常用Dockerfile命令汇总。
Docker-1-Docker基础
docker简介
什么是docker
Docker 最初是dotCloud公司创始人Solomon Hykes在法国期间发起的一个公司内部项目,它是基于 dotCloud公司多年云服务技术的一次革新,并于2013年3月以 Apache 2.0 授权协议开源,主要项目代码在 GitHub上进行维护。Docker 项目后来还加入了Linux基金会,并成立推动开放容器联盟(OCI)。
Docker使用 Google 公司推出的Go语言进行开发实现,基于Linux 内核的cgroup,namespace,以及OverlayFS 类的Union FS 等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术。由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。最初实现是基于LXC,从 0.7版本以后开始去除 LXC,转而使用自行开发的libcontainer,从 1.11开始,则进一步演进为使用runC 和containerd。
Docker在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容器的创建和维护。使得 Docker 技术比虚拟机技术更为轻便、快捷。
使用百度网盘不占用额外硬盘空间同步文件
Hadoop-19-Hive4分区表、分桶表与函数
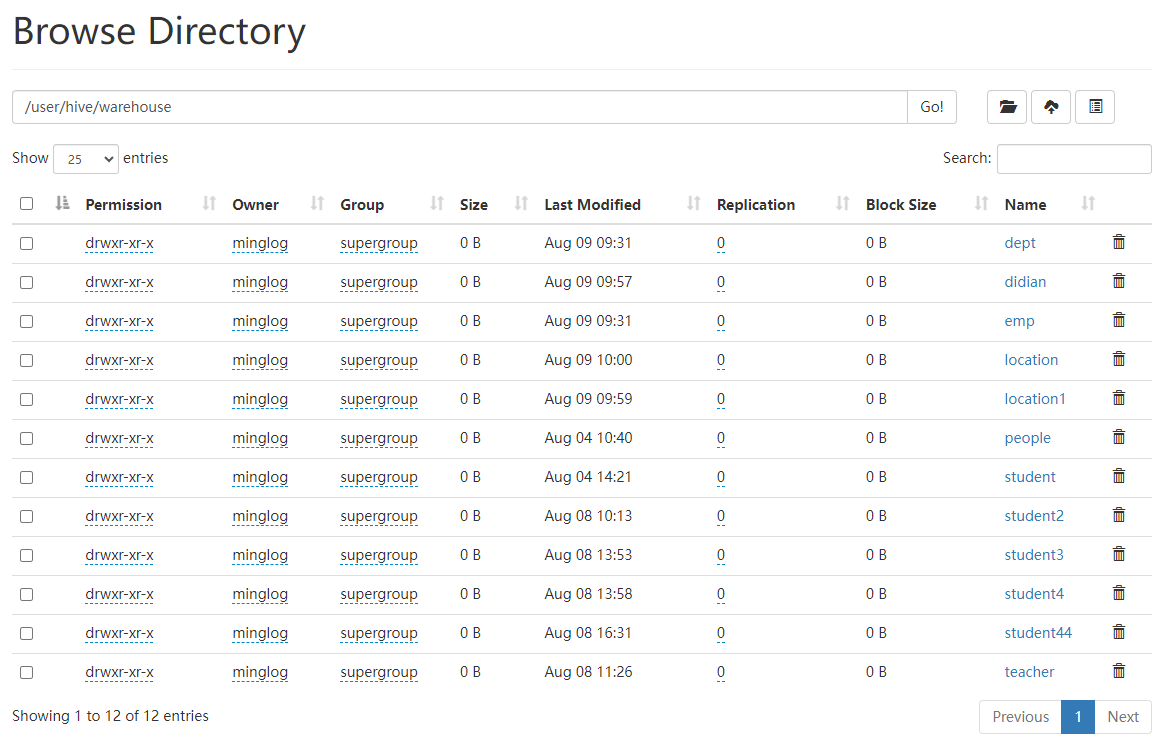
Hadoop-18-Hive3查询操作
基础语法及执行顺序
查询语句语法
1 | SELECT [ALL | DISTINCT] select_expr, select_expr, ... |
书写次序和执行次序
| 顺序 | 书写次序 | 书写次序说明 | 执行次序 | 执行次序说明 |
|---|---|---|---|---|
| 1 | select |
查询 | from |
先执行表与表直接的关系 |
| 2 | from |
先执行表与表直接的关系 | on |
|
| 3 | join on |
join |
||
| 4 | where |
where |
过滤 | |
| 5 | group by |
分组 | group by |
分组 |
| 6 | having |
分组后再过滤 | having |
分组后再过滤 |
| 7 | distribute bycluster by |
4个by | select |
查询 |
| 8 | sort by |
distinct |
去重 | |
| 9 | order by |
distribute by cluster by |
4个by | |
| 10 | limit |
限制输出的行数 | sort by |
|
| 11 | union/union all |
合并 | order by |
|
| 12 | limit |
限制输出的行数 | ||
| 13 | union /union all |
合并 |
Hadoop-17-Hive2
Hive数据类型
在Hive种数据类型分为两种:
- 基本数据类型
- 集合数据类型
基本数据类型
| Hive数据类型 | Java数据类型 | 长度 | 例子 |
|---|---|---|---|
TINYINT |
byte |
1byte有符号整数 |
20 |
SMALINT |
short |
2byte有符号整数 |
20 |
| INT | int |
4byte有符号整数 |
20 |
| BIGINT | long |
8byte有符号整数 |
20 |
BOOLEAN |
boolean |
布尔类型,true或者false |
TRUE FALSE |
FLOAT |
float |
单精度浮点数 | 3.14159 |
| DOUBLE | double |
双精度浮点数 | 3.14159 |
| STRING | string |
字符系列。可以指定字符集。 可以使用单引号或者双引号。 |
Hello world! |
TIMESTAMP |
时间类型 | ||
BINARY |
字节数组 |
对于
Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
Hadoop-16-Hive1
Hadoop-15-HA
HA概述
- 所谓
HA(High Availablity),即高可用(7 * 24小时不中断服务)。 - 实现高可用最关键的策略是消除单点故障。
HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。 NameNode主要在以下两个方面影响HDFS集群NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启。NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用。
HDFS HA功能通过配置多个NameNodes(Active/Standby)实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
Hadoop-14-Zookeeper
Zookeeper入门
概述
Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。官网链接
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。