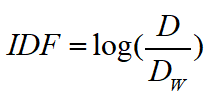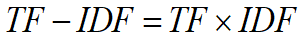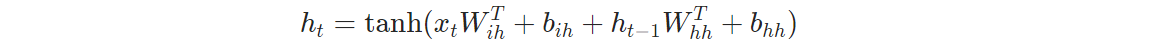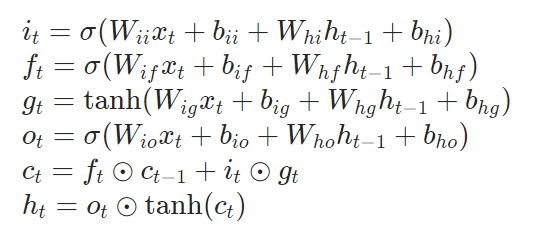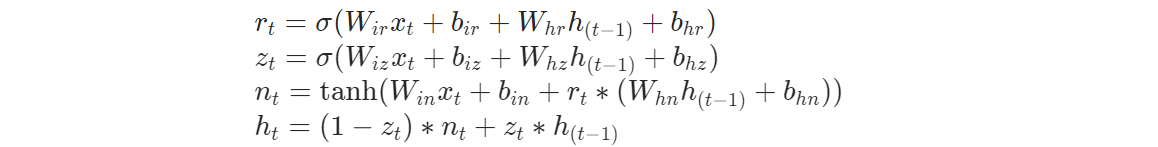文本向量化 文本向量化是将文本数据转化为数值向量的过程,它在自然语言处理(NLP)和机器学习任务中非常重要,有以下几个关键原因:
数学建模: 计算机无法直接处理文本数据,因为文本是符号性的,不是数字。通过将文本向量化,可以将文本数据转化为计算机可以理解和处理的数值形式。这为数学建模、机器学习和深度学习提供了基础。
特征提取: 文本向量化将文本数据中的信息提取出来,并将其表示为特征向量。这些特征向量包含了文本数据的语法和语义信息,使其可用于各种任务,如文本分类、情感分析、主题建模等。
模型输入: 机器学习和深度学习模型通常接受数值输入。将文本向量化为数值向量后,可以将其用作模型的输入。这使得文本可以与其他数据类型(如图像、数值数据)一起用于训练和预测。
计算相似性: 向量化后的文本使得计算文本之间的相似性变得更容易。可以使用向量空间模型(Vector Space Model)来测量文本之间的相似性,这对于信息检索、文档相似度计算和推荐系统非常有用。
维度减少: 向量化可以将高维的文本数据表示转化为低维的数值向量,从而减少数据的复杂性,提高计算效率和模型训练速度。
特定任务需求: 某些NLP任务,如情感分析或文本分类,需要将文本映射为类别或情感极性。文本向量化可以满足这些任务的输入要求。
基于词袋的文本向量表示 基于词袋的表示方法将文本看作是单词的集合,每个单词的出现都被视为独立的事件。
普通词汇表编码 以单个字作为单位进行表示
1 string = '人生苦短,我用Python'
1 2 3 4 5 6 7 def string2num (word_list ): word_set = sorted (set (word_list)) word_dict = {word: index for index, word in enumerate (word_set)} return word_dict
1 2 3 char_dict = string2num(list (string)) string_num = [char_dict[i] for i in string]
1 [6, 8, 11, 10, 12, 7, 9, 0, 5, 4, 1, 3, 2]
这种方式过于暴力,没有考虑任何字与字之间的联系,某些字组成词语后意义可能发生很大变化。例如:条和件,单个看都是一个单位,但是放一起确是一个名词。
分词词汇表编码 分词:是指将连续的字序列按照一定的规范重新组合成词序列的过程。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,分词过程就是找到这样分界符的过程。
jieba:结巴分词是一个基于Python的中文分词库,它使用基于Trie树的算法进行分词。优点是分词准确率高,速度快,支持多种分词模式和自定义词典,适用于各种场景。缺点是不支持英文分词。
NLTK:NLTK是一个基于Python的自然语言处理库,它包含许多用于分词的工具。优点是支持多种语言分词,包括英文和中文,提供丰富的自然语言处理功能,适用于学术研究和工业应用。缺点是需要下载大量数据包,且英文分词效果不如中文分词。
SnowNLP:SnowNLP是一个基于Python的中文分词库,它使用基于词图的算法进行分词。优点是分词准确率高,速度快,支持多种分词模式和自定义词典,适用于各种场景。缺点是不支持英文分词。
THULAC:THULAC是一个基于Python的中文分词工具包,它使用基于隐马尔可夫模型的算法进行分词。优点是分词准确率高,支持多种语言分词,包括英文和中文,适用于各种场景。缺点是需要训练模型,相对较慢。
Gensim是一个基于Python的自然语言处理库,它包含许多用于分词的工具。优点是支持多种语言分词,包括英文和中文,提供丰富的自然语言处理功能,适用于学术研究和工业应用。缺点是需要下载大量数据包。
在这里以jieba分词为例
1 2 3 4 word_list = jieba.lcut(string) word_dict = string2num(word_list) string_num = [word_dict[i] for i in word_list] print (string_num)
[1, 3, 4, 2, 0]
这个结果和前面的结果相比,首先是数据量下降了很多,此时每个数值也不再是单个字,而是由词语构成,丰富了数值包含了语义信息。
One-Hot编码 将每个单词映射为一个长度为词汇表大小的向量,该向量中只有对应单词的索引为1,其他位置为0。
1 2 strings = ['人生苦短,我用Python' , 'Python有丰富的第三方库,这些第三方库使用起来非常方便。' ]
1 2 3 4 5 all_word_list = [] all_word_cut = [jieba.lcut(string) for string in strings] [all_word_list.extend(i) for i in all_word_cut] all_word_dict = string2num(all_word_list) print (f'词袋大小:{len (all_word_dict)} ' )
词袋大小:16
1 2 3 4 5 6 string_onehot = np.zeros(shape=(len (all_word_cut), len (all_word_dict))) for i in range (len (all_word_cut)): for key, value in all_word_dict.items(): if key in all_word_cut[i]: string_onehot[i, value] = 1
1 2 array([[1., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 1.], [1., 1., 1., 0., 1., 1., 0., 1., 1., 1., 1., 0., 1., 1., 1., 1.]] )
但是这样编码有一个问题,没有考虑到词频信息
频数编码 将每个单词映射为一个长度为词汇表大小的向量,该向量中对应单词出现的次数为该元素的值。
1 2 3 4 5 string_frequence = np.zeros(shape=(len (all_word_cut), len (all_word_dict))) for i in range (len (all_word_cut)): for word in all_word_cut[i]: string_frequence[i, all_word_dict[word]] += 1
1 2 array([[1., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 1.], [1., 1., 1., 0., 1., 2., 0., 1., 1., 1., 2., 0., 1., 1., 1., 1.]] )
频数编码虽然考虑了句子中的词频信息,但是没有考虑到句子中不同词语对整个句子的重要性,并不是出现次数越多代表该词在句子中的重要性越大,还需要考虑到词语的特殊性。
TF-IDF模型 将每个单词映射为一个长度为词汇表大小的向量,该向量中对应单词在文本中出现的频率为该元素的值,并对所有文本进行归一化,以消除词汇表大小的影响。
TF:Term frequency即关键词词频,是指一篇文档中关键词出现的频率
IDF:Inverse document frequency指逆向文本频率,是用于衡量关键词权重的指数
D:总文档数
Dw:出现了该单词的文档数
1 2 3 4 5 6 7 8 9 10 n = np.zeros(shape=(len (all_word_cut), len (all_word_dict))) m = np.zeros(shape=(len (all_word_cut), )) d = len (all_word_cut) dw = np.zeros(shape=(len (all_word_cut), len (all_word_dict))) for i in range (len (all_word_cut)): for word in all_word_cut[i]: n[i, all_word_dict[word]] += 1 dw[i, all_word_dict[word]] = sum ([word in word_cut for word_cut in all_word_cut]) m[i] = len (all_word_cut[i])
1 2 3 4 5 string_tfidf = np.zeros(shape=(len (all_word_cut), len (all_word_dict))) for i in range (len (all_word_cut)): for j in range (len (all_word_dict)): if dw[i, j] != 0 : string_tfidf[i, j] = (n[i, j] / m[i]) * np.log(d / dw[i, j])
1 2 3 4 5 6 7 8 array([[0 . , 0 . , 0 . , 0.13862944 , 0 . , 0 . , 0.13862944 , 0 . , 0 . , 0 . , 0 . , 0.13862944 , 0 . , 0 . , 0 . , 0 . ], [0 . , 0.04620981 , 0.04620981 , 0 . , 0.04620981 , 0.09241962 , 0 . , 0.04620981 , 0.04620981 , 0.04620981 , 0.09241962 , 0 . , 0.04620981 , 0.04620981 , 0.04620981 , 0 . ]])
容易受【维数灾难】的困扰,尤其是将其用于 Deep Learning 的一些算法时:词汇表一般都非常大,甚至达到百万级别;
基于词袋模型的表示方法简单易实现,但是无法捕获单词之间的语义关系。例如,”狗”和”猫”在词袋模型中都是独立的单词,无法表示它们之间的”相似”或”对立”关系。【词汇鸿沟】
基于词向量的文本向量表示 基于词向量模型的表示方法将单词看作是具有语义意义的向量,每个单词的向量表示可以捕获单词之间的语义关系。
1 2 3 import torchimport torch.nn as nnimport torch.nn.functional as F
Word2Vec Word2Vec 是一种基于神经网络的词向量表示方法,可以学习单词在上下文中的语义关系。Word2Vec 有两种常用的训练方法:CBOW(Continuous Bag-of-Words)和 Skip-gram。
1 2 3 4 strings = ['人生苦短,我用Python' , 'Python语言之所以这么受欢迎是因为Python有丰富的第三方库和优质的社区' , 'PyTorch是Python的一个第三方库,是一个深度学习框架。' , 'PyTorch的自动求导机制使得其在深度学习建模及求解上非常方便。' ]
CBOW模式 CBOW(Continuous bag of words,连续磁带模型)模式:给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用上下文词汇预测目标词汇
1 2 3 4 5 6 def get_windows (words, context_size ): for i in range (len (words)): center_word = words[i] context_words = words[max (0 , i - context_size):i] + words[i + 1 :i + context_size + 1 ] yield context_words, center_word
1 2 3 4 5 windows_split = get_windows(all_word_cut[1 ], 2 ) print (strings[1 ])print ('------' )for context, target in windows_split: print (context, target)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Python语言之所以这么受欢迎是因为Python有丰富的第三方库和优质的社区 ------ ['有' , '丰富' ] Python['Python' , '丰富' , '的' ] 有['Python' , '有' , '的' , '第三方' ] 丰富['有' , '丰富' , '第三方' , '库' ] 的['丰富' , '的' , '库' , ',' ] 第三方['的' , '第三方' , ',' , '这些' ] 库['第三方' , '库' , '这些' , '第三方' ] ,['库' , ',' , '第三方' , '库' ] 这些[',' , '这些' , '库' , '使用' ] 第三方['这些' , '第三方' , '使用' , '起来' ] 库['第三方' , '库' , '起来' , '非常' ] 使用['库' , '使用' , '非常' , '方便' ] 起来['使用' , '起来' , '方便' , '。' ] 非常['起来' , '非常' , '。' ] 方便['非常' , '方便' ] 。
1 2 3 4 5 6 def word_to_idx (word, all_word_dict ): index = all_word_dict[word] context_var = torch.zeros(size=(len (all_word_dict),)) context_var[index] = 1 return context_var.unsqueeze(0 )
1 word_to_idx('Python' , all_word_dict)
1 tensor ([[1 ., 0 ., 0 ., 0 ., 0 ., 0 ., 0 ., 0 ., 0 ., 0 ., 0 ., 0 ., 0 ., 0 ., 0 ., 0 .]])
1 2 3 4 5 6 7 8 9 10 11 12 class CBOW (nn.Module): def __init__ (self, vocab_size, hidden_dim ): super (CBOW, self).__init__() self.input_layer = nn.Linear(vocab_size, hidden_dim) self.output_layer = nn.Linear(hidden_dim, vocab_size) def forward (self, inputs ): x = torch.sum (inputs, dim=0 ) x = self.input_layer(x) x = self.output_layer(x) return x
1 2 3 4 vocab_size = len (all_word_dict) hidden_dim = 100 w2v_cbow = CBOW(vocab_size, hidden_dim)
1 2 3 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(w2v_cbow.parameters(), lr=0.001 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 device = 'cuda' if torch.cuda.is_available() else 'cpu' w2v_cbow.to(device) w2v_cbow.train() for epoch in range (500 ): for raw_text in all_word_cut: for context, target in get_windows(raw_text, context_window): context_idxs = [word_to_idx(word, all_word_dict) for word in context] context_var = torch.concat(context_idxs, dim=0 ) context_var = context_var.to(device) log_probs = w2v_cbow(context_var) target_var = word_to_idx(target, all_word_dict).to(device) loss = criterion(log_probs.unsqueeze(0 ), target_var) loss.backward() optimizer.step() optimizer.zero_grad() print (f"epoch: {epoch} , loss: {loss} " )
1 2 3 4 5 6 7 8 9 10 11 epoch: 0 , loss: 2.5764620304107666 epoch: 1 , loss: 2.57444167137146 epoch: 2 , loss: 2.572404146194458 epoch: 3 , loss: 2.570350408554077 epoch: 4 , loss: 2.5682802200317383 ...... epoch: 495 , loss: 0.9137914776802063 epoch: 496 , loss: 0.9111965894699097 epoch: 497 , loss: 0.9086090922355652 epoch: 498 , loss: 0.9060297608375549 epoch: 499 , loss: 0.9034573435783386
1 2 3 4 5 w2v_cbow.eval () test_word = 'Python' test_tensor = word_to_idx(test_word, all_word_dict).to(device) w2v_cbow(test_tensor)
1 2 3 tensor ([ 0 .2968 , 0 .0502 , 0 .7586 , -0 .3568 , -0 .4165 , -0 .4488 , 0 .9251 , -0 .4957 , 1 .0127 , -0 .4324 , -0 .7060 , -0 .1554 , -0 .4997 , -0 .6312 , -0 .7200 , 1 .1325 ], grad_fn =<ViewBackward0>)
1 2 3 4 5 6 7 8 context = ['使用' , '起来' , '方便' , '。' ] context_idxs = [word_to_idx(word, all_word_dict) for word in context] context_var = torch.concat(context_idxs, dim=0 ) context_var = context_var.to(device) log_probs = w2v_cbow(context_var) [i for i,j in all_word_dict.items() if log_probs.argmax() == j]
['非常']
skip-gram模式 skip-gram(跳字模型)模式:给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用目标词汇预测上下文词汇
1 2 3 4 5 6 7 8 9 10 11 class SKIP_GRAM (nn.Module): def __init__ (self, vocab_size, hidden_dim ): super (SKIP_GRAM, self).__init__() self.input_layer = nn.Linear(vocab_size, hidden_dim) self.output_layer = nn.Linear(hidden_dim, vocab_size) def forward (self, x ): x = self.input_layer(x) x = self.output_layer(x) return x
1 2 3 4 vocab_size = len (all_word_dict) hidden_dim = 100 w2v_skip_gram = SKIP_GRAM(vocab_size, hidden_dim)
1 2 3 criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(w2v_skip_gram.parameters(), lr=0.001 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 device = 'cuda' if torch.cuda.is_available() else 'cpu' w2v_skip_gram.to(device) w2v_skip_gram.train() for epoch in range (500 ): for raw_text in all_word_cut: for context, target in get_windows(raw_text, context_window): context_idxs = [word_to_idx(word, all_word_dict) for word in context] context_var = torch.concat(context_idxs, dim=0 ).sum (dim=0 ).to(device) target_var = word_to_idx(target, all_word_dict).to(device) log_probs = w2v_skip_gram(target_var) loss = criterion(log_probs, context_var.unsqueeze(0 )) loss.backward() optimizer.step() optimizer.zero_grad() print (f"epoch: {epoch} , loss: {loss} " )
1 2 3 4 5 6 7 8 9 10 11 epoch: 0 , loss: 5.623337745666504 epoch: 1 , loss: 5.621850490570068 epoch: 2 , loss: 5.620423316955566 epoch: 3 , loss: 5.619052886962891 epoch: 4 , loss: 5.617734909057617 ...... epoch: 495 , loss: 2.9915518760681152 epoch: 496 , loss: 2.986611843109131 epoch: 497 , loss: 2.981687307357788 epoch: 498 , loss: 2.976778507232666 epoch: 499 , loss: 2.971884250640869
1 2 3 4 5 w2v_skip_gram.eval () test_word = 'Python' test_tensor = word_to_idx(test_word, all_word_dict).to(device) w2v_skip_gram(test_tensor)
1 2 3 tensor ([[-0 .0652 , -1 .2278 , 1 .2972 , -0 .4503 , -0 .3250 , 0 .1369 , 0 .8928 , -0 .8017 , 1 .1140 , 0 .0765 , 0 .1401 , -0 .3290 , -0 .8854 , -0 .2785 , -0 .7324 , 1 .4444 ]], grad_fn =<AddmmBackward0>)
1 2 3 4 5 6 7 target = '第三方' target_var = word_to_idx(target, all_word_dict).to(device) log_probs = w2v_skip_gram(target_var) indices = torch.topk(log_probs, 2 *context_window+1 ).indices[0 ] [i for i,j in all_word_dict.items() if j in indices]
['丰富', '使用', '库', '的', ',']
Word2Embedding 1 2 3 vocab_size = len (all_word_dict) embedding_dim = 50 embedding_model = nn.Embedding(vocab_size, embedding_dim)
embedding模型一般是嵌入到神经网络模型内部使用,其中的参数也需要随着模型的训练进行优化,所以在这里仅演示如何使用embedding模型进行推理,例如:可以把embedding层引入到CBOW和Skip-gram中进行拟合。
1 2 3 4 embedding_model.eval () test_word = '地铁' test_tensor = word_to_idx(test_word, all_word_dict).to(torch.long) embedding_model(test_tensor)
1 2 3 4 5 6 7 8 tensor([[[-1 .5885, 0.6640, 0.4271, ..., -0 .0109, 0.7542, -0 .0802], [-1 .5885, 0.6640, 0.4271, ..., -0 .0109, 0.7542, -0 .0802], [-1 .5885, 0.6640, 0.4271, ..., -0 .0109, 0.7542, -0 .0802], ..., [-1 .5885, 0.6640, 0.4271, ..., -0 .0109, 0.7542, -0 .0802], [-1 .5885, 0.6640, 0.4271, ..., -0 .0109, 0.7542, -0 .0802], [-1 .5885, 0.6640, 0.4271, ..., -0 .0109, 0.7542, -0 .0802]]], grad_fn=<EmbeddingBackward0>)
n-gram特征 n-gram特征 :给定一段文本序列,其中n个词或字的相邻共现特征 即n-gram特征,常用的n-gram特征是bi-gram和tri-gram特征,分别对应n为2和3
相邻共现特征 是一种用于分析文本数据的特征工程方法,通常用于自然语言处理(NLP)任务。它涉及到识别在文本中相邻出现的词语或短语 ,并将它们转化为特征 以用于机器学习模型或文本分析任务。以下是相邻共现特征的基本概念和工作原理:
相邻共现 :相邻共现是指在文本中出现在彼此附近的词语或短语 。这种共现通常表示这些词语之间存在某种关联或语义关系 。例如,在文本中,词语 “狗” 和 “喜欢” 可能会经常一起出现,因为人们通常说 “狗喜欢玩”。滑动窗口 :要创建相邻共现特征,通常会使用一个滑动窗口来遍历文本。滑动窗口是一个固定大小的窗口,在文本中从左到右移动,每次移动一个词或短语的距离。在窗口内的词语或短语被视为相邻共现 。特征提取 :一旦确定了相邻共现的窗口大小,就可以开始提取特征。最简单的方法是创建一个二进制特征(存在与否) 来表示某个特定的词语或短语是否在窗口内出现。也可以使用其他方式来编码共现信息,例如计数共现次数或使用词嵌入(Word Embeddings) 来表示共现的语义关系。应用领域 :相邻共现特征常用于多种NLP任务,包括文本分类、情感分析、信息检索、命名实体识别等。它们有助于捕捉文本中的上下文信息和语义关联,从而提高模型的性能。
总之,相邻共现特征是一种用于分析文本数据的特征工程方法,通过识别并利用文本中词语或短语的相邻出现关系,可以提供有关文本语境和语义信息的有用特征,用于改善自然语言处理任务的性能。
N-gram特征的使用可以帮助模型捕捉文本中的局部结构和上下文信息。例如,N-gram可以用于文本分类、情感分析、语言建模、信息检索和机器翻译等任务。N-gram模型的一个常见应用是n-gram语言模型,用于预测一个给定上下文中的下一个单词。
1 2 3 4 5 6 7 def create_ngram_set (input_list, ngram_range=2 ): n_gram_features = [] for i in range (len (input_list) - ngram_range +1 ): this_feature = ' ' .join(input_list[i: i+ngram_range]) if this_feature not in n_gram_features: n_gram_features.append(this_feature) return n_gram_features
1 create_ngram_set(all_word_cut[1 ], 2 )
['Python 有',
'有 丰富',
'丰富 的',
'的 第三方',
'第三方 库',
'库 ,',
', 这些',
'这些 第三方',
'库 使用',
'使用 起来',
'起来 非常',
'非常 方便',
'方便 。']
1 2 3 from torchtext.data.utils import ngrams_iteratorlist (ngrams_iterator(all_word_cut[0 ], 2 ))[len (all_word_cut[0 ]):]
1 2 3 4 5 6 7 8 9 10 11 12 13 ['商业秘密 的', '的 秘密性', '秘密性 那', '那 是', '是 维系', '维系 其', '其 商业价值', '商业价值 和', '和 垄断', '垄断 地位', '地位 的', '的 前提条件', '前提条件 之一']
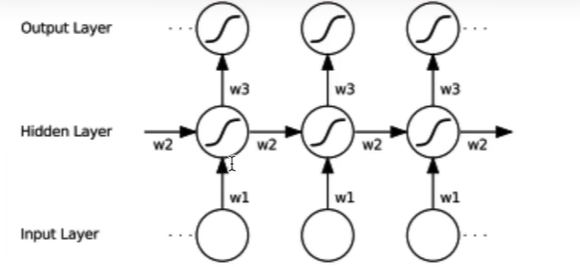
递归神经网络 RNN原理及手写复现 调用Pytorch中的类 单向,单层
1 2 3 4 import torchimport numpy as npimport torch.nn as nnimport torch.nn.functional as F
1 2 3 4 5 6 7 input_size = 4 hidden_size = 3 num_layers = 1 single_rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True )
1 2 3 4 5 batch_size = 10 sequence_length = 2 feature_size = 4 input_tensor = torch.randn(batch_size, sequence_length, feature_size)
1 2 3 4 5 6 7 8 single_h_prev = torch.randn(num_layers, batch_size, hidden_size) output, hn = single_rnn(input_tensor, single_h_prev) print (output.shape) print (hn.shape)
torch.Size([10, 2, 3])
torch.Size([1, 10, 3])
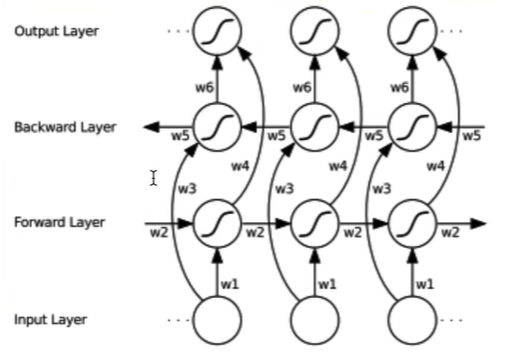
双向,单层
1 2 single_bi_rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True , bidirectional=True )
1 2 3 4 5 single_bi_h_prev = torch.randn(2 *num_layers, batch_size, hidden_size) bi_output, bi_hn = single_bi_rnn(input_tensor, single_bi_h_prev) print (bi_output.shape) print (bi_hn.shape)
torch.Size([10, 2, 6])
torch.Size([2, 10, 3])
手动编写RNN架构
单向,rnn_forward 1 2 3 4 5 6 7 8 9 10 def rnn_forward (input_tensor, weight_ih, weight_hh, bias_ih, bias_hh, h_prev ): batch_size, sequence_length, feature_size = input_tensor.shape num_layers, batch_size, hidden_size = h_prev.shape h_out = torch.zeros(batch_size, sequence_length, hidden_size) for t in range (sequence_length): x = input_tensor[:, t, :] h_prev = torch.tanh(x@weight_ih.t() + bias_ih + h_prev@weight_hh.t() + bias_hh) h_out[:, t, :] = h_prev return h_out, h_prev
1 2 3 4 5 6 7 weight_ih = single_rnn.weight_ih_l0 weight_hh = single_rnn.weight_hh_l0 bias_ih = single_rnn.bias_ih_l0 bias_hh = single_rnn.bias_hh_l0 h_out, h_n = rnn_forward(input_tensor, weight_ih, weight_hh, bias_ih, bias_hh, single_h_prev)
1 2 torch.allclose(hn, h_n)
True
结果一致
双向,bi_rnn_forward 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def bi_rnn_forward (input_tensor, weight_ih, weight_hh, bias_ih, bias_hh, weight_ih_reverse, weight_hh_reverse, bias_ih_reverse, bias_hh_reverse, h_prev ): batch_size, sequence_length, feature_size = input_tensor.shape bi_num_layers, batch_size, hidden_size = h_prev.shape num_layers = bi_num_layers / 2 h_out = torch.zeros(batch_size, sequence_length, 2 *hidden_size) forward_output = rnn_forward(input_tensor, weight_ih, weight_hh, bias_ih, bias_hh, h_prev[0 :1 ])[0 ] backward_output = rnn_forward(torch.flip(input_tensor, [1 ]), weight_ih_reverse, weight_hh_reverse, bias_ih_reverse, bias_hh_reverse, h_prev[1 :2 ])[0 ] backward_output = torch.flip(backward_output, [1 ]) output = torch.cat([forward_output, backward_output], 2 ) h_n_forward = forward_output[:, -1 , :].unsqueeze(0 ) h_n_backward = backward_output[:, -1 , :].unsqueeze(0 ) return output, torch.cat([h_n_forward, h_n_backward], 0 )
1 2 3 4 5 6 7 8 9 10 11 12 weight_ih = single_bi_rnn.weight_ih_l0 weight_hh = single_bi_rnn.weight_hh_l0 bias_ih = single_bi_rnn.bias_ih_l0 bias_hh = single_bi_rnn.bias_hh_l0 weight_ih_reverse = single_bi_rnn.weight_ih_l0_reverse weight_hh_reverse = single_bi_rnn.weight_hh_l0_reverse bias_ih_reverse = single_bi_rnn.bias_ih_l0_reverse bias_hh_reverse = single_bi_rnn.bias_hh_l0_reverse h_out2, h_n2 = bi_rnn_forward(input_tensor, weight_ih, weight_hh, bias_ih, bias_hh, weight_ih_reverse, weight_hh_reverse, bias_ih_reverse, bias_hh_reverse, single_bi_h_prev)
1 2 torch.allclose(h_out2, bi_output, 1e-3 )
True
返回结果为True,说明结果很接近
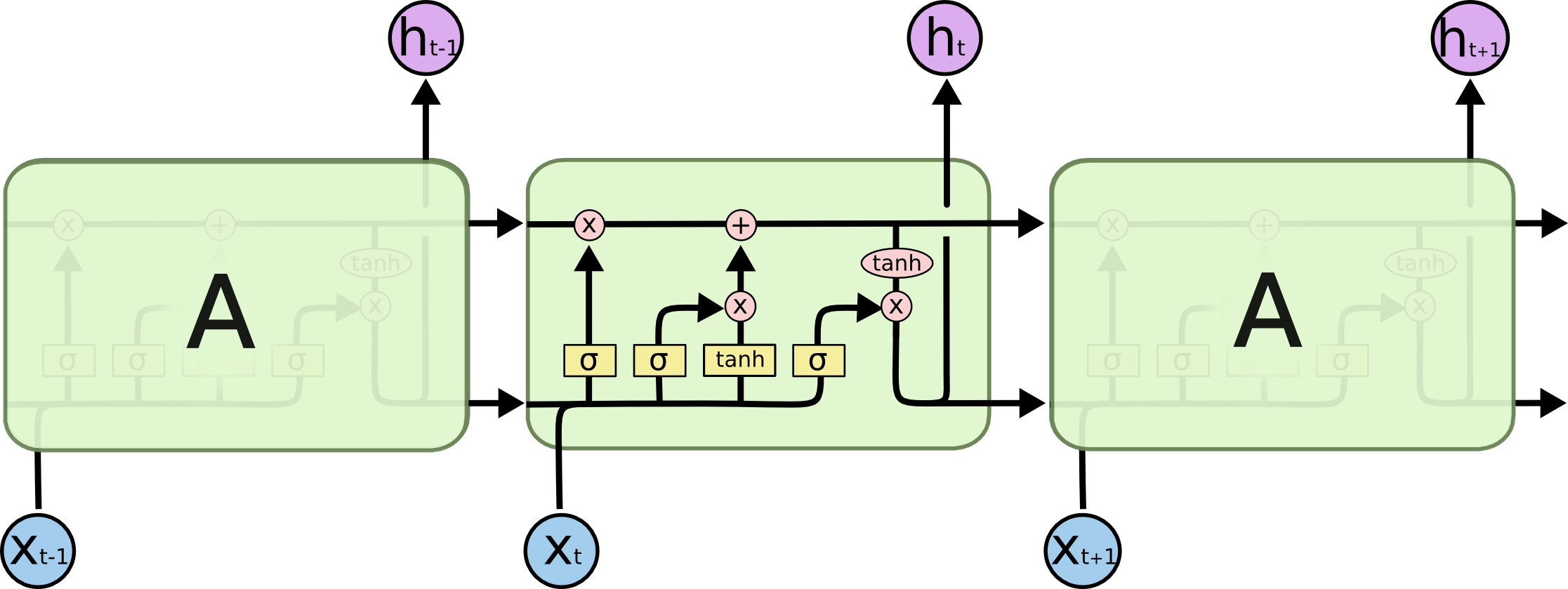
LSTM原理及手写实现
调用Pytorch官方API 1 2 3 4 import torchimport numpy as npimport torch.nn as nnimport torch.nn.functional as F
1 2 3 4 5 6 7 input_size = 4 hidden_size = 3 num_layers = 1 single_lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True )
1 2 3 4 5 batch_size = 10 sequence_length = 5 feature_size = 4 input_tensor = torch.randn(batch_size, sequence_length, feature_size)
1 2 3 4 5 6 7 8 9 10 single_h_prev = torch.randn(num_layers, batch_size, hidden_size) single_c_prev = torch.randn(num_layers, batch_size, hidden_size) output, (hn, cn) = single_lstm(input_tensor, (single_h_prev, single_c_prev)) print (output.shape) print (hn.shape) print (cn.shape)
torch.Size([10, 5, 3])
torch.Size([1, 10, 3])
torch.Size([1, 10, 3])
1 2 3 for k, v in single_lstm.named_parameters(): print (k,v.shape)
weight_ih_l0 torch.Size([12, 4])
weight_hh_l0 torch.Size([12, 3])
bias_ih_l0 torch.Size([12])
bias_hh_l0 torch.Size([12])
手写实现 https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html#torch.nn.LSTM
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def lstm_forward (input_tensor, initial_states, w_ih,w_hh, b_ih, b_hh ): prev_h, prev_c = initial_states batch_size, sequence_length, feature_size = input_tensor.shape num_layers, batch_size, hidden_size = prev_h.shape output_h = torch.zeros(batch_size, sequence_length, hidden_size) for t in range (sequence_length): x = input_tensor[:, t,:] w_times = x @ w_ih.t() + b_ih + prev_h @ w_hh.t() + b_hh i_t = torch.sigmoid(w_times[:, :, :hidden_size]) f_t = torch.sigmoid(w_times[:, :, hidden_size: 2 *hidden_size]) g_t = torch.tanh(w_times[:, :, 2 *hidden_size: 3 *hidden_size]) o_t = torch.sigmoid(w_times[:, :, 3 *hidden_size: 4 *hidden_size]) prev_c = f_t * prev_c + i_t * g_t prev_h = o_t * torch.tanh(prev_c) output_h[:, t, :] = prev_h return output_h, (prev_h, prev_c)
1 2 3 4 5 6 7 w_ih = single_lstm.weight_ih_l0 w_hh = single_lstm.weight_hh_l0 b_ih = single_lstm.bias_ih_l0 b_hh = single_lstm.bias_hh_l0 output2, (hn2, cn2) = lstm_forward(input_tensor, (single_h_prev, single_c_prev), w_ih,w_hh, b_ih, b_hh)
1 torch.allclose(output, output2, 1e-3 )
True
可以看到与直接调用torch得到的结果相同
GRU原理及手写实现
从公式可以看出,在hidden_layer相同的情况下,GRU的参数量是LSTM的3/4倍,验证如下所示。并且在GRU中是没有单元状态(Ct)这个参数的。
1 2 3 4 5 6 7 8 lstm_layer = nn.LSTM(3 , 5 ) gru_layer = nn.GRU(3 , 5 ) lstm_parms = sum (p.numel() for p in lstm_layer.parameters()) gru_parms = sum (p.numel() for p in gru_layer.parameters()) print (f"lstm参数量:{lstm_parms} " )print (f"gru参数量:{gru_parms} " )
lstm参数量:200
gru参数量:150
调用Pytorch官方API 1 2 3 4 5 6 7 input_size = 4 hidden_size = 3 num_layers = 1 single_gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True )
1 2 3 4 5 batch_size = 10 sequence_length = 5 feature_size = 4 input_tensor = torch.randn(batch_size, sequence_length, feature_size)
1 2 3 4 5 6 7 8 single_h_prev = torch.randn(num_layers, batch_size, hidden_size) output, hn = single_gru(input_tensor, single_h_prev) print (output.shape) print (hn.shape)
torch.Size([10, 5, 3])
torch.Size([1, 10, 3])
1 2 3 for k, v in single_gru.named_parameters(): print (k,v.shape)
weight_ih_l0 torch.Size([9, 4])
weight_hh_l0 torch.Size([9, 3])
bias_ih_l0 torch.Size([9])
bias_hh_l0 torch.Size([9])
手写实现 https://pytorch.org/docs/stable/generated/torch.nn.GRU.html#torch.nn.GRU
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def gru_forward (input_tensor, prev_h, w_ih,w_hh, b_ih, b_hh ): batch_size, sequence_length, feature_size = input_tensor.shape num_layers, batch_size, hidden_size = prev_h.shape output_h = torch.zeros(batch_size, sequence_length, hidden_size) for t in range (sequence_length): x = input_tensor[:, t,:] w_times = x @ w_ih.t() + b_ih w_times2 = prev_h @ w_hh.t() + b_hh r_t = torch.sigmoid(w_times[:, :hidden_size] + w_times2[:, :, :hidden_size]) z_t = torch.sigmoid(w_times[:, hidden_size: 2 *hidden_size] + w_times2[:, :, hidden_size: 2 *hidden_size]) n_t = torch.tanh(w_times[:, 2 *hidden_size: 3 *hidden_size] + r_t * w_times2[:, :, 2 *hidden_size: 3 *hidden_size]) prev_h = (1 - z_t) * n_t + z_t * prev_h output_h[:, t, :] = prev_h return output_h, prev_h
1 2 3 4 5 6 7 w_ih = single_gru.weight_ih_l0 w_hh = single_gru.weight_hh_l0 b_ih = single_gru.bias_ih_l0 b_hh = single_gru.bias_hh_l0 output2, hn2 = gru_forward(input_tensor, single_h_prev, w_ih,w_hh, b_ih, b_hh)
1 torch.allclose(output, output2, 1e-3 )
True
可以看到结果与Pytorch官方API一致
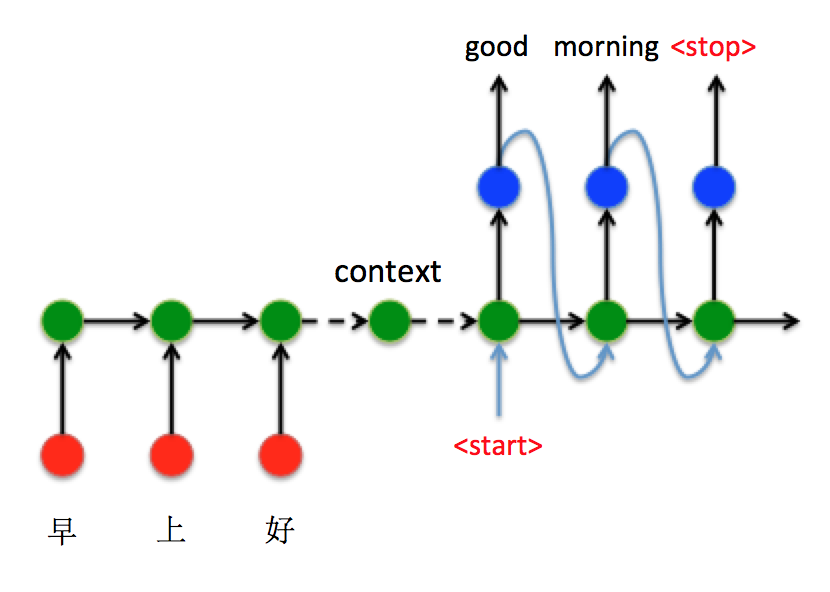
Attention机制与Seq2Seq模型
接下来以机器翻译为例,看看如何通过Seq2Seq结构把中文“早上好”翻译成英文“Good morning”:
将“早上好”通过Encoder编码,并将最后$t=3$时刻的隐藏层状态$h_3$作为语义向量。
以语义向量为Decoder的$h_0$状态,同时在$t=3$时刻输入<start>特殊标识符,开始解码。之后不断的将前一时刻输出作为下一时刻输入进行解码,直到输出<stop>特殊标识符结束。
1 2 3 4 import torchimport numpy as npimport torch.nn as nnimport torch.nn.functional as F
基本的RNN-Based Seq2Seq模型 Encoder 将输入字符转化为语义向量
1 2 3 4 5 6 7 8 9 10 11 12 13 class Seq2SeqEncoder (nn.Module): """ 实现基于LSTM的编码器,也可以是其他类型的,如CNN、TransformerEncoder""" def __init__ (self, embedding_dim, hidden_size, source_vocab_size ): super (Seq2SeqEncoder, self).__init__() self.lstm_layer = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size, batch_first=True ) self.embedding_table = nn.Embedding(source_vocab_size, embedding_dim) def forward (self, input_ids ): input_sequence = self.embedding_table(input_ids) output_states, final_state = self.lstm_layer(input_sequence) return output_states, final_state
Decoder 使用Encoder中的语义向量和输入值进行预测,自回归预测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 class Seq2SeqDecoder (nn.Module): def __init__ (self, embedding_dim, hidden_size, target_vocab_size, start_id, end_id ): super (Seq2SeqDecoder, self).__init__() self.lstm_cell = nn.LSTMCell(embedding_dim, hidden_size) self.proj_layer = nn.Linear(hidden_size, target_vocab_size) self.target_vocab_size = target_vocab_size self.embedding_table = nn.Embedding(target_vocab_size, embedding_dim) self.start_id = start_id self.end_id = end_id def forward (self, shifted_target_ids, final_encoder ): h_t, c_t = final_encoder h_t = h_t.squeeze(0 ) c_t = c_t.squeeze(0 ) shifted_target = self.embedding_table(shifted_target_ids) bs, target_length, embedding_dim = shifted_target.shape logits = torch.zeros(bs, target_length, self.target_vocab_size) for t in range (target_length): decoder_input_t = shifted_target[:, t, :] h_t, c_t = self.lstm_cell(decoder_input_t, (h_t, c_t)) logits[:, t, :] = self.proj_layer(h_t) return logits def inference (self, final_encoder ): h_t, c_t = final_encoder h_t = h_t.squeeze(0 ) c_t = c_t.squeeze(0 ) batch_size = h_t.shape[0 ] target_id = self.start_id target_id = torch.stack([target_id]*batch_size, 0 ) print (target_id.shape) result = [] while True : decoder_input_t = self.embedding_table(target_id) decoder_input_t = decoder_input_t.squeeze(1 ) h_t, c_t = self.lstm_cell(decoder_input_t, (h_t, c_t)) logits = self.proj_layer(h_t) result.append(target_id) if torch.any (target_id == self.end_id): print ('stop decoding!' ) break predicted_ids = torch.stack(result, dim=0 ) return predicted_ids
Seq2Seq Model拼接 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Seq2SeqModel (nn.Module): def __init__ (self, embedding_dim, hidden_size, source_vocab_size, target_vocab_size, start_id, end_id ): super (Seq2SeqModel, self).__init__() self.encoder = Seq2SeqEncoder(embedding_dim, hidden_size, source_vocab_size) self.decoder = Seq2SeqDecoder(embedding_dim, hidden_size, target_vocab_size, start_id, end_id) def forward (self, input_sequence_ids, shifted_target_ids ): encoder_states, final_encoder = self.encoder(input_sequence_ids) logits = self.decoder(shifted_target_ids, final_encoder) return logits def inference (self, input_sequence_ids ): encoder_states, final_encoder = self.encoder(input_sequence_ids) predicted_ids = self.decoder.inference(final_encoder) return predicted_ids
Main函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 source_length = 3 target_length = 4 embedding_dim = 8 hidden_size = 16 bs = 2 start_id = end_id = torch.zeros([1 , ], dtype=torch.long) source_vocab_size = 100 target_vocab_size = 100 input_sequence_ids = torch.randint(source_vocab_size, size=(bs, source_length)).to(torch.int32) target_ids = torch.randint(target_vocab_size, size=(bs, target_length)) target_ids = torch.cat((target_ids, end_id*torch.ones(bs, 1 )), dim=1 ).to(torch.int32) shifted_target_ids = torch.cat((start_id*torch.ones(bs, 1 ), target_ids[:, 0 :-1 ]), dim=1 ).to(torch.int32) model = Seq2SeqModel(embedding_dim, hidden_size, source_vocab_size, target_vocab_size, start_id, end_id) logits = model(input_sequence_ids, shifted_target_ids) print (logits.shape)
torch.Size([2, 5, 100])
1 2 model.inference(input_sequence_ids)
torch.Size([2, 1])
stop decoding!
tensor([[[0],
[0]]])
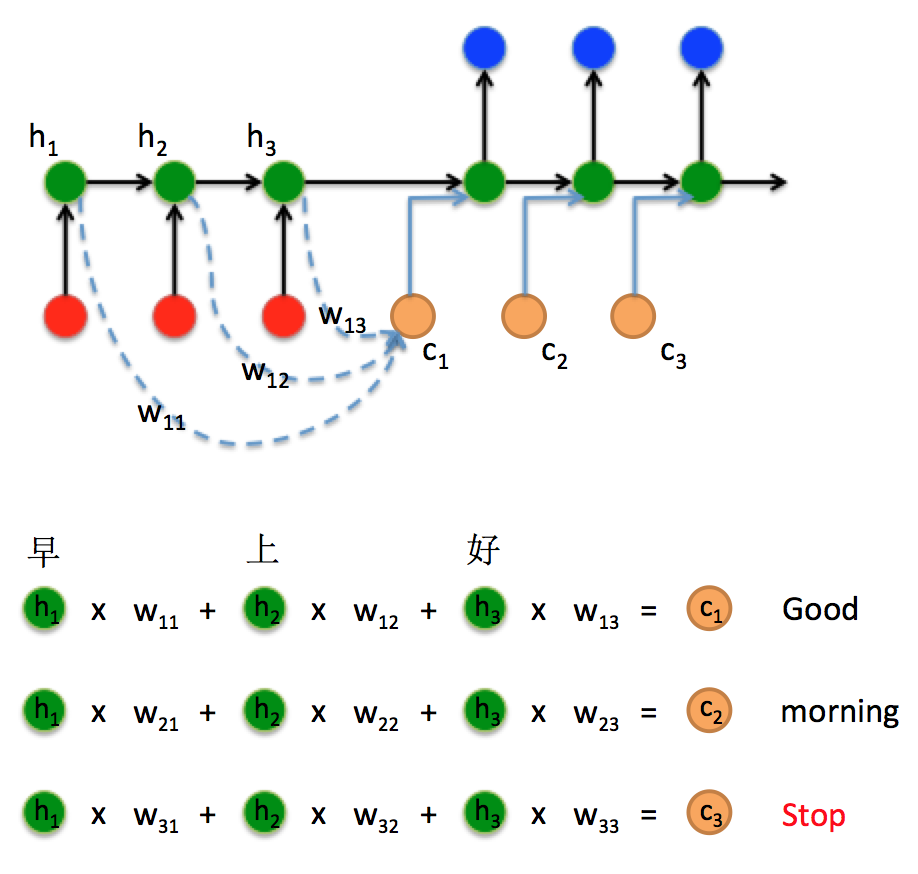
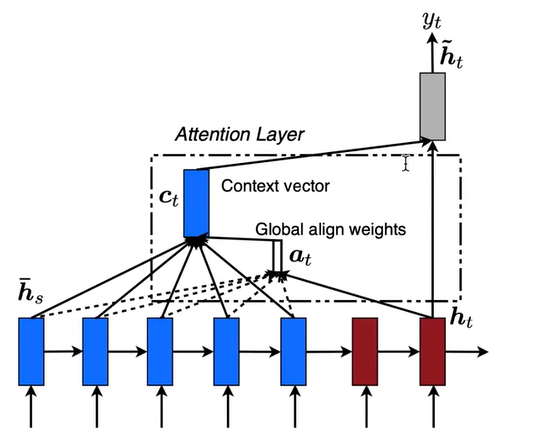
Attention注意力机制 基础注意力机制 在Seq2Seq结构中,encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由Decoder解码。由于context包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个Context可能存不下那么多信息,就会造成精度的下降。除此之外,如果按照上述方式实现,只用到了编码器的最后一个隐藏层状态,信息利用率低下。
所以如果要改进Seq2Seq结构,最好的切入角度就是:利用Encoder所有隐藏层状态$h_t$解决Context长度限制问题。
这里的权重如何去选取呢?有很多方法可以选择,例如:在《Effective Approaches to Attention-based Neural Machine Translation》 Luong等人 提出了3个方法
其中:
dot方法是在编码器和解码器hidden_dim一致的情况下使用。
general方法是在编码器和解码器hidden_dim不一致的情况下使用,使用$W_a$向量将结果维度进行统一。例如:假设Encoder的hidden_dim为hidden_dim1,Decoder的hidden_dim为hidden_dim2,那么$W_a$的维度大小为(hidden_dim1, hidden_dim2)。
concat: 方法略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class BaseAttentionMechanism (nn.Module): """ 实现dot-product的Attention """ def __init__ (self ): super (Seq2SeqAttentionMechanism, self).__init__() def forward (self, decoder_state_t, encoder_states ): bs, source_length, hidden_size = encoder_states.shape decoder_state_t = decoder_state_t.unsqueeze(1 ) decoder_state_t = torch.tile(decoder_state_t, dims=(1 , source_length, 1 )) score = torch.sum (decoder_state_t * encoder_states, dim=-1 ) attn_prob = F.softmax(score, dim=-1 ) context = torch.sum (attn_prob.unsqueeze(-1 ) * encoder_states, 1 ) return attn_prob, context
但是这种注意力机制权重的计算依赖Decoder端的输入,并且计算机制过于简单,无法通过“学习”自动调节注意力矩阵。在一些更困难的自然语言处理任务(例如:机器翻译。)上表现效果不佳。
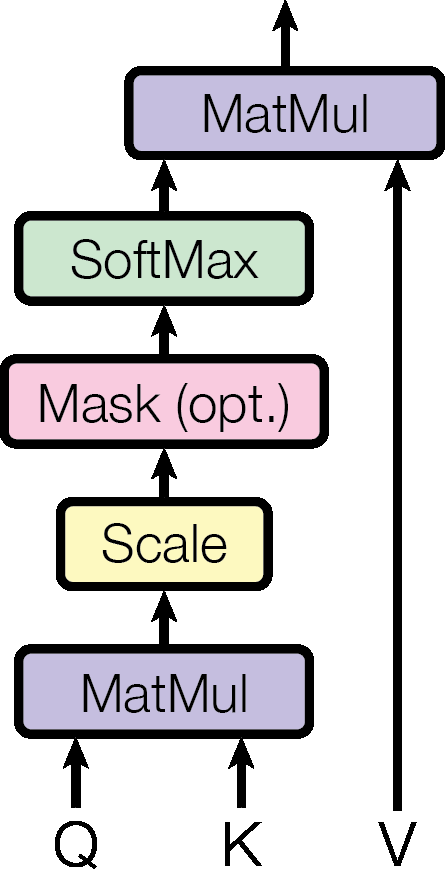
(单头)自注意力机制 在2017年由Google发表的文章《Attention Is All You Need》 ,在文章中提出了著名的Transformer架构,也是现在大模型的基座。在Transformer架构中引入了一种特殊的注意力机制,叫做自注意力机制 (self-Attention Mechanism)。
自注意力机制使用的计算公式如下所示:
在自注意力机制中,注意力矩阵是由公式$\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right)$进行计算的,在计算的过程中会使用全连接层引入注意力权重,使得在训练过程中可以让网络自己去学习应该关注的区域。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class SelfAttentionMechanism (nn.Module): """ 实现自注意力Attention """ def __init__ (self, input_size, hidden_size ): super (SelfAttentionMechanism, self).__init__() self.query_layer = torch.nn.Linear(input_size, hidden_size) self.key_layer = torch.nn.Linear(input_size, hidden_size) self.value_layer = torch.nn.Linear(input_size, hidden_size) self.hidden_size = hidden_size def forward (self, x ): Q = self.query_layer(x) K = self.key_layer(x) V = self.key_layer(x) score = torch.bmm(Q, K.transpose(-2 , -1 )) / np.sqrt(self.hidden_size) attn_prob = F.softmax(score, -1 ) context = torch.bmm(attn_prob, V) return attn_prob, context
1 2 3 4 5 6 7 8 9 10 11 12 13 input_size = 10 hidden_size = 10 batch_size = 2 squence_length = 5 input_tensor = torch.randn(size=(batch_size, squence_length, input_size)) self_attention_layer = SelfAttentionMechanism(input_size, hidden_size) attn_prob, context = self_attention_layer(input_tensor) print (context.shape)
torch.Size([2, 5, 10])
在实际使用中,为了简化模型,一般会设置一个通用的尺寸$d_{model}$【这里就包括前面使用的input_size, hidden_size等等】,来保证输入和输出张量尺寸大小不变。
多头注意力机制,顾名思义就是将单头注意力机制进行类似于在卷积神经网络中使用多个卷积核进行卷积的方式进行堆叠,然后在最后进行拼接输出。
这里需要注意,如果要想保证注意力机制的输入和输出大小不变,则需要满足$d_{model} = d_v * h$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class MultiSelfAttentionMechanism (nn.Module): """ 实现多头自注意力Attention """ def __init__ (self, num_attention_heads, input_size, hidden_size ): super (MultiSelfAttentionMechanism, self).__init__() if hidden_size % num_attention_heads: raise ValueError( "the hidden size %d is not a multiple of the number of attention heads %d" % (hidden_size, num_attention_heads) ) self.num_attention_heads = num_attention_heads self.attention_head_size = int (hidden_size / num_attention_heads) self.self_attention_layers = [SelfAttentionMechanism(input_size, self.attention_head_size) for _ in range (num_attention_heads)] self.fc = torch.nn.Linear(hidden_size, hidden_size) def forward (self, x ): contexts = [self_attention_layer(x)[1 ] for self_attention_layer in self.self_attention_layers] x = torch.concat(contexts, -1 ) context = self.fc(x) return context
1 2 3 4 5 6 7 8 9 10 11 12 13 14 input_size = 10 hidden_size = 10 batch_size = 2 squence_length = 5 num_attention_heads = 5 input_tensor = torch.randn(size=(batch_size, squence_length, input_size)) multi_self_attention_layer = MultiSelfAttentionMechanism(num_attention_heads, input_size, hidden_size) context = multi_self_attention_layer(input_tensor) print (context.shape)
torch.Size([2, 5, 10])
引入Attention的Seq2Seq模型 Encoder 1 2 3 4 5 6 7 8 9 10 11 12 13 class Seq2SeqEncoder (nn.Module): """ 实现基于LSTM的编码器,也可以是其他类型的,如CNN、TransformerEncoder""" def __init__ (self, embedding_dim, hidden_size, source_vocab_size ): super (Seq2SeqEncoder, self).__init__() self.lstm_layer = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size, batch_first=True ) self.embedding_table = nn.Embedding(source_vocab_size, embedding_dim) def forward (self, input_ids ): input_sequence = self.embedding_table(input_ids) output_states, (final_h, final_c) = self.lstm_layer(input_sequence) return output_states, (final_h, final_c)
Attention 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Seq2SeqAttentionMechanism (nn.Module): """ 实现dot-product的Attention """ def __init__ (self ): super (Seq2SeqAttentionMechanism, self).__init__() def forward (self, decoder_state_t, encoder_states ): bs, source_length, hidden_size = encoder_states.shape decoder_state_t = decoder_state_t.unsqueeze(1 ) decoder_state_t = torch.tile(decoder_state_t, dims=(1 , source_length, 1 )) score = torch.sum (decoder_state_t * encoder_states, dim=-1 ) attn_prob = F.softmax(score, dim=-1 ) context = torch.sum (attn_prob.unsqueeze(-1 ) * encoder_states, 1 ) return attn_prob, context
Decoder
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 class Seq2SeqDecoder (nn.Module): def __init__ (self, embedding_dim, hidden_size, target_vocab_size, start_id, end_id ): super (Seq2SeqDecoder, self).__init__() self.lstm_cell = nn.LSTMCell(embedding_dim, hidden_size) self.proj_layer = nn.Linear(hidden_size*2 , target_vocab_size) self.attention_mechanism = Seq2SeqAttentionMechanism() self.target_vocab_size = target_vocab_size self.embedding_table = nn.Embedding(target_vocab_size, embedding_dim) self.start_id = start_id self.end_id = end_id def forward (self, shifted_target_ids, encoder_states, final_encoder ): h_t, c_t = final_encoder h_t = h_t.squeeze(0 ) c_t = c_t.squeeze(0 ) shifted_target = self.embedding_table(shifted_target_ids) bs, target_length, embedding_dim = shifted_target.shape bs, source_length, hidden_size = encoder_states.shape logits = torch.zeros(bs, target_length, self.target_vocab_size) probs = torch.zeros(bs, target_length, source_length) for t in range (target_length): decoder_input_t = shifted_target[:, t, :] h_t, c_t = self.lstm_cell(decoder_input_t, (h_t, c_t)) attn_prob, context = self.attention_mechanism(h_t, encoder_states) decoder_output = torch.cat((context, h_t), -1 ) logits[:, t, :] = self.proj_layer(decoder_output) probs[:, t, :] = attn_prob return probs, logits def inference (self, encoder_states, final_encoder ): h_t, c_t = final_encoder h_t = h_t.squeeze(0 ) c_t = c_t.squeeze(0 ) batch_size = h_t.shape[0 ] target_id = self.start_id target_id = torch.stack([target_id]*batch_size, 0 ) result = [] while True : decoder_input_t = self.embedding_table(target_id) decoder_input_t = decoder_input_t.squeeze(1 ) h_t, c_t = self.lstm_cell(decoder_input_t, (h_t, c_t)) attn_prob, context = self.attention_mechanism(h_t, encoder_states) decoder_output = torch.cat((context, h_t), -1 ) logits = self.proj_layer(decoder_output) result.append(target_id) if torch.any (target_id == self.end_id): print ('stop decoding!' ) break predicted_ids = torch.stack(result, dim=0 ) return predicted_ids
Seq2Seq Model拼接 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Seq2SeqModel (nn.Module): def __init__ (self, embedding_dim, hidden_size, source_vocab_size, target_vocab_size, start_id, end_id ): super (Seq2SeqModel, self).__init__() self.encoder = Seq2SeqEncoder(embedding_dim, hidden_size, source_vocab_size) self.decoder = Seq2SeqDecoder(embedding_dim, hidden_size, target_vocab_size, start_id, end_id) def forward (self, input_sequence_ids, shifted_target_ids ): encoder_states, final_encoder = self.encoder(input_sequence_ids) probs, logits = self.decoder(shifted_target_ids, encoder_states, final_encoder) return probs, logits def inference (self, input_sequence_ids ): encoder_states, final_encoder = self.encoder(input_sequence_ids) predicted_ids = self.decoder.inference(encoder_states, final_encoder) return predicted_ids
Main函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 source_length = 3 target_length = 4 embedding_dim = 8 hidden_size = 16 bs = 2 start_id = end_id = torch.zeros([1 ], dtype=torch.long) source_vocab_size = 100 target_vocab_size = 100 input_sequence_ids = torch.randint(source_vocab_size, size=(bs, source_length)).to(torch.int32) target_ids = torch.randint(target_vocab_size, size=(bs, target_length)) target_ids = torch.cat((target_ids, end_id*torch.ones(bs, 1 )), dim=1 ).to(torch.int32) shifted_target_ids = torch.cat((start_id*torch.ones(bs, 1 ), target_ids[:, 0 :-1 ]), dim=1 ).to(torch.int32) model = Seq2SeqModel(embedding_dim, hidden_size, source_vocab_size, target_vocab_size, start_id, end_id) probs, logits = model(input_sequence_ids, shifted_target_ids) print (probs.shape)print (logits.shape)
torch.Size([2, 5, 3])
torch.Size([2, 5, 100])
1 2 model.inference(input_sequence_ids)
stop decoding!
tensor([[[0],
[0]]])