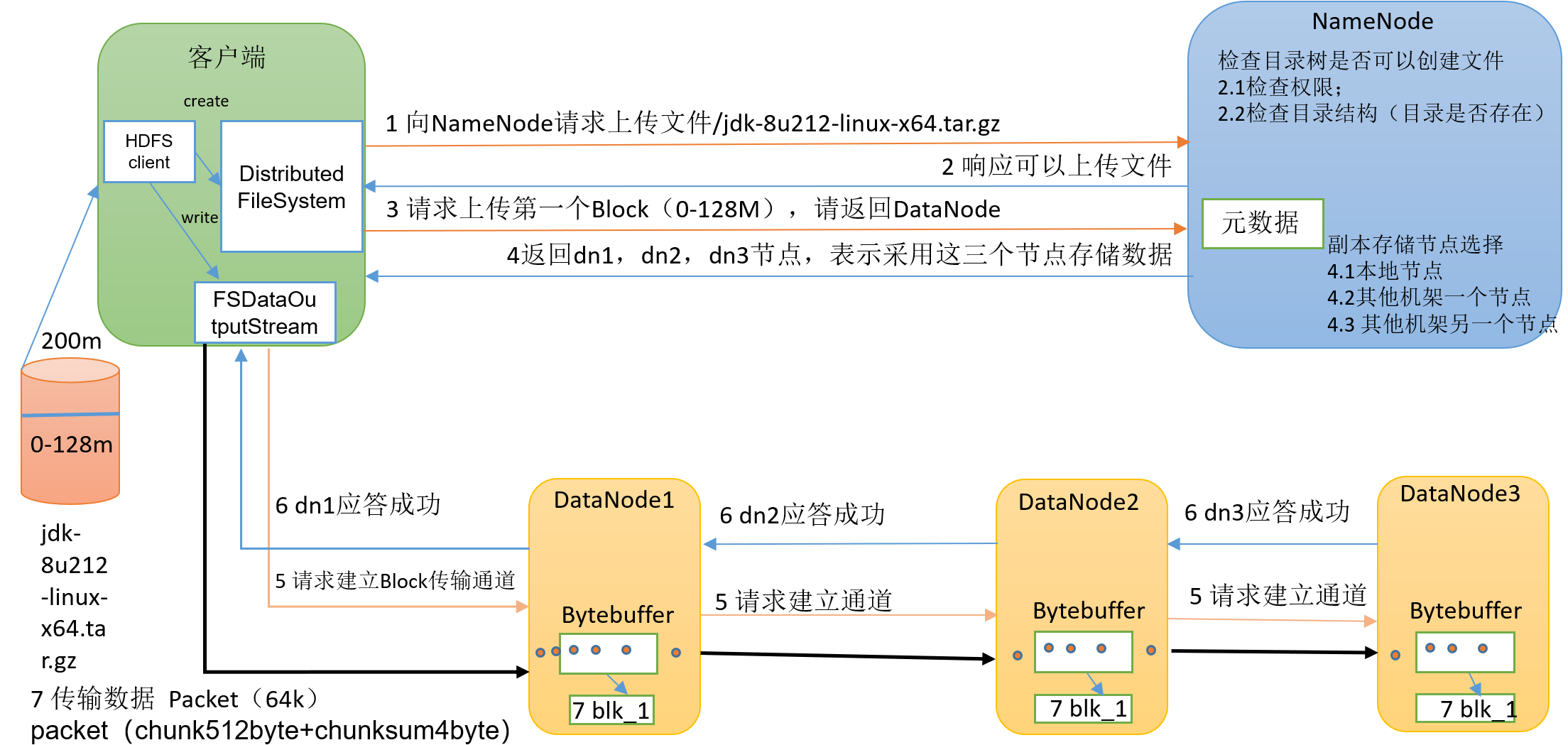
什么是YARN
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
YARN基础架构
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。
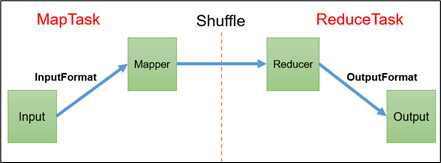
Input ---> InputFormat --->Mapper--->Shuffle--->Reducer--->OutputFormat--->Output
Map阶段---->Reduce阶段
Map阶段 ---> Shuffle(Map后半段+Reduce前半段)--->Reduce阶段
MapTask:map ---> sort
1 | mapPhase = getProgress().addPhase("map", 0.667f); |
ReduceTask : copy ---> sort ---> reduce
1 | copyPhase = getProgress().addPhase("copy"); |
Hadoop的运行模式包括:本地模式、伪分布式以及完全分布式
参考此文章按照以下内容去克隆3个节点。
192.168.128.102,hostname:hadoop102192.168.128.103,hostname:hadoop103192.168.128.104,hostname:hadoop104