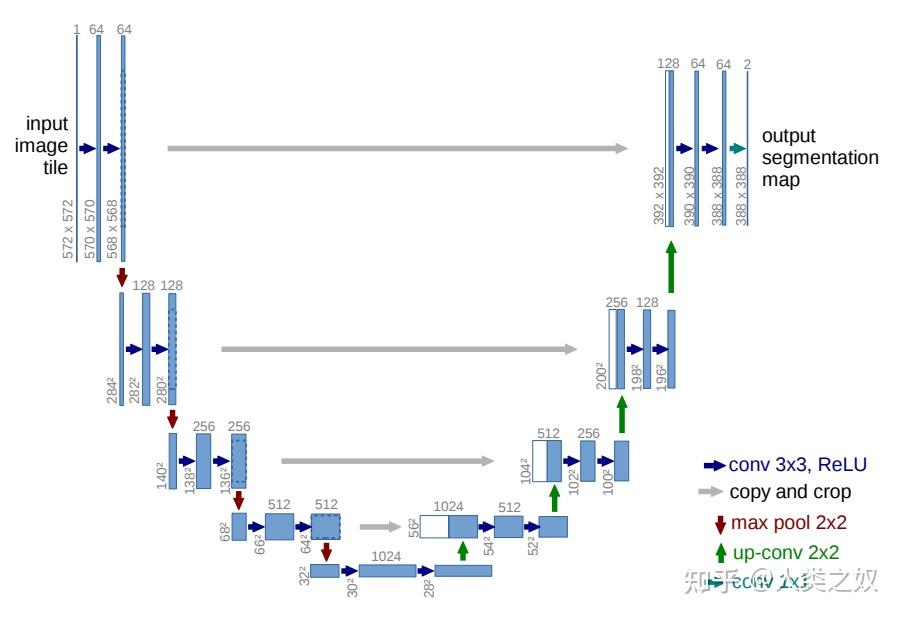
定义模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class DoubleConv (nn.Module): def __init__ (self, in_ch, out_ch ): super (DoubleConv, self).__init__() self.conv = nn.Sequential( nn.Conv2d(in_ch, out_ch, kernel_size=3 , stride=1 , padding=1 , bias=True ), nn.BatchNorm2d(out_ch), nn.ReLU(inplace=True ), nn.Conv2d(out_ch, out_ch, kernel_size=3 , stride=1 , padding=1 , bias=True ), nn.BatchNorm2d(out_ch), nn.ReLU(inplace=True )) def forward (self, x ): return self.conv(x)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 class Unet (nn.Module): def __init__ (self, in_ch, out_ch ): super (Unet, self).__init__() self.conv1 = DoubleConv(in_ch, 64 ) self.max_pool = nn.MaxPool2d(2 ) self.conv2 = DoubleConv(64 , 128 ) self.conv3 = DoubleConv(128 , 256 ) self.conv4 = DoubleConv(256 , 512 ) self.conv5 = DoubleConv(512 , 1024 ) self.up6 = nn.ConvTranspose2d(1024 , 512 , 2 , stride=2 ) self.conv6 = DoubleConv(1024 , 512 ) self.up7 = nn.ConvTranspose2d(512 , 256 , 2 , stride=2 ) self.conv7 = DoubleConv(512 , 256 ) self.up8 = nn.ConvTranspose2d(256 , 128 , 2 , stride=2 ) self.conv8 = DoubleConv(256 , 128 ) self.up9 = nn.ConvTranspose2d(128 , 64 , 2 , stride=2 ) self.conv9 = DoubleConv(128 , 64 ) self.conv10 = nn.Conv2d(64 , out_ch, 1 ) def forward (self, x ): c1=self.conv1(x) p1=self.max_pool(c1) c2=self.conv2(p1) p2=self.max_pool(c2) c3=self.conv3(p2) p3=self.max_pool(c3) c4=self.conv4(p3) p4=self.max_pool(c4) c5=self.conv5(p4) up_6= self.up6(c5) merge6 = torch.cat([up_6, c4], dim=1 ) c6=self.conv6(merge6) up_7=self.up7(c6) merge7 = torch.cat([up_7, c3], dim=1 ) c7=self.conv7(merge7) up_8=self.up8(c7) merge8 = torch.cat([up_8, c2], dim=1 ) c8=self.conv8(merge8) up_9=self.up9(c8) merge9=torch.cat([up_9,c1],dim=1 ) c9=self.conv9(merge9) c10=F.sigmoid(self.conv10(c9)) return c10
1 2 3 from torchsummary.torchsummary import summaryunet = Unet(1 , 2 ).to('cuda' ) summary(unet, input_size=(1 , 208 , 144 ))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 208, 144] 640
BatchNorm2d-2 [-1, 64, 208, 144] 128
ReLU-3 [-1, 64, 208, 144] 0
Conv2d-4 [-1, 64, 208, 144] 36,928
BatchNorm2d-5 [-1, 64, 208, 144] 128
ReLU-6 [-1, 64, 208, 144] 0
DoubleConv-7 [-1, 64, 208, 144] 0
MaxPool2d-8 [-1, 64, 104, 72] 0
Conv2d-9 [-1, 128, 104, 72] 73,856
BatchNorm2d-10 [-1, 128, 104, 72] 256
ReLU-11 [-1, 128, 104, 72] 0
Conv2d-12 [-1, 128, 104, 72] 147,584
BatchNorm2d-13 [-1, 128, 104, 72] 256
ReLU-14 [-1, 128, 104, 72] 0
DoubleConv-15 [-1, 128, 104, 72] 0
MaxPool2d-16 [-1, 128, 52, 36] 0
Conv2d-17 [-1, 256, 52, 36] 295,168
BatchNorm2d-18 [-1, 256, 52, 36] 512
ReLU-19 [-1, 256, 52, 36] 0
Conv2d-20 [-1, 256, 52, 36] 590,080
BatchNorm2d-21 [-1, 256, 52, 36] 512
ReLU-22 [-1, 256, 52, 36] 0
DoubleConv-23 [-1, 256, 52, 36] 0
MaxPool2d-24 [-1, 256, 26, 18] 0
Conv2d-25 [-1, 512, 26, 18] 1,180,160
BatchNorm2d-26 [-1, 512, 26, 18] 1,024
ReLU-27 [-1, 512, 26, 18] 0
Conv2d-28 [-1, 512, 26, 18] 2,359,808
BatchNorm2d-29 [-1, 512, 26, 18] 1,024
ReLU-30 [-1, 512, 26, 18] 0
DoubleConv-31 [-1, 512, 26, 18] 0
MaxPool2d-32 [-1, 512, 13, 9] 0
Conv2d-33 [-1, 1024, 13, 9] 4,719,616
BatchNorm2d-34 [-1, 1024, 13, 9] 2,048
ReLU-35 [-1, 1024, 13, 9] 0
Conv2d-36 [-1, 1024, 13, 9] 9,438,208
BatchNorm2d-37 [-1, 1024, 13, 9] 2,048
ReLU-38 [-1, 1024, 13, 9] 0
DoubleConv-39 [-1, 1024, 13, 9] 0
ConvTranspose2d-40 [-1, 512, 26, 18] 2,097,664
Conv2d-41 [-1, 512, 26, 18] 4,719,104
BatchNorm2d-42 [-1, 512, 26, 18] 1,024
ReLU-43 [-1, 512, 26, 18] 0
Conv2d-44 [-1, 512, 26, 18] 2,359,808
BatchNorm2d-45 [-1, 512, 26, 18] 1,024
ReLU-46 [-1, 512, 26, 18] 0
DoubleConv-47 [-1, 512, 26, 18] 0
ConvTranspose2d-48 [-1, 256, 52, 36] 524,544
Conv2d-49 [-1, 256, 52, 36] 1,179,904
BatchNorm2d-50 [-1, 256, 52, 36] 512
ReLU-51 [-1, 256, 52, 36] 0
Conv2d-52 [-1, 256, 52, 36] 590,080
BatchNorm2d-53 [-1, 256, 52, 36] 512
ReLU-54 [-1, 256, 52, 36] 0
DoubleConv-55 [-1, 256, 52, 36] 0
ConvTranspose2d-56 [-1, 128, 104, 72] 131,200
Conv2d-57 [-1, 128, 104, 72] 295,040
BatchNorm2d-58 [-1, 128, 104, 72] 256
ReLU-59 [-1, 128, 104, 72] 0
Conv2d-60 [-1, 128, 104, 72] 147,584
BatchNorm2d-61 [-1, 128, 104, 72] 256
ReLU-62 [-1, 128, 104, 72] 0
DoubleConv-63 [-1, 128, 104, 72] 0
ConvTranspose2d-64 [-1, 64, 208, 144] 32,832
Conv2d-65 [-1, 64, 208, 144] 73,792
BatchNorm2d-66 [-1, 64, 208, 144] 128
ReLU-67 [-1, 64, 208, 144] 0
Conv2d-68 [-1, 64, 208, 144] 36,928
BatchNorm2d-69 [-1, 64, 208, 144] 128
ReLU-70 [-1, 64, 208, 144] 0
DoubleConv-71 [-1, 64, 208, 144] 0
Conv2d-72 [-1, 2, 208, 144] 130
================================================================
Total params: 31,042,434
Trainable params: 31,042,434
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.11
Forward/backward pass size (MB): 425.04
Params size (MB): 118.42
Estimated Total Size (MB): 543.57
----------------------------------------------------------------
定义评价函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def dice_value (pred, target, smooth=1.0 ): """ 计算Dice。 Args: pred (torch.Tensor): 预测结果,形状为[B, C, H, W],其中C是类别数。 target (torch.Tensor): 真实标签,形状与pred相同。 smooth (float, optional): 平滑因子,用于防止除以零。默认为1.0。 Returns: torch.Tensor: Dice值。 """ iflat = (pred * target).sum (dim=[2 , 3 ]) + smooth tflat = target.sum (dim=[2 , 3 ]) + smooth pflat = pred.sum (dim=[2 , 3 ]) + smooth dice = 2. * iflat / (tflat + pflat) return dice
定义损失函数 1 criterion = nn.CrossEntropyLoss()
定义优化器 1 optimizer = torch.optim.Adam(unet.parameters())
模型训练 编写训练函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def train (model, device, train_loader, criterion, optimizer, epoch ): model.train() total = 0 for batch_idx, (data, target) in enumerate (train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() optimizer.step() total += len (data) progress = math.ceil(batch_idx / len (train_loader) * 50 ) print ("\rTrain epoch %d: %d/%d, [%-51s] %d%%" % (epoch, total, len (train_loader.dataset), '-' * progress + '>' , progress * 2 ), end='' )
编写测试函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import mathdef test (model, device, test_loader, criterion ): model.eval () test_loss = 0 dice = [] with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += criterion(output, target).item() pred = output.argmax(dim=1 , keepdim=True ) dice.append(dice_value(pred, target.unsqueeze(dim=1 )).mean().to('cpu' )) dice = np.mean(dice) print ('\nTest: average loss: {:.4f}, dice: {}' .format (test_loss, dice)) return pred, target
训练主函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 epochs = 50 batch_size = 16 torch.manual_seed(2024 ) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) train_loader = DataLoader(train_dataset2, batch_size=batch_size, shuffle=True ) test_loader = DataLoader(test_dataset2, batch_size=batch_size, shuffle=True ) for epoch in range (1 , epochs+1 ): train(unet, device, train_loader, criterion, optimizer, epoch) test(unet, device, test_loader, criterion) print ('--------------------------' )
Train epoch 1: 1436/1436, [-------------------------------------------------->] 100%
D:\ProgramSoftware\Python\Miniconda3\envs\pytorch\lib\site-packages\torch\nn\modules\conv.py:456: UserWarning: Plan failed with a cudnnException: CUDNN_BACKEND_EXECUTION_PLAN_DESCRIPTOR: cudnnFinalize Descriptor Failed cudnn_status: CUDNN_STATUS_NOT_SUPPORTED (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\cudnn\Conv_v8.cpp:919.)
return F.conv2d(input, weight, bias, self.stride,
1 torch.save(unet.state_dict(), 'unet_model.pth' )
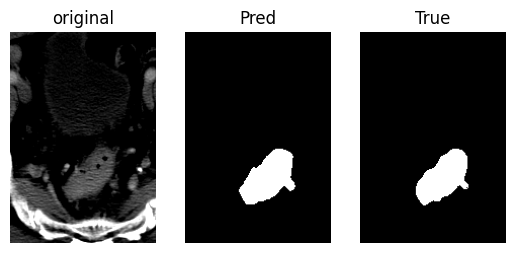
模型测试 1 2 3 4 index = 31 ct_img = test_dataset2[index][0 ].unsqueeze(0 ).to('cuda' ) ct_mask = test_dataset2[index][1 ] pred = unet(ct_img).argmax(dim=1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import matplotlib.pyplot as pltplt.subplot(131 ) plt.imshow(ct_img[0 ][0 ].to('cpu' ), cmap='gray' ) plt.title('original' ) plt.axis('off' ) plt.subplot(132 ) plt.imshow(pred[0 ].to('cpu' ), cmap='gray' ) plt.title('Pred' ) plt.axis('off' ) plt.subplot(133 ) plt.imshow(ct_mask.to('cpu' ), cmap='gray' ) plt.title('True' ) plt.axis('off' ) plt.show()