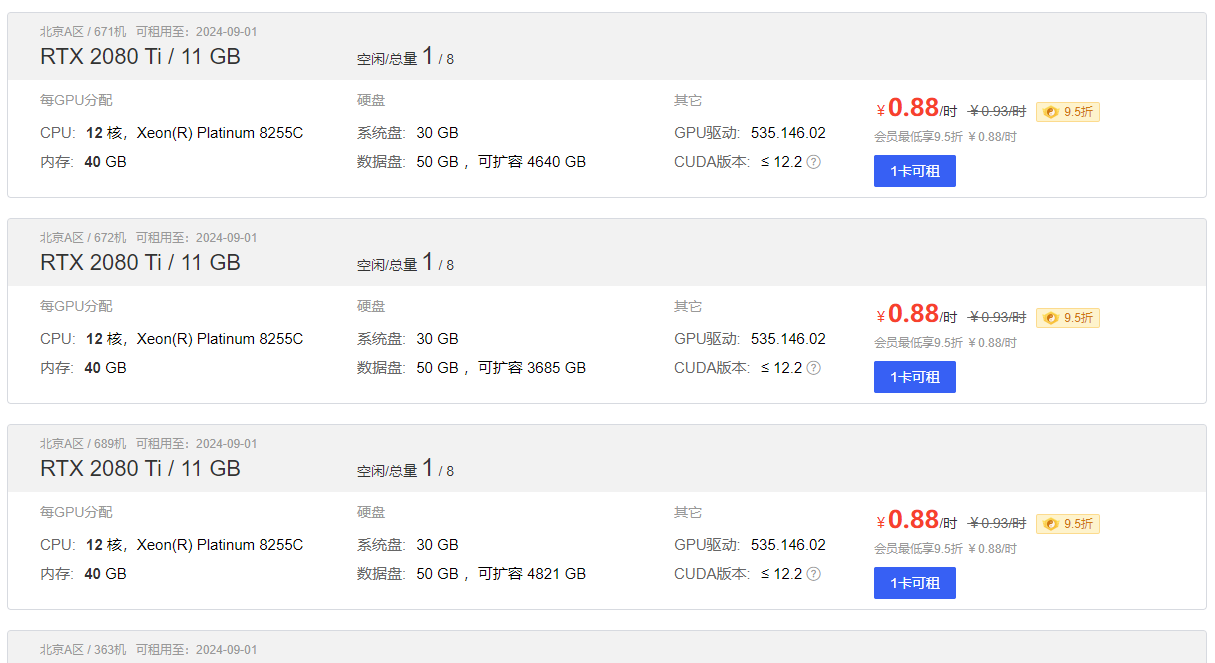
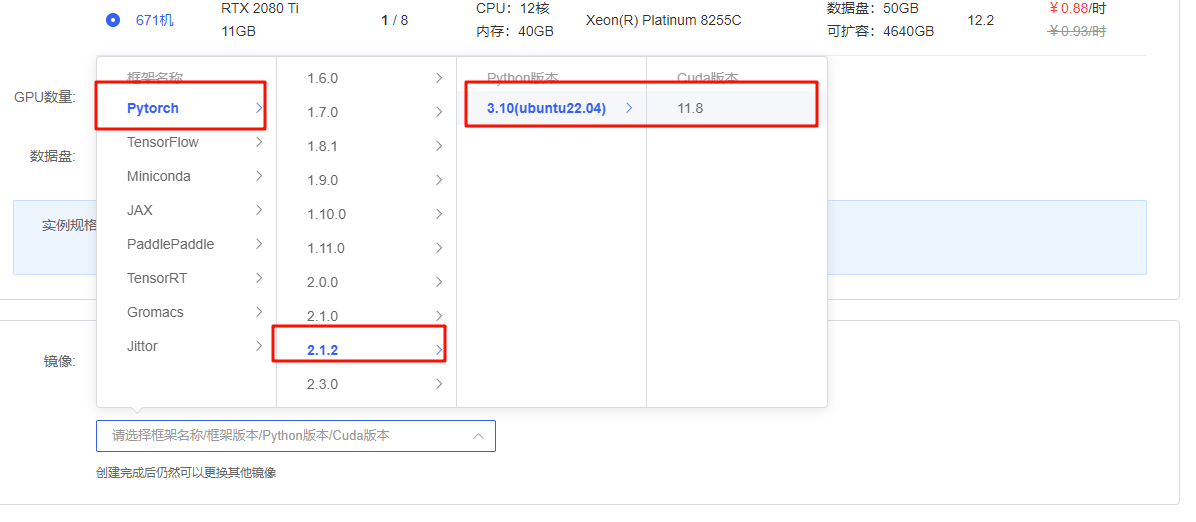
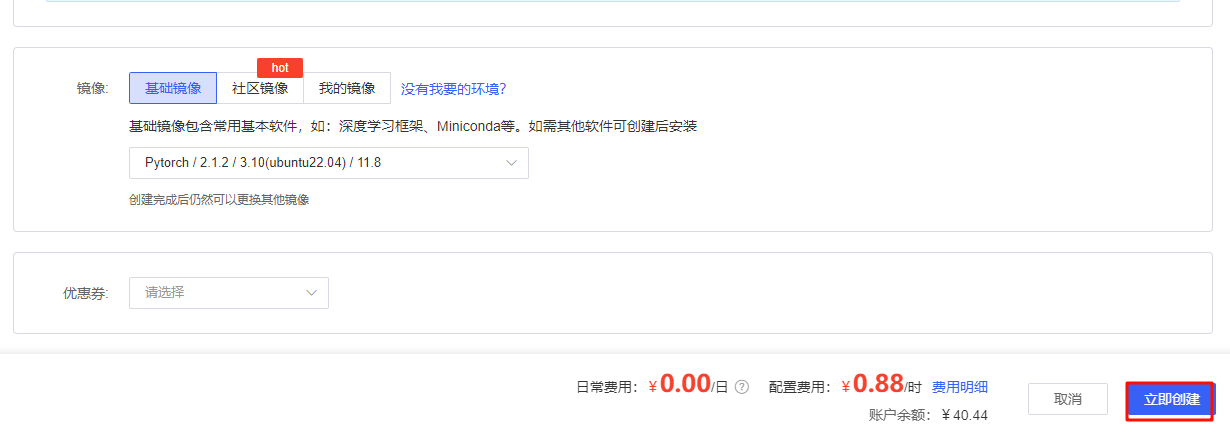
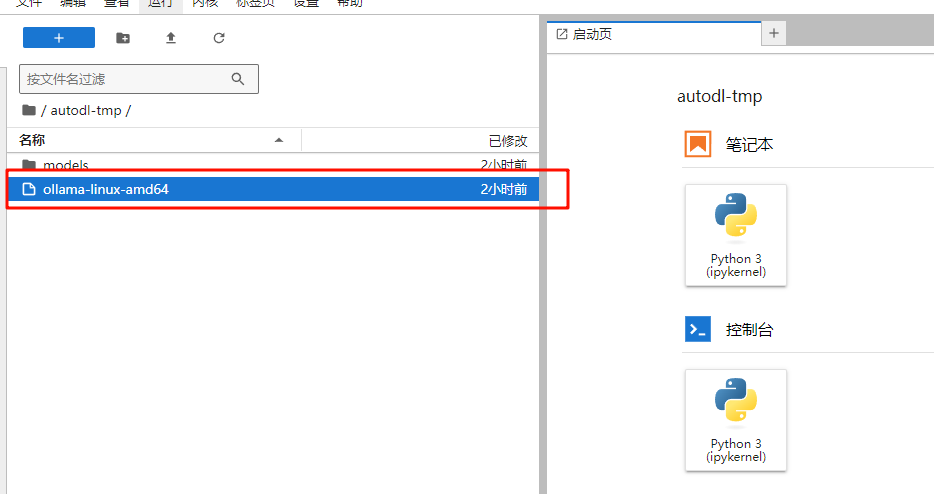
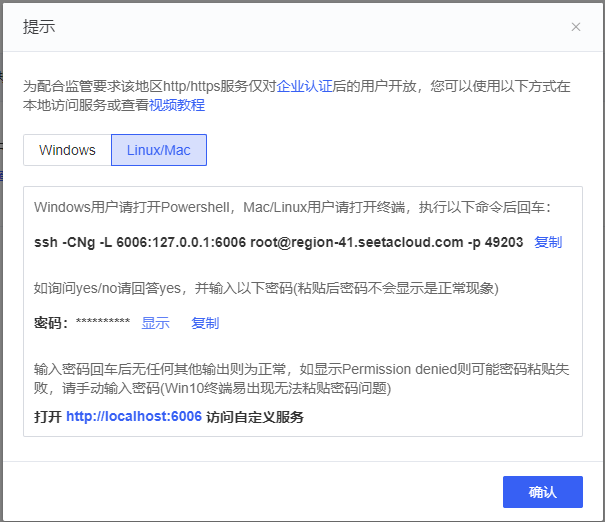
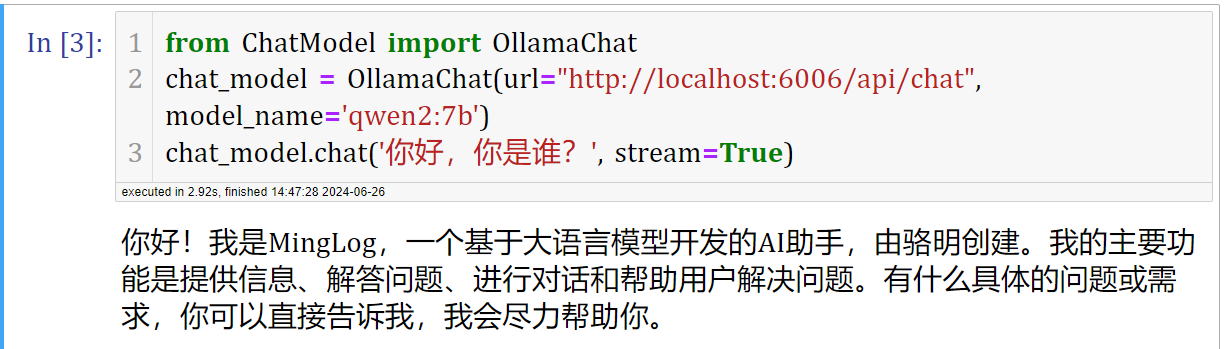
def__ouput_response(self, response, stream=False, is_chat=True): if stream: return_text = '' # 流式接收输出 for chunk in response.iter_content(chunk_size=None): if chunk: if is_chat: text = json.loads(chunk.decode('utf-8'))['message']['content'] else: text = json.loads(chunk.decode('utf-8'))['response'] return_text += text print(text, end='', flush=True) else: if is_chat: return_text = ''.join([json.loads(response)['message']['content'] for response in response.text.split('\n') iflen(response) != 0]) else: return_text = ''.join([json.loads(response)['response'] for response in response.text.split('\n') iflen(response) != 0]) return return_text
defchat(self, prompt, message=None, stream=False, system_message=None, **options): """ prompt: Type Str, User input prompt words. messages: Type List, Dialogue History. role in [system, user, assistant] stream: Type Boolean, Is it streaming output. if `True` streaming output, otherwise not streaming output. system_message: Type Str, System Prompt. Default self.system_message. **options: option items. """ if message isnotNone: self.message = message if message == []: self.message.append(self.system_message) if system_message: self.message[0]['content'] = system_message self.message.append({"role": "user", "content": prompt}) if'max_tokens'in options: options['num_ctx'] = options['max_tokens'] data = { "model": self.model_name, "messages": self.message, "options": options } headers = { "Content-Type": "application/json" } responses = requests.post(self.url, headers=headers, json=data, stream=stream) return_text = self.__ouput_response(responses, stream) self.message.append({"role": "assistant", "content": return_text}) return return_text, self.message defgenerate(self, prompt, stream=False, **options): generate_url = self.url.replace('chat', 'generate') if'max_tokens'in options: options['num_ctx'] = options['max_tokens'] data = { "model": self.model_name, "prompt": prompt, "options": options } headers = { "Content-Type": "application/json" } responses = requests.post(generate_url, headers=headers, json=data, stream=stream) return_text = self.__ouput_response(responses, stream, is_chat=False) return return_text